 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Categorising GitHub Repositories by Application Domain
Paper and Code


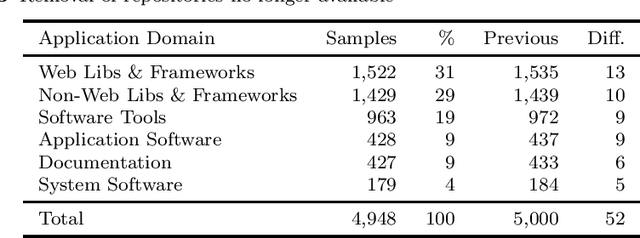

GitHub is the largest host of open source software on the Internet. This large, freely accessible database has attracted the attention of practitioners and researchers alike. But as GitHub's growth continues, it is becoming increasingly hard to navigate the plethora of repositories which span a wide range of domains. Past work has shown that taking the application domain into account is crucial for tasks such as predicting the popularity of a repository and reasoning about project quality. In this work, we build on a previously annotated dataset of 5,000 GitHub repositories to design an automated classifier for categorising repositories by their application domain. The classifier uses state-of-the-art natural language processing techniques and machine learning to learn from multiple data sources and catalogue repositories according to five application domains. We contribute with (1) an automated classifier that can assign popular repositories to each application domain with at least 70% precision, (2) an investigation of the approach's performance on less popular repositories, and (3) a practical application of this approach to answer how the adoption of software engineering practices differs across application domains. Our work aims to help the GitHub community identify repositories of interest and opens promising avenues for future work investigating differences between repositories from different application domains.