 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Lossless Encoding of Sentences
Paper and Code
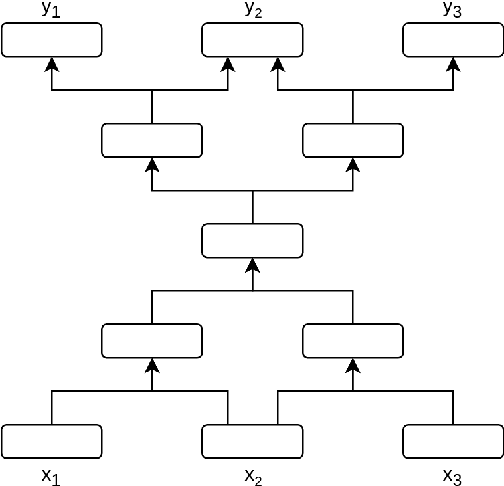
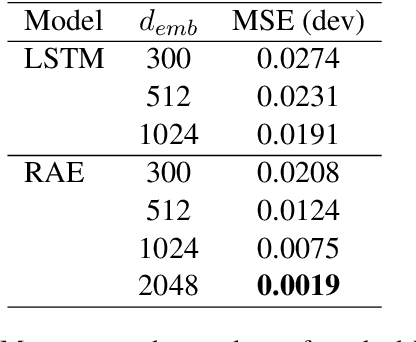
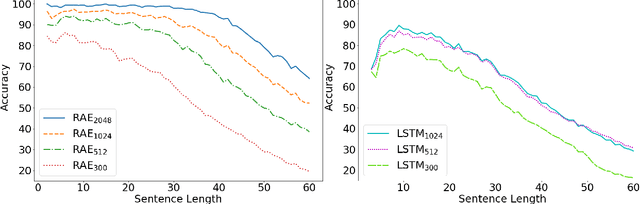

A lot of work has been done in the field of image compression via machine learning, but not much attention has been given to the compression of natural language. Compressing text into lossless representations while making features easily retrievable is not a trivial task, yet has huge benefits. Most methods designed to produce feature rich sentence embeddings focus solely on performing well on downstream tasks and are unable to properly reconstruct the original sequence from the learned embedding. In this work, we propose a near lossless method for encoding long sequences of texts as well as all of their sub-sequences into feature rich representations. We test our method on sentiment analysis and show good performance across all sub-sentence and sentence embeddings.