 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA domain-specific language for describing machine learning datasets
Paper and Code
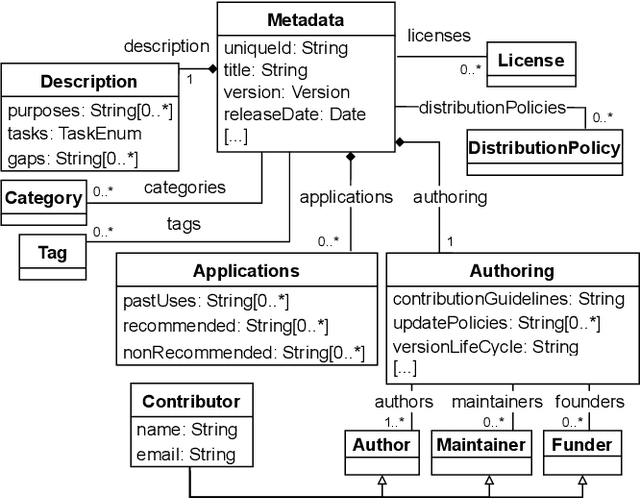
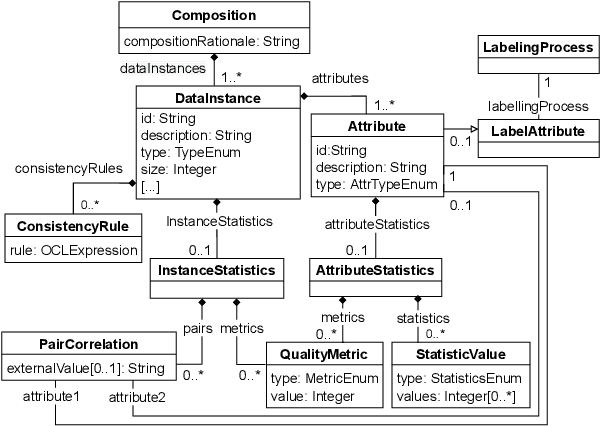
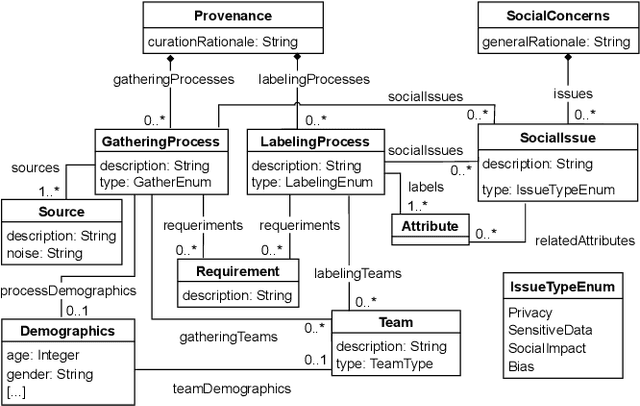
Datasets play a central role in the training and evaluation of machine learning (ML) models. But they are also the root cause of many undesired model behaviors, such as biased predictions. To overcome this situation, the ML community is proposing a data-centric cultural shift where data issues are given the attention they deserve, and more standard practices around the gathering and processing of datasets start to be discussed and established. So far, these proposals are mostly high-level guidelines described in natural language and, as such, they are difficult to formalize and apply to particular datasets. In this sense, and inspired by these proposals, we define a new domain-specific language (DSL) to precisely describe machine learning datasets in terms of their structure, data provenance, and social concerns. We believe this DSL will facilitate any ML initiative to leverage and benefit from this data-centric shift in ML (e.g., selecting the most appropriate dataset for a new project or better replicating other ML results). The DSL is implemented as a Visual Studio Code plugin, and it has been published under an open source license.