 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShe Elicits Requirements and He Tests: Software Engineering Gender Bias in Large Language Models
Mar 17, 2023Implicit gender bias in software development is a well-documented issue, such as the association of technical roles with men. To address this bias, it is important to understand it in more detail. This study uses data mining techniques to investigate the extent to which 56 tasks related to software development, such as assigning GitHub issues and testing, are affected by implicit gender bias embedded in large language models. We systematically translated each task from English into a genderless language and back, and investigated the pronouns associated with each task. Based on translating each task 100 times in different permutations, we identify a significant disparity in the gendered pronoun associations with different tasks. Specifically, requirements elicitation was associated with the pronoun "he" in only 6% of cases, while testing was associated with "he" in 100% of cases. Additionally, tasks related to helping others had a 91% association with "he" while the same association for tasks related to asking coworkers was only 52%. These findings reveal a clear pattern of gender bias related to software development tasks and have important implications for addressing this issue both in the training of large language models and in broader society.
Towards Generation of Visual Attention Map for Source Code
Aug 13, 2019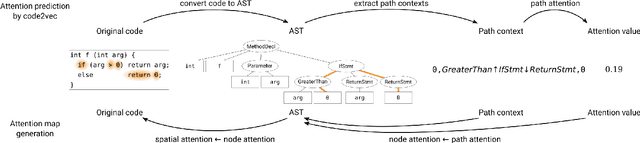


Program comprehension is a dominant process in software development and maintenance. Experts are considered to comprehend the source code efficiently by directing their gaze, or attention, to important components in it. However, reflecting the importance of components is still a remaining issue in gaze behavior analysis for source code comprehension. Here we show a conceptual framework to compare the quantified importance of source code components with the gaze behavior of programmers. We use "attention" in attention models (e.g., code2vec) as the importance indices for source code components and evaluate programmers' gaze locations based on the quantified importance. In this report, we introduce the idea of our gaze behavior analysis using the attention map, and the results of a preliminary experiment.
Sentiment Classification using N-gram IDF and Automated Machine Learning
May 25, 2019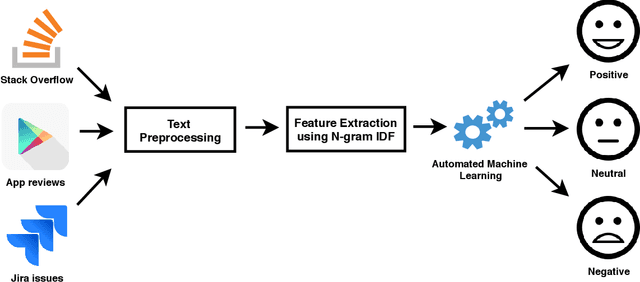
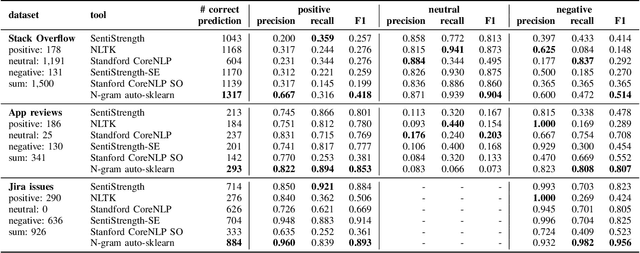

We propose a sentiment classification method with a general machine learning framework. For feature representation, n-gram IDF is used to extract software-engineering-related, dataset-specific, positive, neutral, and negative n-gram expressions. For classifiers, an automated machine learning tool is used. In the comparison using publicly available datasets, our method achieved the highest F1 values in positive and negative sentences on all datasets.
Toward Imitating Visual Attention of Experts in Software Development Tasks
Mar 15, 2019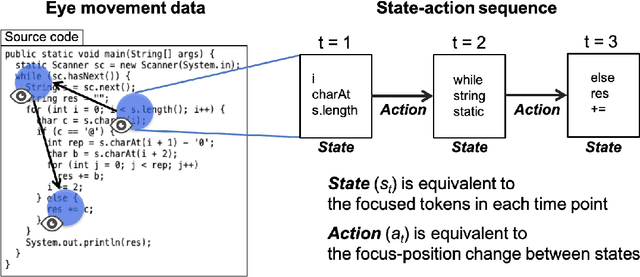
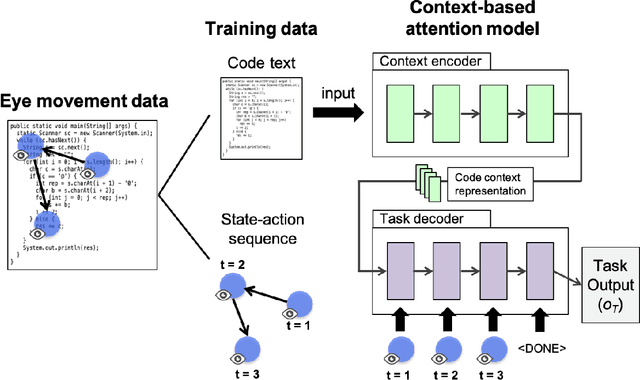
Expert programmers' eye-movements during source code reading are valuable sources that are considered to be associated with their domain expertise. We advocate a vision of new intelligent systems incorporating expertise of experts for software development tasks, such as issue localization, comment generation, and code generation. We present a conceptual framework of neural autonomous agents based on imitation learning (IL), which enables agents to mimic the visual attention of an expert via his/her eye movement. In this framework, an autonomous agent is constructed as a context-based attention model that consists of encoder/decoder network and trained with state-action sequences generated by an experts' demonstration. Challenges to implement an IL-based autonomous agent specialized for software development task are discussed in this paper.