 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiMixer: hierarchical Hopfield network implies an invertible, implicit and iterative MLP-Mixer
Paper and Code
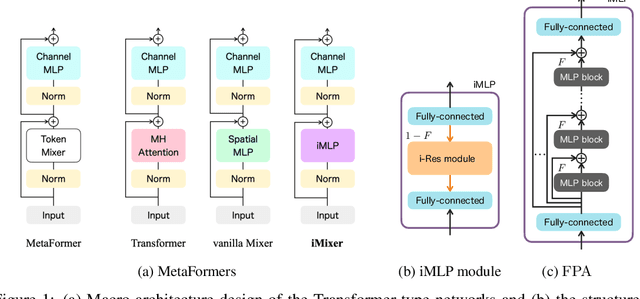

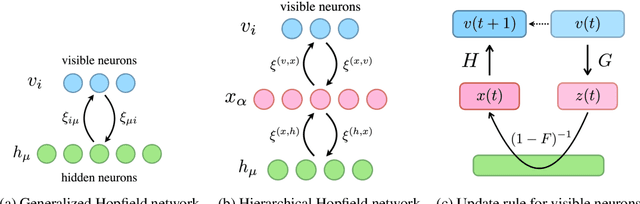
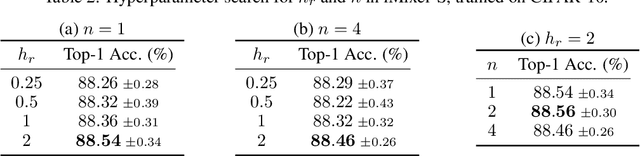
In the last few years, the success of Transformers in computer vision has stimulated the discovery of many alternative models that compete with Transformers, such as the MLP-Mixer. Despite their weak induced bias, these models have achieved performance comparable to well-studied convolutional neural networks. Recent studies on modern Hopfield networks suggest the correspondence between certain energy-based associative memory models and Transformers or MLP-Mixer, and shed some light on the theoretical background of the Transformer-type architectures design. In this paper we generalize the correspondence to the recently introduced hierarchical Hopfield network, and find iMixer, a novel generalization of MLP-Mixer model. Unlike ordinary feedforward neural networks, iMixer involves MLP layers that propagate forward from the output side to the input side. We characterize the module as an example of invertible, implicit, and iterative mixing module. We evaluate the model performance with various datasets on image classification tasks, and find that iMixer reasonably achieves the improvement compared to the baseline vanilla MLP-Mixer. The results imply that the correspondence between the Hopfield networks and the Mixer models serves as a principle for understanding a broader class of Transformer-like architecture designs.