 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Networks Out-of-Distribution Detection: Hyperparameter-Free Isotropic Maximization Loss, The Principle of Maximum Entropy, Cold Training, and Branched Inferences
Paper and Code
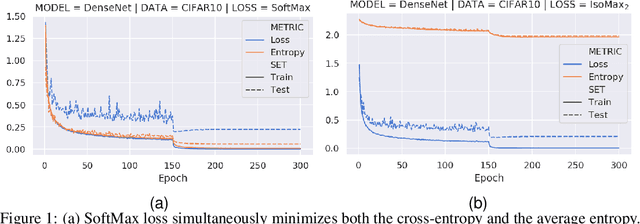

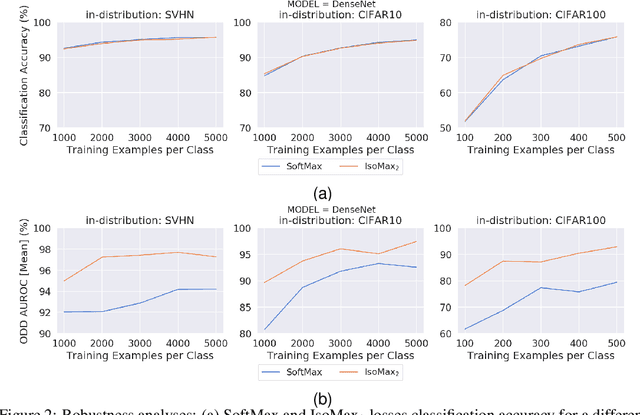

Current out-of-distribution detection (ODD) approaches present severe drawbacks that make impracticable their large scale adoption in real-world applications. In this paper, we propose a novel loss called Hyperparameter-Free IsoMax that overcomes these limitations. We modified the original IsoMax loss to improve ODD performance while maintaining benefits such as high classification accuracy, fast and energy-efficient inference, and scalability. The global hyperparameter is replaced by learnable parameters to increase performance. Additionally, a theoretical motivation to explain the high ODD performance of the proposed loss is presented. Finally, to keep high classification performance, slightly different inference mathematical expressions for classification and ODD are developed. No access to out-of-distribution samples is required, as there is no hyperparameter to tune. Our solution works as a straightforward SoftMax loss drop-in replacement that can be incorporated without relying on adversarial training or validation, model structure chances, ensembles methods, or generative approaches. The experiments showed that our approach is competitive against state-of-the-art solutions while avoiding their additional requirements and undesired side effects.