 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Associative Memory, Parallelized MLP-Mixer, and Symmetry Breaking
Jun 18, 2024Transformers have established themselves as the leading neural network model in natural language processing and are increasingly foundational in various domains. In vision, the MLP-Mixer model has demonstrated competitive performance, suggesting that attention mechanisms might not be indispensable. Inspired by this, recent research has explored replacing attention modules with other mechanisms, including those described by MetaFormers. However, the theoretical framework for these models remains underdeveloped. This paper proposes a novel perspective by integrating Krotov's hierarchical associative memory with MetaFormers, enabling a comprehensive representation of the entire Transformer block, encompassing token-/channel-mixing modules, layer normalization, and skip connections, as a single Hopfield network. This approach yields a parallelized MLP-Mixer derived from a three-layer Hopfield network, which naturally incorporates symmetric token-/channel-mixing modules and layer normalization. Empirical studies reveal that symmetric interaction matrices in the model hinder performance in image recognition tasks. Introducing symmetry-breaking effects transitions the performance of the symmetric parallelized MLP-Mixer to that of the vanilla MLP-Mixer. This indicates that during standard training, weight matrices of the vanilla MLP-Mixer spontaneously acquire a symmetry-breaking configuration, enhancing their effectiveness. These findings offer insights into the intrinsic properties of Transformers and MLP-Mixers and their theoretical underpinnings, providing a robust framework for future model design and optimization.
CAM Back Again: Large Kernel CNNs from a Weakly Supervised Object Localization Perspective
Mar 11, 2024Recently, convolutional neural networks (CNNs) with large size kernels have attracted much attention in the computer vision field, following the success of the Vision Transformers. Large kernel CNNs have been reported to perform well in downstream vision tasks as well as in classification performance. The reason for the high-performance of large kernel CNNs in downstream tasks has been attributed to the large effective receptive field (ERF) produced by large size kernels, but this view has not been fully tested. We therefore revisit the performance of large kernel CNNs in downstream task, focusing on the weakly supervised object localization (WSOL) task. WSOL, a difficult downstream task that is not fully supervised, provides a new angle to explore the capabilities of the large kernel CNNs. Our study compares the modern large kernel CNNs ConvNeXt, RepLKNet, and SLaK to test the validity of the naive expectation that ERF size is important for improving downstream task performance. Our analysis of the factors contributing to high performance provides a different perspective, in which the main factor is feature map improvement. Furthermore, we find that modern CNNs are robust to the CAM problems of local regions of objects being activated, which has long been discussed in WSOL. CAM is the most classic WSOL method, but because of the above-mentioned problems, it is often used as a baseline method for comparison. However, experiments on the CUB-200-2011 dataset show that simply combining a large kernel CNN, CAM, and simple data augmentation methods can achieve performance (90.99% MaxBoxAcc) comparable to the latest WSOL method, which is CNN-based and requires special training or complex post-processing. The code is available at https://github.com/snskysk/CAM-Back-Again.
iMixer: hierarchical Hopfield network implies an invertible, implicit and iterative MLP-Mixer
Apr 25, 2023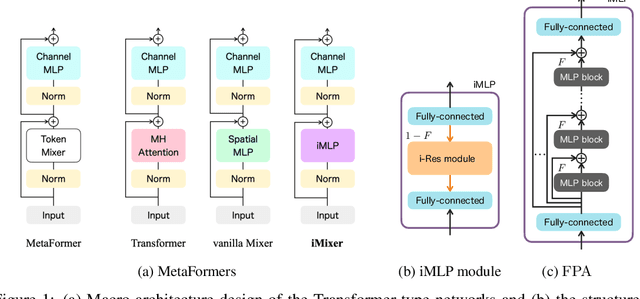

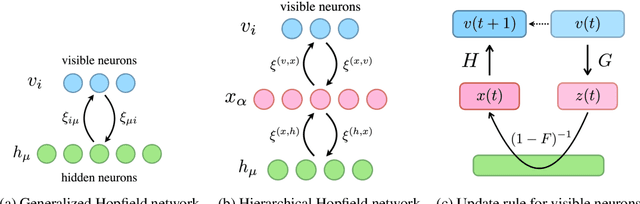
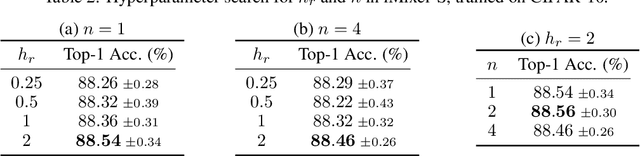
In the last few years, the success of Transformers in computer vision has stimulated the discovery of many alternative models that compete with Transformers, such as the MLP-Mixer. Despite their weak induced bias, these models have achieved performance comparable to well-studied convolutional neural networks. Recent studies on modern Hopfield networks suggest the correspondence between certain energy-based associative memory models and Transformers or MLP-Mixer, and shed some light on the theoretical background of the Transformer-type architectures design. In this paper we generalize the correspondence to the recently introduced hierarchical Hopfield network, and find iMixer, a novel generalization of MLP-Mixer model. Unlike ordinary feedforward neural networks, iMixer involves MLP layers that propagate forward from the output side to the input side. We characterize the module as an example of invertible, implicit, and iterative mixing module. We evaluate the model performance with various datasets on image classification tasks, and find that iMixer reasonably achieves the improvement compared to the baseline vanilla MLP-Mixer. The results imply that the correspondence between the Hopfield networks and the Mixer models serves as a principle for understanding a broader class of Transformer-like architecture designs.
FFT-based Dynamic Token Mixer for Vision
Mar 07, 2023Multi-head-self-attention (MHSA)-equipped models have achieved notable performance in computer vision. Their computational complexity is proportional to quadratic numbers of pixels in input feature maps, resulting in slow processing, especially when dealing with high-resolution images. New types of token-mixer are proposed as an alternative to MHSA to circumvent this problem: an FFT-based token-mixer, similar to MHSA in global operation but with lower computational complexity. However, despite its attractive properties, the FFT-based token-mixer has not been carefully examined in terms of its compatibility with the rapidly evolving MetaFormer architecture. Here, we propose a novel token-mixer called dynamic filter and DFFormer and CDFFormer, image recognition models using dynamic filters to close the gaps above. CDFFormer achieved a Top-1 accuracy of 85.0%, close to the hybrid architecture with convolution and MHSA. Other wide-ranging experiments and analysis, including object detection and semantic segmentation, demonstrate that they are competitive with state-of-the-art architectures; Their throughput and memory efficiency when dealing with high-resolution image recognition is convolution and MHSA, not much different from ConvFormer, and far superior to CAFormer. Our results indicate that the dynamic filter is one of the token-mixer options that should be seriously considered. The code is available at https://github.com/okojoalg/dfformer
Example-Based Explainable AI and its Application for Remote Sensing Image Classification
Feb 03, 2023



We present a method of explainable artificial intelligence (XAI), "What I Know (WIK)", to provide additional information to verify the reliability of a deep learning model by showing an example of an instance in a training dataset that is similar to the input data to be inferred and demonstrate it in a remote sensing image classification task. One of the expected roles of XAI methods is verifying whether inferences of a trained machine learning model are valid for an application, and it is an important factor that what datasets are used for training the model as well as the model architecture. Our data-centric approach can help determine whether the training dataset is sufficient for each inference by checking the selected example data. If the selected example looks similar to the input data, we can confirm that the model was not trained on a dataset with a feature distribution far from the feature of the input data. With this method, the criteria for selecting an example are not merely data similarity with the input data but also data similarity in the context of the model task. Using a remote sensing image dataset from the Sentinel-2 satellite, the concept was successfully demonstrated with reasonably selected examples. This method can be applied to various machine-learning tasks, including classification and regression.
Sequencer: Deep LSTM for Image Classification
May 17, 2022In recent computer vision research, the advent of the Vision Transformer (ViT) has rapidly revolutionized various architectural design efforts: ViT achieved state-of-the-art image classification performance using self-attention found in natural language processing, and MLP-Mixer achieved competitive performance using simple multi-layer perceptrons. In contrast, several studies have also suggested that carefully redesigned convolutional neural networks (CNNs) can achieve advanced performance comparable to ViT without resorting to these new ideas. Against this background, there is growing interest in what inductive bias is suitable for computer vision. Here we propose Sequencer, a novel and competitive architecture alternative to ViT that provides a new perspective on these issues. Unlike ViTs, Sequencer models long-range dependencies using LSTMs rather than self-attention layers. We also propose a two-dimensional version of Sequencer module, where an LSTM is decomposed into vertical and horizontal LSTMs to enhance performance. Despite its simplicity, several experiments demonstrate that Sequencer performs impressively well: Sequencer2D-L, with 54M parameters, realizes 84.6% top-1 accuracy on only ImageNet-1K. Not only that, we show that it has good transferability and the robust resolution adaptability on double resolution-band.
Application of QUBO solver using black-box optimization to structural design for resonance avoidance
Apr 11, 2022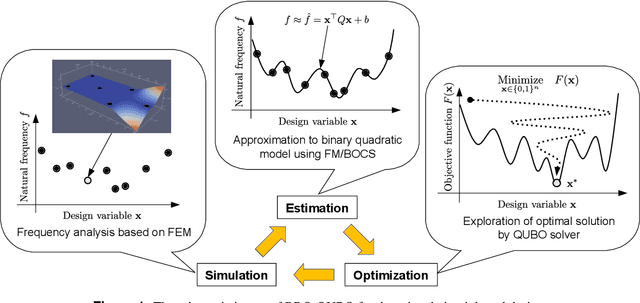


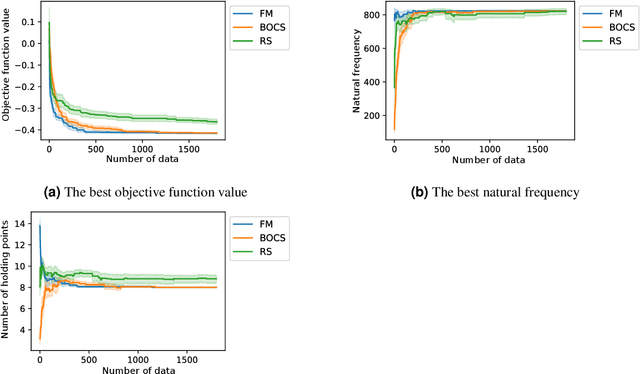
Quadratic unconstrained binary optimization (QUBO) solvers can be applied to design an optimal structure to avoid resonance. QUBO algorithms that work on a classical or quantum device have succeeded in some industrial applications. However, their applications are still limited due to the difficulty of transforming from the original optimization problem to QUBO. Recently, black-box optimization (BBO) methods have been proposed to tackle this issue using a machine learning technique and a Bayesian treatment for combinatorial optimization. We employed the BBO methods to design a printed circuit board for resonance avoidance. This design problem is formulated to maximize natural frequency and simultaneously minimize the number of mounting points. The natural frequency, which is the bottleneck for the QUBO formulation, is approximated to a quadratic model in the BBO method. We demonstrated that BBO using a factorization machine shows good performance in both the calculation time and the success probability of finding the optimal solution. Our results can open up QUBO solvers' potential for other applications in structural designs.
Counterfactual Explanation of Brain Activity Classifiers using Image-to-Image Transfer by Generative Adversarial Network
Oct 28, 2021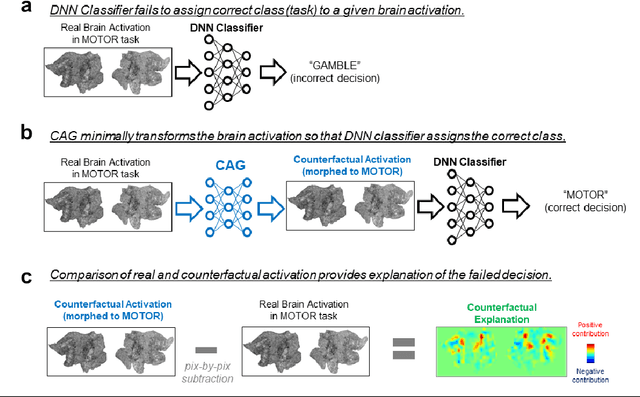
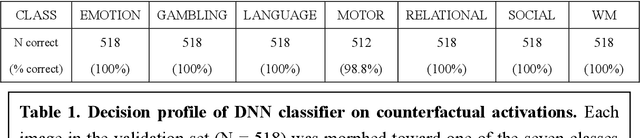


Deep neural networks (DNNs) can accurately decode task-related information from brain activations. However, because of the nonlinearity of the DNN, the decisions made by DNNs are hardly interpretable. One of the promising approaches for explaining such a black-box system is counterfactual explanation. In this framework, the behavior of a black-box system is explained by comparing real data and realistic synthetic data that are specifically generated such that the black-box system outputs an unreal outcome. Here we introduce a novel generative DNN (counterfactual activation generator, CAG) that can provide counterfactual explanations for DNN-based classifiers of brain activations. Importantly, CAG can simultaneously handle image transformation among multiple classes associated with different behavioral tasks. Using CAG, we demonstrated counterfactual explanation of DNN-based classifiers that learned to discriminate brain activations of seven behavioral tasks. Furthermore, by iterative applications of CAG, we were able to enhance and extract subtle spatial brain activity patterns that affected the classifier's decisions. Together, these results demonstrate that the counterfactual explanation based on image-to-image transformation would be a promising approach to understand and extend the current application of DNNs in fMRI analyses.
RaftMLP: Do MLP-based Models Dream of Winning Over Computer Vision?
Aug 09, 2021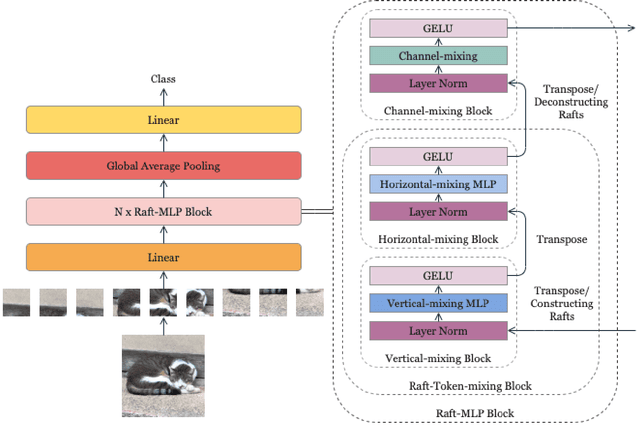
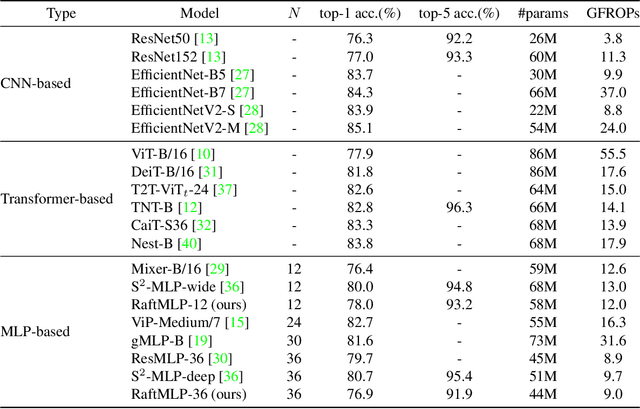
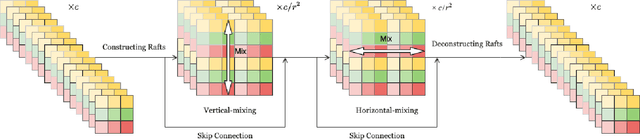
For the past ten years, CNN has reigned supreme in the world of computer vision, but recently, Transformer is on the rise. However, the quadratic computational cost of self-attention has become a severe problem of practice. There has been much research on architectures without CNN and self-attention in this context. In particular, MLP-Mixer is a simple idea designed using MLPs and hit an accuracy comparable to the Vision Transformer. However, the only inductive bias in this architecture is the embedding of tokens. Thus, there is still a possibility to build a non-convolutional inductive bias into the architecture itself, and we built in an inductive bias using two simple ideas. A way is to divide the token-mixing block vertically and horizontally. Another way is to make spatial correlations denser among some channels of token-mixing. With this approach, we were able to improve the accuracy of the MLP-Mixer while reducing its parameters and computational complexity. Compared to other MLP-based models, the proposed model, named RaftMLP has a good balance of computational complexity, the number of parameters, and actual memory usage. In addition, our work indicates that MLP-based models have the potential to replace CNNs by adopting inductive bias. The source code in PyTorch version is available at \url{https://github.com/okojoalg/raft-mlp}.
Deep Residual Networks and Weight Initialization
Sep 09, 2017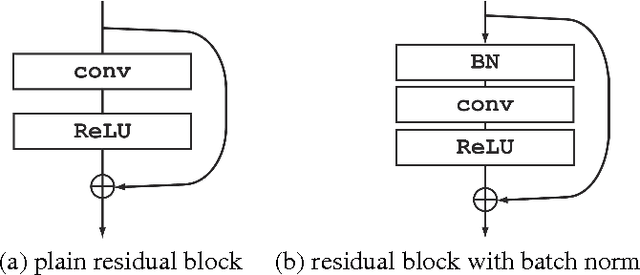
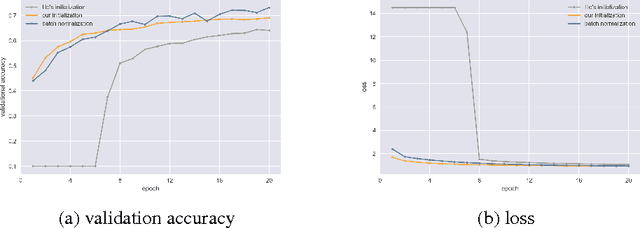
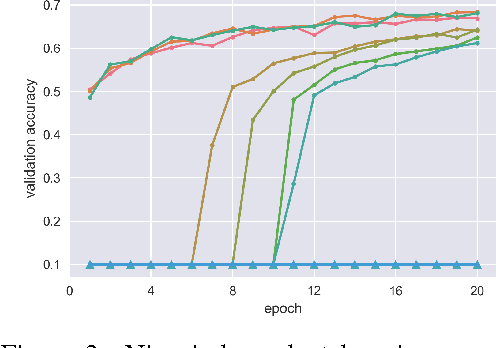
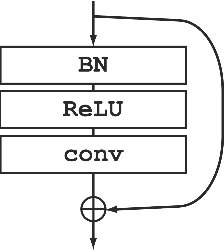
Residual Network (ResNet) is the state-of-the-art architecture that realizes successful training of really deep neural network. It is also known that good weight initialization of neural network avoids problem of vanishing/exploding gradients. In this paper, simplified models of ResNets are analyzed. We argue that goodness of ResNet is correlated with the fact that ResNets are relatively insensitive to choice of initial weights. We also demonstrate how batch normalization improves backpropagation of deep ResNets without tuning initial values of weights.