 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore at Stake: How Payoff and Language Shape LLM Agent Strategies in Cooperation Dilemmas
Jan 27, 2026As LLMs increasingly act as autonomous agents in interactive and multi-agent settings, understanding their strategic behavior is critical for safety, coordination, and AI-driven social and economic systems. We investigate how payoff magnitude and linguistic context shape LLM strategies in repeated social dilemmas, using a payoff-scaled Prisoner's Dilemma to isolate sensitivity to incentive strength. Across models and languages, we observe consistent behavioral patterns, including incentive-sensitive conditional strategies and cross-linguistic divergence. To interpret these dynamics, we train supervised classifiers on canonical repeated-game strategies and apply them to LLM decisions, revealing systematic, model- and language-dependent behavioral intentions, with linguistic framing sometimes matching or exceeding architectural effects. Our results provide a unified framework for auditing LLMs as strategic agents and highlight cooperation biases with direct implications for AI governance and multi-agent system design.
When Numbers Start Talking: Implicit Numerical Coordination Among LLM-Based Agents
Jan 07, 2026LLMs-based agents increasingly operate in multi-agent environments where strategic interaction and coordination are required. While existing work has largely focused on individual agents or on interacting agents sharing explicit communication, less is known about how interacting agents coordinate implicitly. In particular, agents may engage in covert communication, relying on indirect or non-linguistic signals embedded in their actions rather than on explicit messages. This paper presents a game-theoretic study of covert communication in LLM-driven multi-agent systems. We analyse interactions across four canonical game-theoretic settings under different communication regimes, including explicit, restricted, and absent communication. Considering heterogeneous agent personalities and both one-shot and repeated games, we characterise when covert signals emerge and how they shape coordination and strategic outcomes.
Assessing High-Risk AI Systems under the EU AI Act: From Legal Requirements to Technical Verification
Dec 22, 2025The implementation of the AI Act requires practical mechanisms to verify compliance with legal obligations, yet concrete and operational mappings from high-level requirements to verifiable assessment activities remain limited, contributing to uneven readiness across Member States. This paper presents a structured mapping that translates high-level AI Act requirements into concrete, implementable verification activities applicable across the AI lifecycle. The mapping is derived through a systematic process in which legal requirements are decomposed into operational sub-requirements and grounded in authoritative standards and recognised practices. From this basis, verification activities are identified and characterised along two dimensions: the type of verification performed and the lifecycle target to which it applies. By making explicit the link between regulatory intent and technical and organisational assurance practices, the proposed mapping reduces interpretive uncertainty and provides a reusable reference for consistent, technology-agnostic compliance verification under the AI Act.
Understanding LLM Agent Behaviours via Game Theory: Strategy Recognition, Biases and Multi-Agent Dynamics
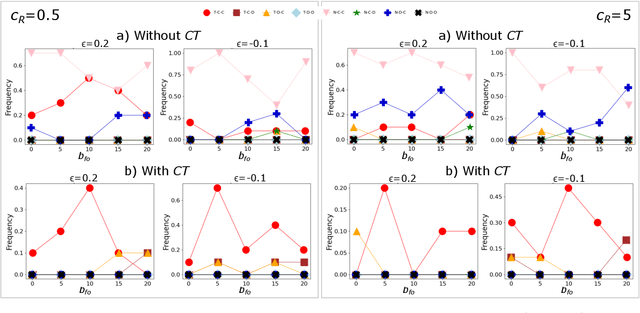
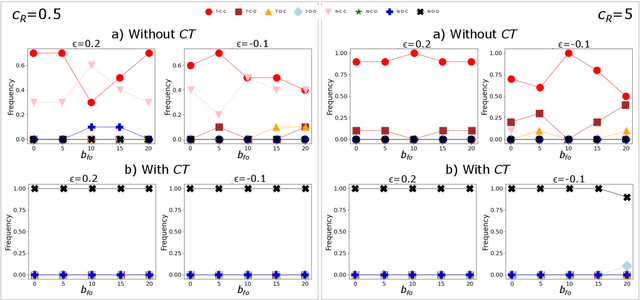
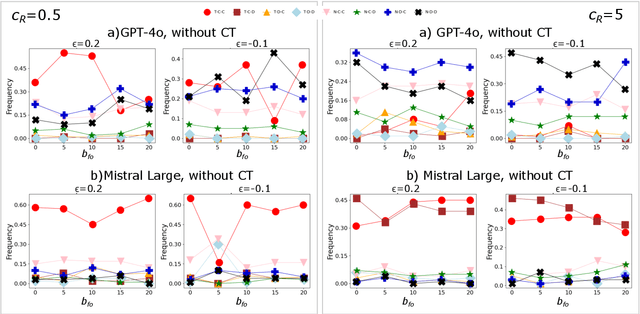
Dec 11, 2025As Large Language Models (LLMs) increasingly operate as autonomous decision-makers in interactive and multi-agent systems and human societies, understanding their strategic behaviour has profound implications for safety, coordination, and the design of AI-driven social and economic infrastructures. Assessing such behaviour requires methods that capture not only what LLMs output, but the underlying intentions that guide their decisions. In this work, we extend the FAIRGAME framework to systematically evaluate LLM behaviour in repeated social dilemmas through two complementary advances: a payoff-scaled Prisoners Dilemma isolating sensitivity to incentive magnitude, and an integrated multi-agent Public Goods Game with dynamic payoffs and multi-agent histories. These environments reveal consistent behavioural signatures across models and languages, including incentive-sensitive cooperation, cross-linguistic divergence and end-game alignment toward defection. To interpret these patterns, we train traditional supervised classification models on canonical repeated-game strategies and apply them to FAIRGAME trajectories, showing that LLMs exhibit systematic, model- and language-dependent behavioural intentions, with linguistic framing at times exerting effects as strong as architectural differences. Together, these findings provide a unified methodological foundation for auditing LLMs as strategic agents and reveal systematic cooperation biases with direct implications for AI governance, collective decision-making, and the design of safe multi-agent systems.
FAIRGAME: a Framework for AI Agents Bias Recognition using Game Theory
Apr 22, 2025Letting AI agents interact in multi-agent applications adds a layer of complexity to the interpretability and prediction of AI outcomes, with profound implications for their trustworthy adoption in research and society. Game theory offers powerful models to capture and interpret strategic interaction among agents, but requires the support of reproducible, standardized and user-friendly IT frameworks to enable comparison and interpretation of results. To this end, we present FAIRGAME, a Framework for AI Agents Bias Recognition using Game Theory. We describe its implementation and usage, and we employ it to uncover biased outcomes in popular games among AI agents, depending on the employed Large Language Model (LLM) and used language, as well as on the personality trait or strategic knowledge of the agents. Overall, FAIRGAME allows users to reliably and easily simulate their desired games and scenarios and compare the results across simulation campaigns and with game-theoretic predictions, enabling the systematic discovery of biases, the anticipation of emerging behavior out of strategic interplays, and empowering further research into strategic decision-making using LLM agents.
Mind the Language Gap: Automated and Augmented Evaluation of Bias in LLMs for High- and Low-Resource Languages
Apr 19, 2025Large Language Models (LLMs) have exhibited impressive natural language processing capabilities but often perpetuate social biases inherent in their training data. To address this, we introduce MultiLingual Augmented Bias Testing (MLA-BiTe), a framework that improves prior bias evaluation methods by enabling systematic multilingual bias testing. MLA-BiTe leverages automated translation and paraphrasing techniques to support comprehensive assessments across diverse linguistic settings. In this study, we evaluate the effectiveness of MLA-BiTe by testing four state-of-the-art LLMs in six languages -- including two low-resource languages -- focusing on seven sensitive categories of discrimination.
Do LLMs trust AI regulation? Emerging behaviour of game-theoretic LLM agents
Apr 11, 2025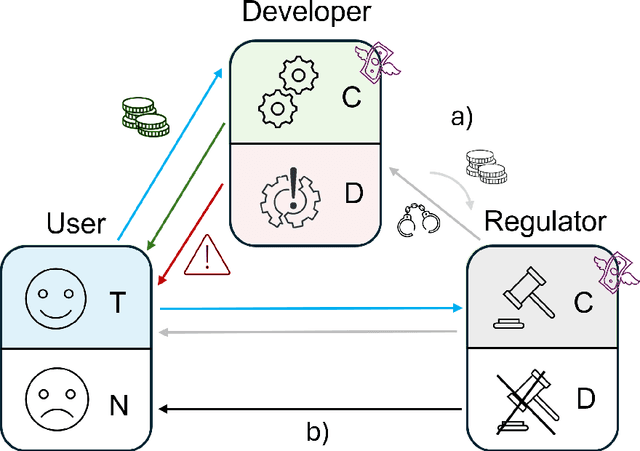
There is general agreement that fostering trust and cooperation within the AI development ecosystem is essential to promote the adoption of trustworthy AI systems. By embedding Large Language Model (LLM) agents within an evolutionary game-theoretic framework, this paper investigates the complex interplay between AI developers, regulators and users, modelling their strategic choices under different regulatory scenarios. Evolutionary game theory (EGT) is used to quantitatively model the dilemmas faced by each actor, and LLMs provide additional degrees of complexity and nuances and enable repeated games and incorporation of personality traits. Our research identifies emerging behaviours of strategic AI agents, which tend to adopt more "pessimistic" (not trusting and defective) stances than pure game-theoretic agents. We observe that, in case of full trust by users, incentives are effective to promote effective regulation; however, conditional trust may deteriorate the "social pact". Establishing a virtuous feedback between users' trust and regulators' reputation thus appears to be key to nudge developers towards creating safe AI. However, the level at which this trust emerges may depend on the specific LLM used for testing. Our results thus provide guidance for AI regulation systems, and help predict the outcome of strategic LLM agents, should they be used to aid regulation itself.
Media and responsible AI governance: a game-theoretic and LLM analysis
Mar 12, 2025This paper investigates the complex interplay between AI developers, regulators, users, and the media in fostering trustworthy AI systems. Using evolutionary game theory and large language models (LLMs), we model the strategic interactions among these actors under different regulatory regimes. The research explores two key mechanisms for achieving responsible governance, safe AI development and adoption of safe AI: incentivising effective regulation through media reporting, and conditioning user trust on commentariats' recommendation. The findings highlight the crucial role of the media in providing information to users, potentially acting as a form of "soft" regulation by investigating developers or regulators, as a substitute to institutional AI regulation (which is still absent in many regions). Both game-theoretic analysis and LLM-based simulations reveal conditions under which effective regulation and trustworthy AI development emerge, emphasising the importance of considering the influence of different regulatory regimes from an evolutionary game-theoretic perspective. The study concludes that effective governance requires managing incentives and costs for high quality commentaries.
Large Language Models' Detection of Political Orientation in Newspapers
May 23, 2024Democratic opinion-forming may be manipulated if newspapers' alignment to political or economical orientation is ambiguous. Various methods have been developed to better understand newspapers' positioning. Recently, the advent of Large Language Models (LLM), and particularly the pre-trained LLM chatbots like ChatGPT or Gemini, hold disruptive potential to assist researchers and citizens alike. However, little is know on whether LLM assessment is trustworthy: do single LLM agrees with experts' assessment, and do different LLMs answer consistently with one another? In this paper, we address specifically the second challenge. We compare how four widely employed LLMs rate the positioning of newspapers, and compare if their answers align with one another. We observe that this is not the case. Over a woldwide dataset, articles in newspapers are positioned strikingly differently by single LLMs, hinting to inconsistent training or excessive randomness in the algorithms. We thus raise a warning when deciding which tools to use, and we call for better training and algorithm development, to cover such significant gap in a highly sensitive matter for democracy and societies worldwide. We also call for community engagement in benchmark evaluation, through our open initiative navai.pro.
ChatGPT vs Gemini vs LLaMA on Multilingual Sentiment Analysis
Jan 25, 2024Automated sentiment analysis using Large Language Model (LLM)-based models like ChatGPT, Gemini or LLaMA2 is becoming widespread, both in academic research and in industrial applications. However, assessment and validation of their performance in case of ambiguous or ironic text is still poor. In this study, we constructed nuanced and ambiguous scenarios, we translated them in 10 languages, and we predicted their associated sentiment using popular LLMs. The results are validated against post-hoc human responses. Ambiguous scenarios are often well-coped by ChatGPT and Gemini, but we recognise significant biases and inconsistent performance across models and evaluated human languages. This work provides a standardised methodology for automated sentiment analysis evaluation and makes a call for action to further improve the algorithms and their underlying data, to improve their performance, interpretability and applicability.