 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust as Monitoring: Evolutionary Dynamics of User Trust and AI Developer Behaviour
Mar 25, 2026AI safety is an increasingly urgent concern as the capabilities and adoption of AI systems grow. Existing evolutionary models of AI governance have primarily examined incentives for safe development and effective regulation, typically representing users' trust as a one-shot adoption choice rather than as a dynamic, evolving process shaped by repeated interactions. We instead model trust as reduced monitoring in a repeated, asymmetric interaction between users and AI developers, where checking AI behaviour is costly. Using evolutionary game theory, we study how user trust strategies and developer choices between safe (compliant) and unsafe (non-compliant) AI co-evolve under different levels of monitoring cost and institutional regimes. We complement the infinite-population replicator analysis with stochastic finite-population dynamics and reinforcement learning (Q-learning) simulations. Across these approaches, we find three robust long-run regimes: no adoption with unsafe development, unsafe but widely adopted systems, and safe systems that are widely adopted. Only the last is desirable, and it arises when penalties for unsafe behaviour exceed the extra cost of safety and users can still afford to monitor at least occasionally. Our results formally support governance proposals that emphasise transparency, low-cost monitoring, and meaningful sanctions, and they show that neither regulation alone nor blind user trust is sufficient to prevent evolutionary drift towards unsafe or low-adoption outcomes.
Do LLMs trust AI regulation? Emerging behaviour of game-theoretic LLM agents
Apr 11, 2025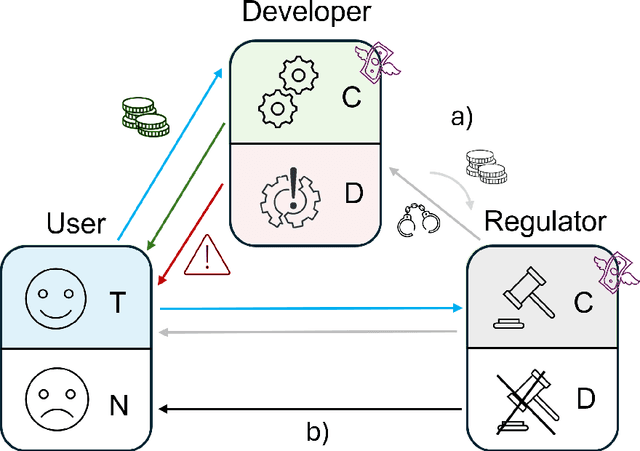
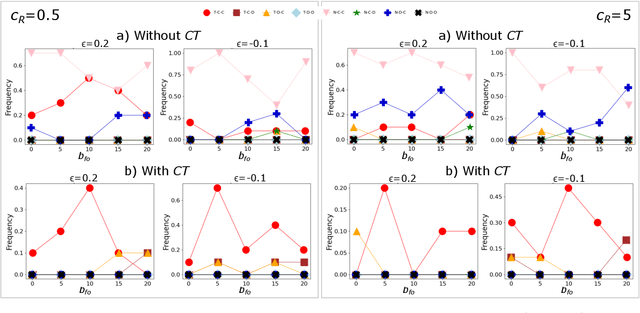
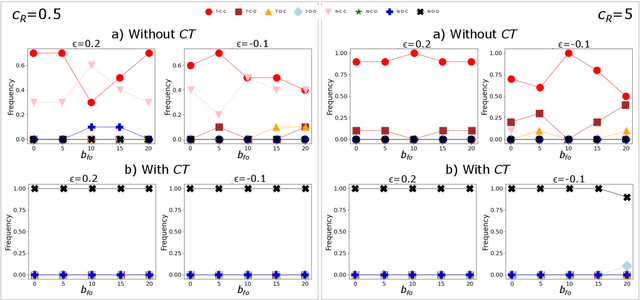
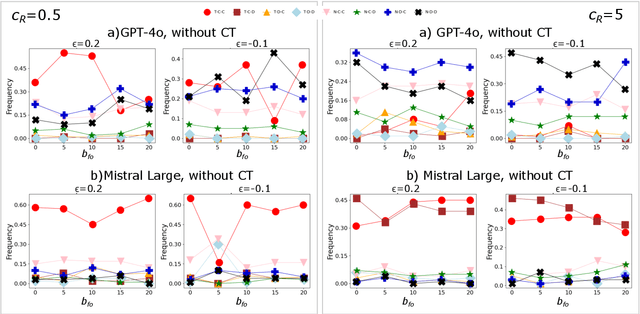
There is general agreement that fostering trust and cooperation within the AI development ecosystem is essential to promote the adoption of trustworthy AI systems. By embedding Large Language Model (LLM) agents within an evolutionary game-theoretic framework, this paper investigates the complex interplay between AI developers, regulators and users, modelling their strategic choices under different regulatory scenarios. Evolutionary game theory (EGT) is used to quantitatively model the dilemmas faced by each actor, and LLMs provide additional degrees of complexity and nuances and enable repeated games and incorporation of personality traits. Our research identifies emerging behaviours of strategic AI agents, which tend to adopt more "pessimistic" (not trusting and defective) stances than pure game-theoretic agents. We observe that, in case of full trust by users, incentives are effective to promote effective regulation; however, conditional trust may deteriorate the "social pact". Establishing a virtuous feedback between users' trust and regulators' reputation thus appears to be key to nudge developers towards creating safe AI. However, the level at which this trust emerges may depend on the specific LLM used for testing. Our results thus provide guidance for AI regulation systems, and help predict the outcome of strategic LLM agents, should they be used to aid regulation itself.
Media and responsible AI governance: a game-theoretic and LLM analysis
Mar 12, 2025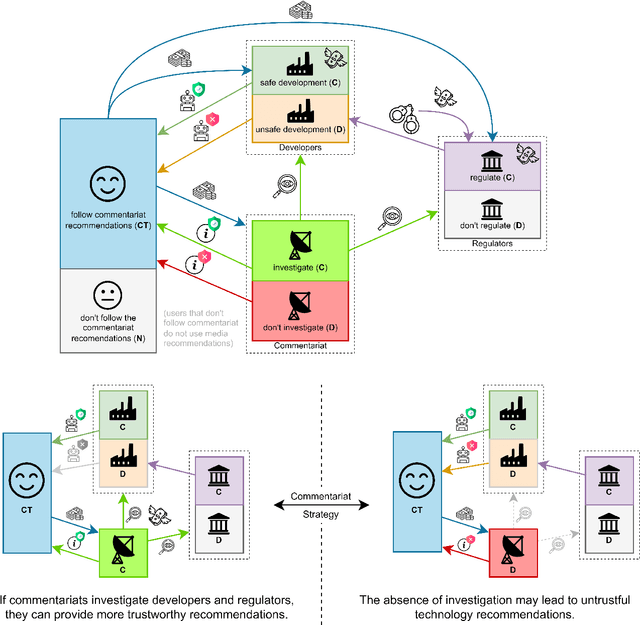
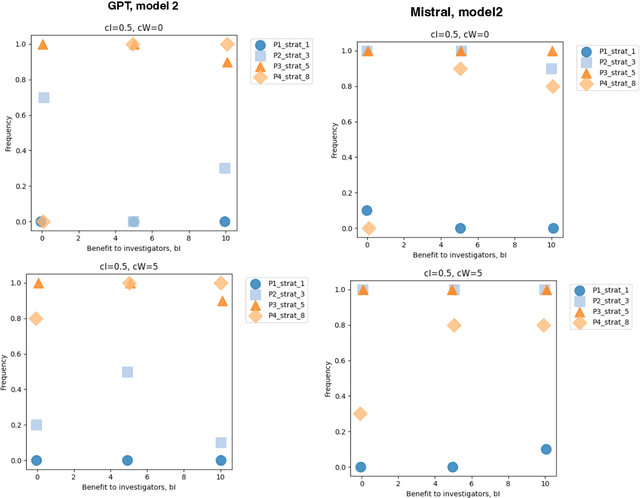


This paper investigates the complex interplay between AI developers, regulators, users, and the media in fostering trustworthy AI systems. Using evolutionary game theory and large language models (LLMs), we model the strategic interactions among these actors under different regulatory regimes. The research explores two key mechanisms for achieving responsible governance, safe AI development and adoption of safe AI: incentivising effective regulation through media reporting, and conditioning user trust on commentariats' recommendation. The findings highlight the crucial role of the media in providing information to users, potentially acting as a form of "soft" regulation by investigating developers or regulators, as a substitute to institutional AI regulation (which is still absent in many regions). Both game-theoretic analysis and LLM-based simulations reveal conditions under which effective regulation and trustworthy AI development emerge, emphasising the importance of considering the influence of different regulatory regimes from an evolutionary game-theoretic perspective. The study concludes that effective governance requires managing incentives and costs for high quality commentaries.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Quantifying detection rates for dangerous capabilities: a theoretical model of dangerous capability evaluations
Dec 19, 2024



We present a quantitative model for tracking dangerous AI capabilities over time. Our goal is to help the policy and research community visualise how dangerous capability testing can give us an early warning about approaching AI risks. We first use the model to provide a novel introduction to dangerous capability testing and how this testing can directly inform policy. Decision makers in AI labs and government often set policy that is sensitive to the estimated danger of AI systems, and may wish to set policies that condition on the crossing of a set threshold for danger. The model helps us to reason about these policy choices. We then run simulations to illustrate how we might fail to test for dangerous capabilities. To summarise, failures in dangerous capability testing may manifest in two ways: higher bias in our estimates of AI danger, or larger lags in threshold monitoring. We highlight two drivers of these failure modes: uncertainty around dynamics in AI capabilities and competition between frontier AI labs. Effective AI policy demands that we address these failure modes and their drivers. Even if the optimal targeting of resources is challenging, we show how delays in testing can harm AI policy. We offer preliminary recommendations for building an effective testing ecosystem for dangerous capabilities and advise on a research agenda.
Trust AI Regulation? Discerning users are vital to build trust and effective AI regulation
Mar 14, 2024There is general agreement that some form of regulation is necessary both for AI creators to be incentivised to develop trustworthy systems, and for users to actually trust those systems. But there is much debate about what form these regulations should take and how they should be implemented. Most work in this area has been qualitative, and has not been able to make formal predictions. Here, we propose that evolutionary game theory can be used to quantitatively model the dilemmas faced by users, AI creators, and regulators, and provide insights into the possible effects of different regulatory regimes. We show that creating trustworthy AI and user trust requires regulators to be incentivised to regulate effectively. We demonstrate the effectiveness of two mechanisms that can achieve this. The first is where governments can recognise and reward regulators that do a good job. In that case, if the AI system is not too risky for users then some level of trustworthy development and user trust evolves. We then consider an alternative solution, where users can condition their trust decision on the effectiveness of the regulators. This leads to effective regulation, and consequently the development of trustworthy AI and user trust, provided that the cost of implementing regulations is not too high. Our findings highlight the importance of considering the effect of different regulatory regimes from an evolutionary game theoretic perspective.
Both eyes open: Vigilant Incentives help Regulatory Markets improve AI Safety
Mar 06, 2023In the context of rapid discoveries by leaders in AI, governments must consider how to design regulation that matches the increasing pace of new AI capabilities. Regulatory Markets for AI is a proposal designed with adaptability in mind. It involves governments setting outcome-based targets for AI companies to achieve, which they can show by purchasing services from a market of private regulators. We use an evolutionary game theory model to explore the role governments can play in building a Regulatory Market for AI systems that deters reckless behaviour. We warn that it is alarmingly easy to stumble on incentives which would prevent Regulatory Markets from achieving this goal. These 'Bounty Incentives' only reward private regulators for catching unsafe behaviour. We argue that AI companies will likely learn to tailor their behaviour to how much effort regulators invest, discouraging regulators from innovating. Instead, we recommend that governments always reward regulators, except when they find that those regulators failed to detect unsafe behaviour that they should have. These 'Vigilant Incentives' could encourage private regulators to find innovative ways to evaluate cutting-edge AI systems.
Safe Transformative AI via a Windfall Clause
Aug 28, 2021



Society could soon see transformative artificial intelligence (TAI). Models of competition for TAI show firms face strong competitive pressure to deploy TAI systems before they are safe. This paper explores a proposed solution to this problem, a Windfall Clause, where developers commit to donating a significant portion of any eventual extremely large profits to good causes. However, a key challenge for a Windfall Clause is that firms must have reason to join one. Firms must also believe these commitments are credible. We extend a model of TAI competition with a Windfall Clause to show how firms and policymakers can design a Windfall Clause which overcomes these challenges. Encouragingly, firms benefit from joining a Windfall Clause under a wide range of scenarios. We also find that firms join the Windfall Clause more often when the competition is more dangerous. Even when firms learn each other's capabilities, firms rarely wish to withdraw their support for the Windfall Clause. These three findings strengthen the case for using a Windfall Clause to promote the safe development of TAI.