 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow AI Coding Agents Communicate: A Study of Pull Request Description Characteristics and Human Review Responses
Feb 19, 2026The rapid adoption of large language models has led to the emergence of AI coding agents that autonomously create pull requests on GitHub. However, how these agents differ in their pull request description characteristics, and how human reviewers respond to them, remains underexplored. In this study, we conduct an empirical analysis of pull requests created by five AI coding agents using the AIDev dataset. We analyze agent differences in pull request description characteristics, including structural features, and examine human reviewer response in terms of review activity, response timing, sentiment, and merge outcomes. We find that AI coding agents exhibit distinct PR description styles, which are associated with differences in reviewer engagement, response time, and merge outcomes. We observe notable variation across agents in both reviewer interaction metrics and merge rates. These findings highlight the role of pull request presentation and reviewer interaction dynamics in human-AI collaborative software development.
Uncovering Intention through LLM-Driven Code Snippet Description Generation
Jun 18, 2025Documenting code snippets is essential to pinpoint key areas where both developers and users should pay attention. Examples include usage examples and other Application Programming Interfaces (APIs), which are especially important for third-party libraries. With the rise of Large Language Models (LLMs), the key goal is to investigate the kinds of description developers commonly use and evaluate how well an LLM, in this case Llama, can support description generation. We use NPM Code Snippets, consisting of 185,412 packages with 1,024,579 code snippets. From there, we use 400 code snippets (and their descriptions) as samples. First, our manual classification found that the majority of original descriptions (55.5%) highlight example-based usage. This finding emphasizes the importance of clear documentation, as some descriptions lacked sufficient detail to convey intent. Second, the LLM correctly identified the majority of original descriptions as "Example" (79.75%), which is identical to our manual finding, showing a propensity for generalization. Third, compared to the originals, the produced description had an average similarity score of 0.7173, suggesting relevance but room for improvement. Scores below 0.9 indicate some irrelevance. Our results show that depending on the task of the code snippet, the intention of the document may differ from being instructions for usage, installations, or descriptive learning examples for any user of a library.
A Simulation Study of Bandit Algorithms to Address External Validity of Software Fault Prediction
Mar 17, 2020



Various software fault prediction models and techniques for building algorithms have been proposed. Many studies have compared and evaluated them to identify the most effective ones. However, in most cases, such models and techniques do not have the best performance on every dataset. This is because there is diversity of software development datasets, and therefore, there is a risk that the selected model or technique shows bad performance on a certain dataset. To avoid selecting a low accuracy model, we apply bandit algorithms to predict faults. Consider a case where player has 100 coins to bet on several slot machines. Ordinary usage of software fault prediction is analogous to the player betting all 100 coins in one slot machine. In contrast, bandit algorithms bet one coin on each machine (i.e., use prediction models) step-by-step to seek the best machine. In the experiment, we developed an artificial dataset that includes 100 modules, 15 of which include faults. Then, we developed various artificial fault prediction models and selected them dynamically using bandit algorithms. The Thomson sampling algorithm showed the best or second-best prediction performance compared with using only one prediction model.
Towards Generation of Visual Attention Map for Source Code
Aug 13, 2019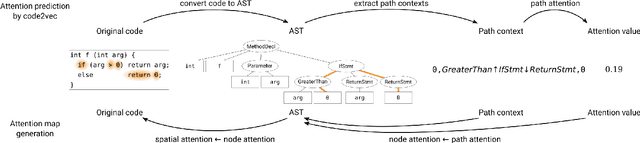


Program comprehension is a dominant process in software development and maintenance. Experts are considered to comprehend the source code efficiently by directing their gaze, or attention, to important components in it. However, reflecting the importance of components is still a remaining issue in gaze behavior analysis for source code comprehension. Here we show a conceptual framework to compare the quantified importance of source code components with the gaze behavior of programmers. We use "attention" in attention models (e.g., code2vec) as the importance indices for source code components and evaluate programmers' gaze locations based on the quantified importance. In this report, we introduce the idea of our gaze behavior analysis using the attention map, and the results of a preliminary experiment.
Sentiment Classification using N-gram IDF and Automated Machine Learning
May 25, 2019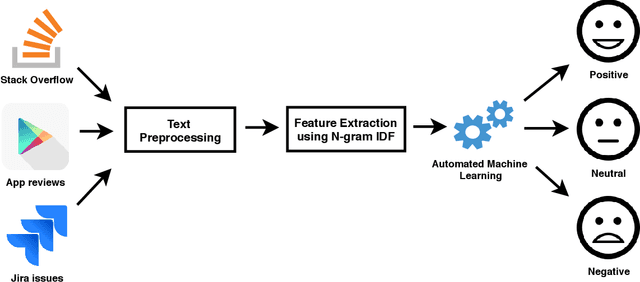
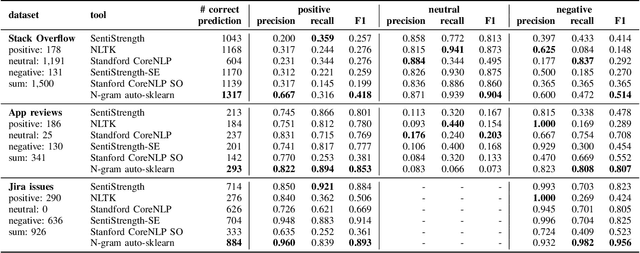

We propose a sentiment classification method with a general machine learning framework. For feature representation, n-gram IDF is used to extract software-engineering-related, dataset-specific, positive, neutral, and negative n-gram expressions. For classifiers, an automated machine learning tool is used. In the comparison using publicly available datasets, our method achieved the highest F1 values in positive and negative sentences on all datasets.
Toward Imitating Visual Attention of Experts in Software Development Tasks
Mar 15, 2019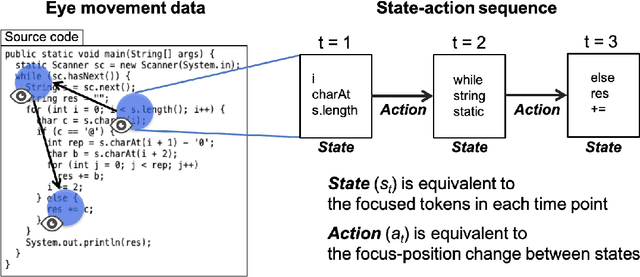
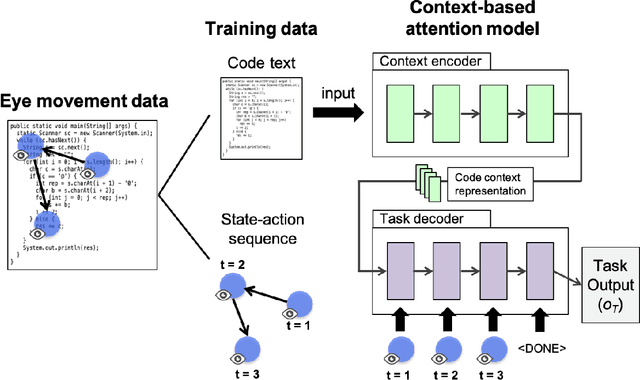
Expert programmers' eye-movements during source code reading are valuable sources that are considered to be associated with their domain expertise. We advocate a vision of new intelligent systems incorporating expertise of experts for software development tasks, such as issue localization, comment generation, and code generation. We present a conceptual framework of neural autonomous agents based on imitation learning (IL), which enables agents to mimic the visual attention of an expert via his/her eye movement. In this framework, an autonomous agent is constructed as a context-based attention model that consists of encoder/decoder network and trained with state-action sequences generated by an experts' demonstration. Challenges to implement an IL-based autonomous agent specialized for software development task are discussed in this paper.