 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Readiness of Scientific Data for a Fair and Transparent Use in Machine Learning
Jan 18, 2024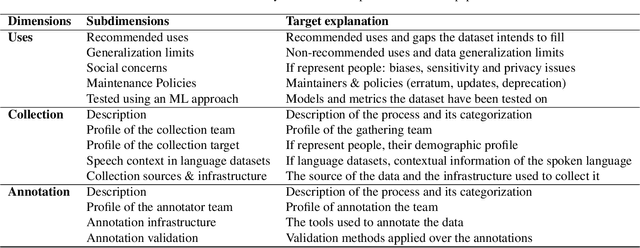
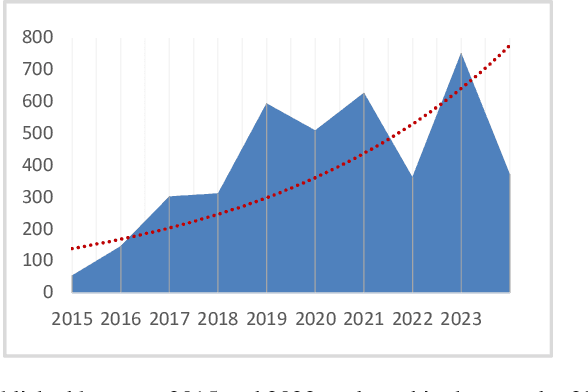
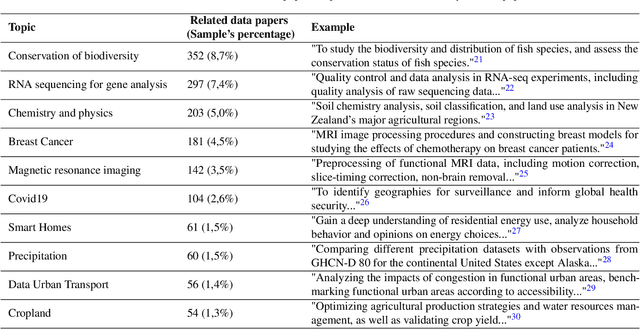
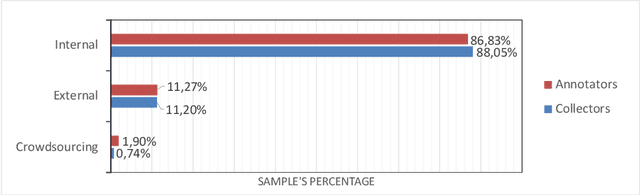
To ensure the fairness and trustworthiness of machine learning (ML) systems, recent legislative initiatives and relevant research in the ML community have pointed out the need to document the data used to train ML models. Besides, data-sharing practices in many scientific domains have evolved in recent years for reproducibility purposes. In this sense, the adoption of these practices by academic institutions has encouraged researchers to publish their data and technical documentation in peer-reviewed publications such as data papers. In this study, we analyze how this scientific data documentation meets the needs of the ML community and regulatory bodies for its use in ML technologies. We examine a sample of 4041 data papers of different domains, assessing their completeness and coverage of the requested dimensions, and trends in recent years, putting special emphasis on the most and least documented dimensions. As a result, we propose a set of recommendation guidelines for data creators and scientific data publishers to increase their data's preparedness for its transparent and fairer use in ML technologies.
A domain-specific language for describing machine learning datasets
Jul 08, 2022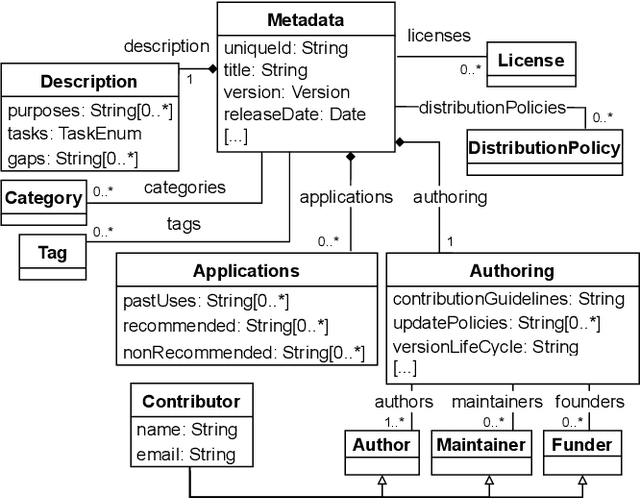
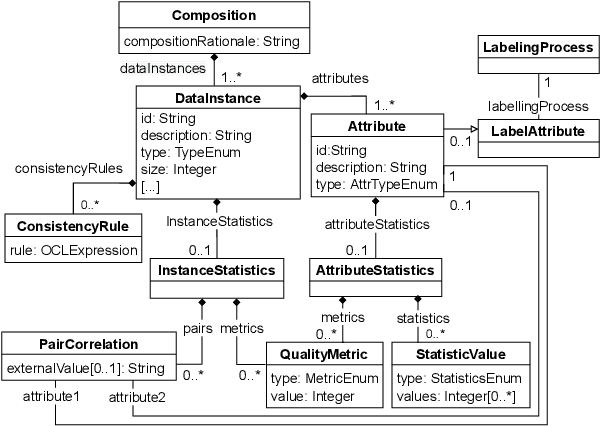
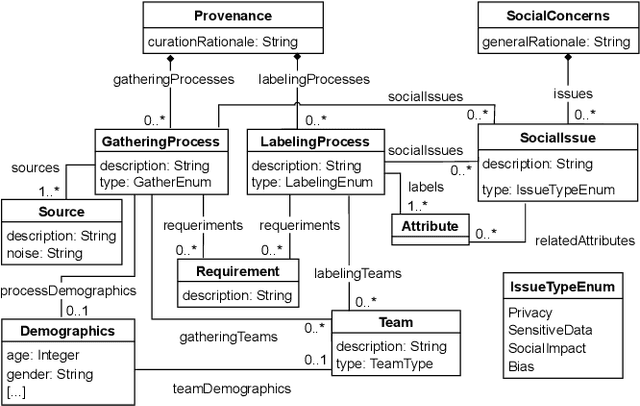
Datasets play a central role in the training and evaluation of machine learning (ML) models. But they are also the root cause of many undesired model behaviors, such as biased predictions. To overcome this situation, the ML community is proposing a data-centric cultural shift where data issues are given the attention they deserve, and more standard practices around the gathering and processing of datasets start to be discussed and established. So far, these proposals are mostly high-level guidelines described in natural language and, as such, they are difficult to formalize and apply to particular datasets. In this sense, and inspired by these proposals, we define a new domain-specific language (DSL) to precisely describe machine learning datasets in terms of their structure, data provenance, and social concerns. We believe this DSL will facilitate any ML initiative to leverage and benefit from this data-centric shift in ML (e.g., selecting the most appropriate dataset for a new project or better replicating other ML results). The DSL is implemented as a Visual Studio Code plugin, and it has been published under an open source license.