 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hamiltonian of Poly-matrix Zero-sum Games
May 19, 2025Understanding a dynamical system fundamentally relies on establishing an appropriate Hamiltonian function and elucidating its symmetries. By formulating agents' strategies and cumulative payoffs as canonically conjugate variables, we identify the Hamiltonian function that generates the dynamics of poly-matrix zero-sum games. We reveal the symmetries of our Hamiltonian and derive the associated conserved quantities, showing how the conservation of probability and the invariance of the Fenchel coupling are intrinsically encoded within the system. Furthermore, we propose the dissipation FTRL (DFTRL) dynamics by introducing a perturbation that dissipates the Fenchel coupling, proving convergence to the Nash equilibrium and linking DFTRL to last-iterate convergent algorithms. Our results highlight the potential of Hamiltonian dynamics in uncovering the structural properties of learning dynamics in games, and pave the way for broader applications of Hamiltonian dynamics in game theory and machine learning.
Hierarchical Associative Memory, Parallelized MLP-Mixer, and Symmetry Breaking
Jun 18, 2024Transformers have established themselves as the leading neural network model in natural language processing and are increasingly foundational in various domains. In vision, the MLP-Mixer model has demonstrated competitive performance, suggesting that attention mechanisms might not be indispensable. Inspired by this, recent research has explored replacing attention modules with other mechanisms, including those described by MetaFormers. However, the theoretical framework for these models remains underdeveloped. This paper proposes a novel perspective by integrating Krotov's hierarchical associative memory with MetaFormers, enabling a comprehensive representation of the entire Transformer block, encompassing token-/channel-mixing modules, layer normalization, and skip connections, as a single Hopfield network. This approach yields a parallelized MLP-Mixer derived from a three-layer Hopfield network, which naturally incorporates symmetric token-/channel-mixing modules and layer normalization. Empirical studies reveal that symmetric interaction matrices in the model hinder performance in image recognition tasks. Introducing symmetry-breaking effects transitions the performance of the symmetric parallelized MLP-Mixer to that of the vanilla MLP-Mixer. This indicates that during standard training, weight matrices of the vanilla MLP-Mixer spontaneously acquire a symmetry-breaking configuration, enhancing their effectiveness. These findings offer insights into the intrinsic properties of Transformers and MLP-Mixers and their theoretical underpinnings, providing a robust framework for future model design and optimization.
Decision Mamba: Reinforcement Learning via Sequence Modeling with Selective State Spaces
Mar 29, 2024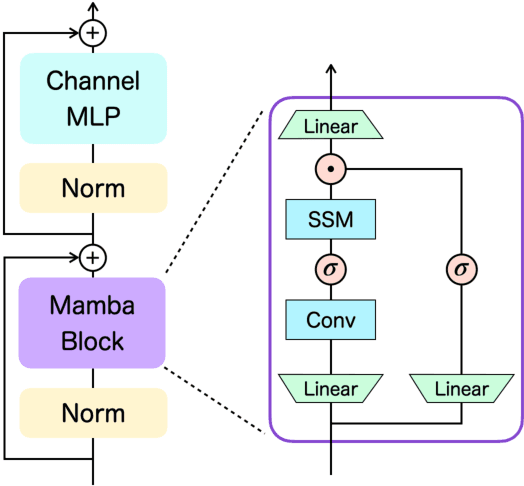
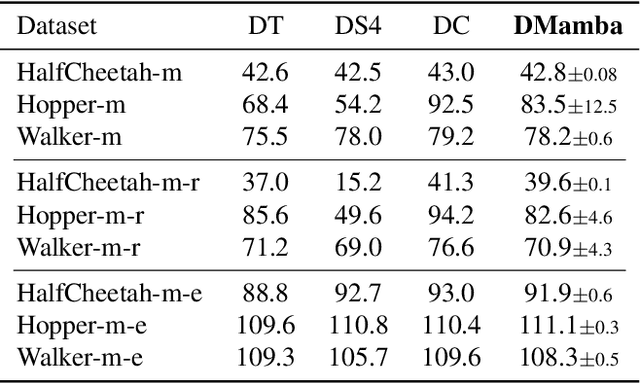
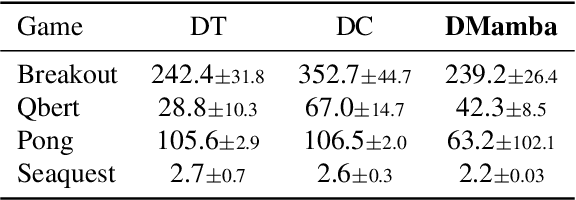
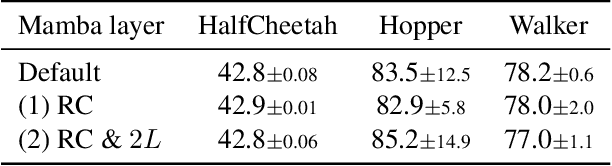
Decision Transformer, a promising approach that applies Transformer architectures to reinforcement learning, relies on causal self-attention to model sequences of states, actions, and rewards. While this method has shown competitive results, this paper investigates the integration of the Mamba framework, known for its advanced capabilities in efficient and effective sequence modeling, into the Decision Transformer architecture, focusing on the potential performance enhancements in sequential decision-making tasks. Our study systematically evaluates this integration by conducting a series of experiments across various decision-making environments, comparing the modified Decision Transformer, Decision Mamba, with its traditional counterpart. This work contributes to the advancement of sequential decision-making models, suggesting that the architecture and training methodology of neural networks can significantly impact their performance in complex tasks, and highlighting the potential of Mamba as a valuable tool for improving the efficacy of Transformer-based models in reinforcement learning scenarios.
iMixer: hierarchical Hopfield network implies an invertible, implicit and iterative MLP-Mixer
Apr 25, 2023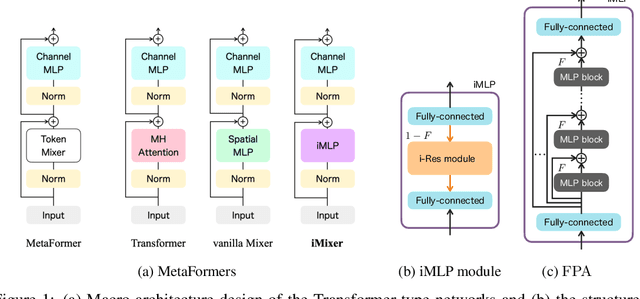

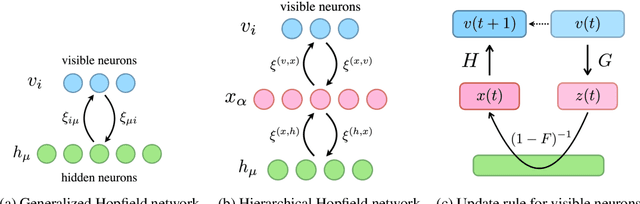
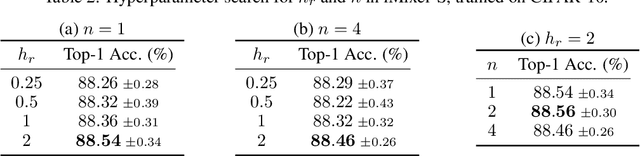
In the last few years, the success of Transformers in computer vision has stimulated the discovery of many alternative models that compete with Transformers, such as the MLP-Mixer. Despite their weak induced bias, these models have achieved performance comparable to well-studied convolutional neural networks. Recent studies on modern Hopfield networks suggest the correspondence between certain energy-based associative memory models and Transformers or MLP-Mixer, and shed some light on the theoretical background of the Transformer-type architectures design. In this paper we generalize the correspondence to the recently introduced hierarchical Hopfield network, and find iMixer, a novel generalization of MLP-Mixer model. Unlike ordinary feedforward neural networks, iMixer involves MLP layers that propagate forward from the output side to the input side. We characterize the module as an example of invertible, implicit, and iterative mixing module. We evaluate the model performance with various datasets on image classification tasks, and find that iMixer reasonably achieves the improvement compared to the baseline vanilla MLP-Mixer. The results imply that the correspondence between the Hopfield networks and the Mixer models serves as a principle for understanding a broader class of Transformer-like architecture designs.
Attention in a family of Boltzmann machines emerging from modern Hopfield networks
Dec 09, 2022Hopfield networks and Boltzmann machines (BMs) are fundamental energy-based neural network models. Recent studies on modern Hopfield networks have broaden the class of energy functions and led to a unified perspective on general Hopfield networks including an attention module. In this letter, we consider the BM counterparts of modern Hopfield networks using the associated energy functions, and study their salient properties from a trainability perspective. In particular, the energy function corresponding to the attention module naturally introduces a novel BM, which we refer to as attentional BM (AttnBM). We verify that AttnBM has a tractable likelihood function and gradient for a special case and is easy to train. Moreover, we reveal the hidden connections between AttnBM and some single-layer models, namely the Gaussian--Bernoulli restricted BM and denoising autoencoder with softmax units. We also investigate BMs introduced by other energy functions, and in particular, observe that the energy function of dense associative memory models gives BMs belonging to Exponential Family Harmoniums.