 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Readiness of Scientific Data for a Fair and Transparent Use in Machine Learning
Paper and Code
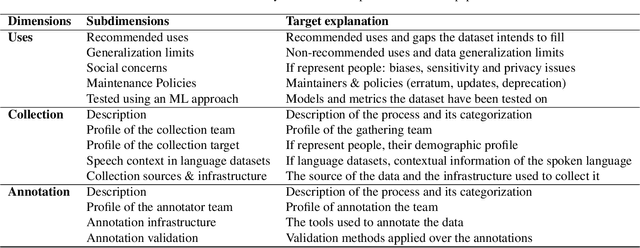
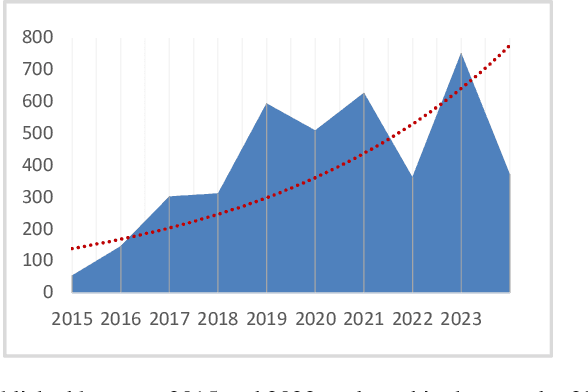
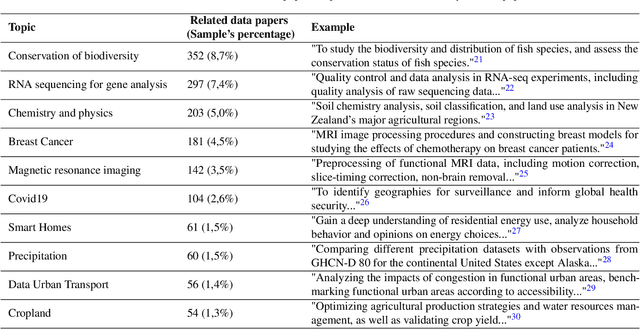
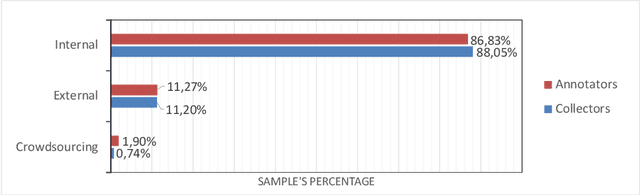
To ensure the fairness and trustworthiness of machine learning (ML) systems, recent legislative initiatives and relevant research in the ML community have pointed out the need to document the data used to train ML models. Besides, data-sharing practices in many scientific domains have evolved in recent years for reproducibility purposes. In this sense, the adoption of these practices by academic institutions has encouraged researchers to publish their data and technical documentation in peer-reviewed publications such as data papers. In this study, we analyze how this scientific data documentation meets the needs of the ML community and regulatory bodies for its use in ML technologies. We examine a sample of 4041 data papers of different domains, assessing their completeness and coverage of the requested dimensions, and trends in recent years, putting special emphasis on the most and least documented dimensions. As a result, we propose a set of recommendation guidelines for data creators and scientific data publishers to increase their data's preparedness for its transparent and fairer use in ML technologies.