 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Integration Practices in Machine Learning Projects: The Practitioners` Perspective
Feb 24, 2025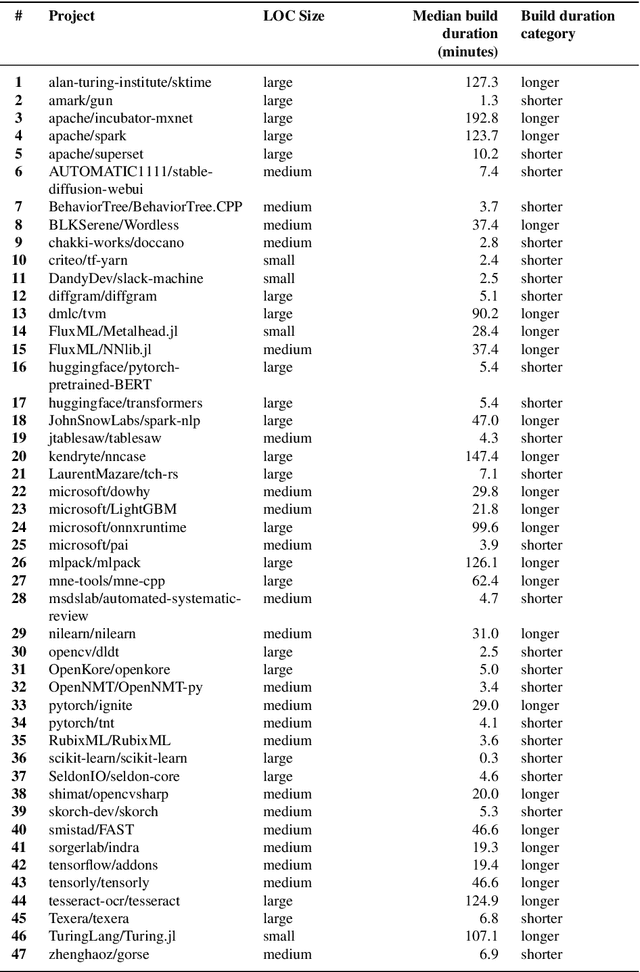



Continuous Integration (CI) is a cornerstone of modern software development. However, while widely adopted in traditional software projects, applying CI practices to Machine Learning (ML) projects presents distinctive characteristics. For example, our previous work revealed that ML projects often experience longer build durations and lower test coverage rates compared to their non-ML counterparts. Building on these quantitative findings, this study surveys 155 practitioners from 47 ML projects to investigate the underlying reasons for these distinctive characteristics through a qualitative perspective. Practitioners highlighted eight key differences, including test complexity, infrastructure requirements, and build duration and stability. Common challenges mentioned by practitioners include higher project complexity, model training demands, extensive data handling, increased computational resource needs, and dependency management, all contributing to extended build durations. Furthermore, ML systems' non-deterministic nature, data dependencies, and computational constraints were identified as significant barriers to effective testing. The key takeaway from this study is that while foundational CI principles remain valuable, ML projects require tailored approaches to address their unique challenges. To bridge this gap, we propose a set of ML-specific CI practices, including tracking model performance metrics and prioritizing test execution within CI pipelines. Additionally, our findings highlight the importance of fostering interdisciplinary collaboration to strengthen the testing culture in ML projects. By bridging quantitative findings with practitioners' insights, this study provides a deeper understanding of the interplay between CI practices and the unique demands of ML projects, laying the groundwork for more efficient and robust CI strategies in this domain.
The Impact Of Bug Localization Based on Crash Report Mining: A Developers' Perspective
Mar 16, 2024Developers often use crash reports to understand the root cause of bugs. However, locating the buggy source code snippet from such information is a challenging task, mainly when the log database contains many crash reports. To mitigate this issue, recent research has proposed and evaluated approaches for grouping crash report data and using stack trace information to locate bugs. The effectiveness of such approaches has been evaluated by mainly comparing the candidate buggy code snippets with the actual changed code in bug-fix commits -- which happens in the context of retrospective repository mining studies. Therefore, the existing literature still lacks discussing the use of such approaches in the daily life of a software company, which could explain the developers' perceptions on the use of these approaches. In this paper, we report our experience of using an approach for grouping crash reports and finding buggy code on a weekly basis for 18 months, within three development teams in a software company. We grouped over 750,000 crash reports, opened over 130 issues, and collected feedback from 18 developers and team leaders. Among other results, we observe that the amount of system logs related to a crash report group is not the only criteria developers use to choose a candidate bug to be analyzed. Instead, other factors were considered, such as the need to deliver customer-prioritized features and the difficulty of solving complex crash reports (e.g., architectural debts), to cite some. The approach investigated in this study correctly suggested the buggy file most of the time -- the approach's precision was around 80%. In this study, the developers also shared their perspectives on the usefulness of the suspicious files and methods extracted from crash reports to fix related bugs.
How do Machine Learning Projects use Continuous Integration Practices? An Empirical Study on GitHub Actions
Mar 14, 2024



Continuous Integration (CI) is a well-established practice in traditional software development, but its nuances in the domain of Machine Learning (ML) projects remain relatively unexplored. Given the distinctive nature of ML development, understanding how CI practices are adopted in this context is crucial for tailoring effective approaches. In this study, we conduct a comprehensive analysis of 185 open-source projects on GitHub (93 ML and 92 non-ML projects). Our investigation comprises both quantitative and qualitative dimensions, aiming to uncover differences in CI adoption between ML and non-ML projects. Our findings indicate that ML projects often require longer build durations, and medium-sized ML projects exhibit lower test coverage compared to non-ML projects. Moreover, small and medium-sized ML projects show a higher prevalence of increasing build duration trends compared to their non-ML counterparts. Additionally, our qualitative analysis illuminates the discussions around CI in both ML and non-ML projects, encompassing themes like CI Build Execution and Status, CI Testing, and CI Infrastructure. These insights shed light on the unique challenges faced by ML projects in adopting CI practices effectively.