 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositionality-Aware Graph2Seq Learning
Jan 28, 2022

Graphs are a highly expressive data structure, but it is often difficult for humans to find patterns from a complex graph. Hence, generating human-interpretable sequences from graphs have gained interest, called graph2seq learning. It is expected that the compositionality in a graph can be associated to the compositionality in the output sequence in many graph2seq tasks. Therefore, applying compositionality-aware GNN architecture would improve the model performance. In this study, we adopt the multi-level attention pooling (MLAP) architecture, that can aggregate graph representations from multiple levels of information localities. As a real-world example, we take up the extreme source code summarization task, where a model estimate the name of a program function from its source code. We demonstrate that the model having the MLAP architecture outperform the previous state-of-the-art model with more than seven times fewer parameters than it.
Multi-Level Attention Pooling for Graph Neural Networks: Unifying Graph Representations with Multiple Localities
Mar 02, 2021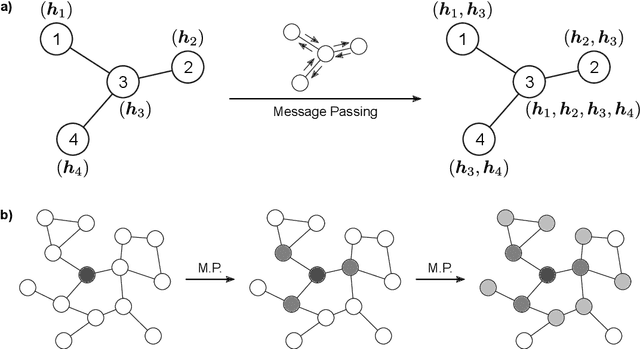
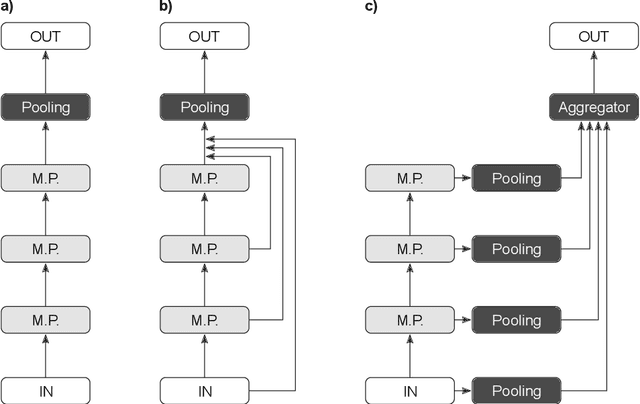
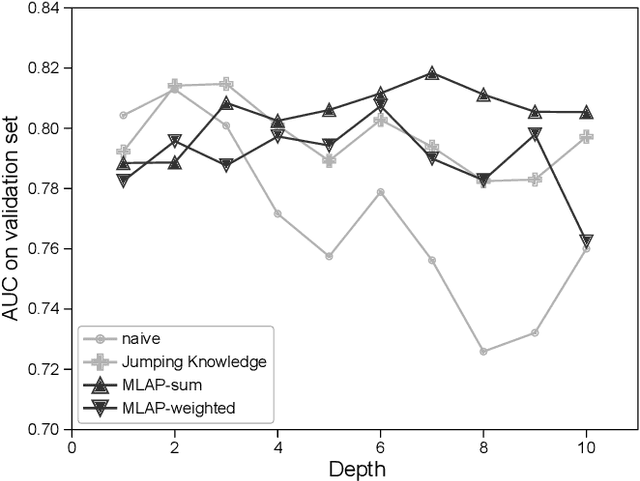
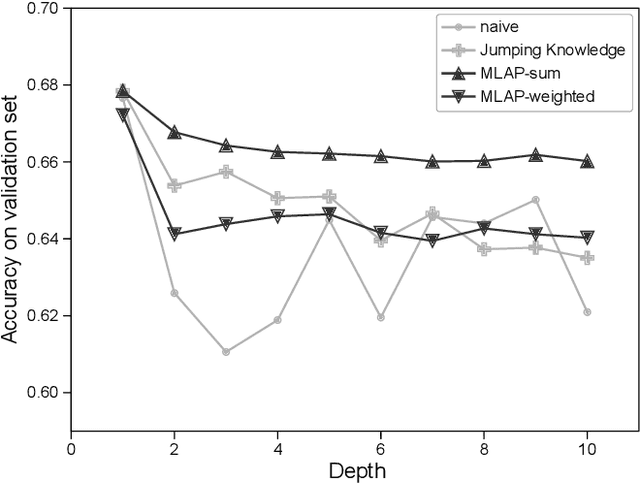
Graph neural networks (GNNs) have been widely used to learn vector representation of graph-structured data and achieved better task performance than conventional methods. The foundation of GNNs is the message passing procedure, which propagates the information in a node to its neighbors. Since this procedure proceeds one step per layer, the scope of the information propagation among nodes is small in the early layers, and it expands toward the later layers. The problem here is that the model performances degrade as the number of layers increases. A potential cause is that deep GNN models tend to lose the nodes' local information, which would be essential for good model performances, through many message passing steps. To solve this so-called oversmoothing problem, we propose a multi-level attention pooling (MLAP) architecture. It has an attention pooling layer for each message passing step and computes the final graph representation by unifying the layer-wise graph representations. The MLAP architecture allows models to utilize the structural information of graphs with multiple levels of localities because it preserves layer-wise information before losing them due to oversmoothing. Results of our experiments show that the MLAP architecture improves deeper models' performance in graph classification tasks compared to the baseline architectures. In addition, analyses on the layer-wise graph representations suggest that MLAP has the potential to learn graph representations with improved class discriminability by aggregating information with multiple levels of localities.
Detecting Unknown Behaviors by Pre-defined Behaviours: An Bayesian Non-parametric Approach
Dec 11, 2019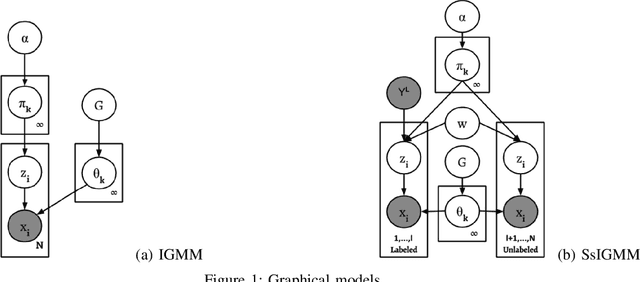
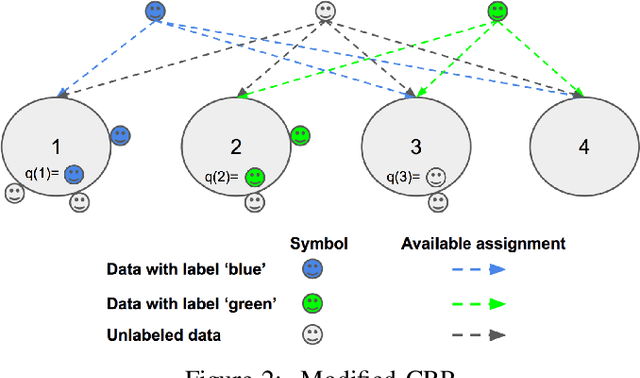
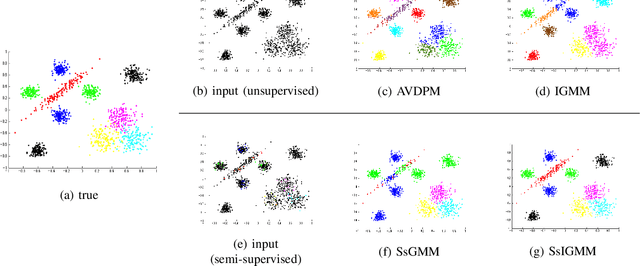

An automatic mouse behavior recognition system can considerably reduce the workload of experimenters and facilitate the analysis process. Typically, supervised approaches, unsupervised approaches and semi-supervised approaches are applied for behavior recognition purpose under a setting which has all of predefined behaviors. In the real situation, however, as mouses can show various types of behaviors, besides the predefined behaviors that we want to analyze, there are many undefined behaviors existing. Both supervised approaches and conventional semi-supervised approaches cannot identify these undefined behaviors. Though unsupervised approaches can detect these undefined behaviors, a post-hoc labeling is needed. In this paper, we propose a semi-supervised infinite Gaussian mixture model (SsIGMM), to incorporate both labeled and unlabelled information in learning process while considering undefined behaviors. It also generates the distribution of the predefined and undefined behaviors by mixture Gaussians, which can be used for further analysis. In our experiments, we confirmed the superiority of SsIGMM for segmenting and labelling mouse-behavior videos.
A Hierarchical Mixture Density Network
Oct 23, 2019
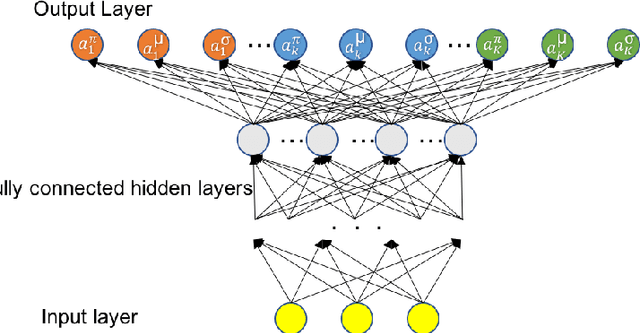

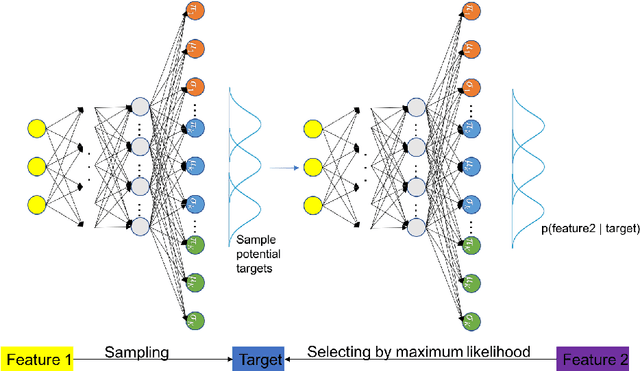
The relationship among three correlated variables could be very sophisticated, as a result, we may not be able to find their hidden causality and model their relationship explicitly. However, we still can make our best guess for possible mappings among these variables, based on the observed relationship. One of the complicated relationships among three correlated variables could be a two-layer hierarchical many-to-many mapping. In this paper, we proposed a Hierarchical Mixture Density Network (HMDN) to model the two-layer hierarchical many-to-many mapping. We apply HMDN on an indoor positioning problem and show its benefit.
* 8 pages, 5 figures, conference
Towards Generation of Visual Attention Map for Source Code
Aug 13, 2019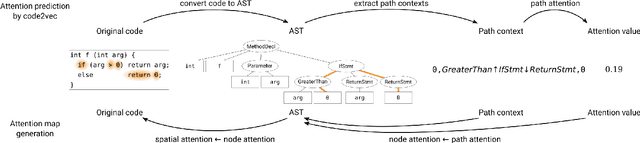


Program comprehension is a dominant process in software development and maintenance. Experts are considered to comprehend the source code efficiently by directing their gaze, or attention, to important components in it. However, reflecting the importance of components is still a remaining issue in gaze behavior analysis for source code comprehension. Here we show a conceptual framework to compare the quantified importance of source code components with the gaze behavior of programmers. We use "attention" in attention models (e.g., code2vec) as the importance indices for source code components and evaluate programmers' gaze locations based on the quantified importance. In this report, we introduce the idea of our gaze behavior analysis using the attention map, and the results of a preliminary experiment.
Toward Imitating Visual Attention of Experts in Software Development Tasks
Mar 15, 2019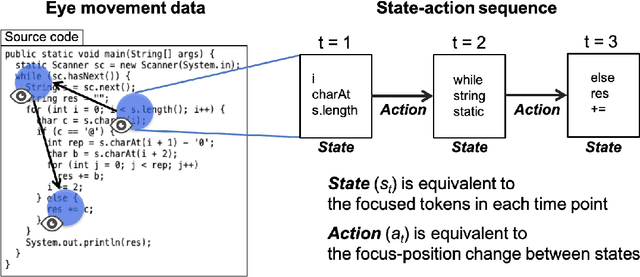
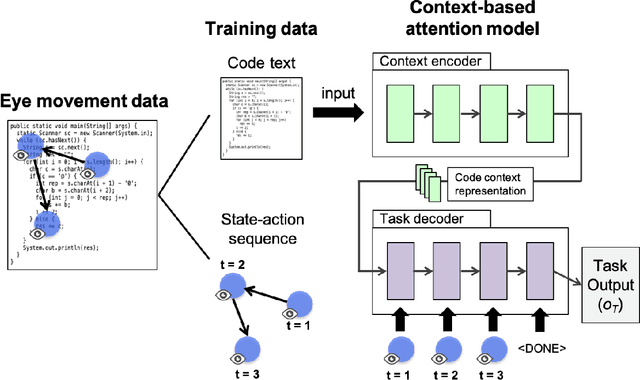
Expert programmers' eye-movements during source code reading are valuable sources that are considered to be associated with their domain expertise. We advocate a vision of new intelligent systems incorporating expertise of experts for software development tasks, such as issue localization, comment generation, and code generation. We present a conceptual framework of neural autonomous agents based on imitation learning (IL), which enables agents to mimic the visual attention of an expert via his/her eye movement. In this framework, an autonomous agent is constructed as a context-based attention model that consists of encoder/decoder network and trained with state-action sequences generated by an experts' demonstration. Challenges to implement an IL-based autonomous agent specialized for software development task are discussed in this paper.