 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFFT-based Dynamic Token Mixer for Vision
Mar 07, 2023Multi-head-self-attention (MHSA)-equipped models have achieved notable performance in computer vision. Their computational complexity is proportional to quadratic numbers of pixels in input feature maps, resulting in slow processing, especially when dealing with high-resolution images. New types of token-mixer are proposed as an alternative to MHSA to circumvent this problem: an FFT-based token-mixer, similar to MHSA in global operation but with lower computational complexity. However, despite its attractive properties, the FFT-based token-mixer has not been carefully examined in terms of its compatibility with the rapidly evolving MetaFormer architecture. Here, we propose a novel token-mixer called dynamic filter and DFFormer and CDFFormer, image recognition models using dynamic filters to close the gaps above. CDFFormer achieved a Top-1 accuracy of 85.0%, close to the hybrid architecture with convolution and MHSA. Other wide-ranging experiments and analysis, including object detection and semantic segmentation, demonstrate that they are competitive with state-of-the-art architectures; Their throughput and memory efficiency when dealing with high-resolution image recognition is convolution and MHSA, not much different from ConvFormer, and far superior to CAFormer. Our results indicate that the dynamic filter is one of the token-mixer options that should be seriously considered. The code is available at https://github.com/okojoalg/dfformer
Sequencer: Deep LSTM for Image Classification
May 17, 2022In recent computer vision research, the advent of the Vision Transformer (ViT) has rapidly revolutionized various architectural design efforts: ViT achieved state-of-the-art image classification performance using self-attention found in natural language processing, and MLP-Mixer achieved competitive performance using simple multi-layer perceptrons. In contrast, several studies have also suggested that carefully redesigned convolutional neural networks (CNNs) can achieve advanced performance comparable to ViT without resorting to these new ideas. Against this background, there is growing interest in what inductive bias is suitable for computer vision. Here we propose Sequencer, a novel and competitive architecture alternative to ViT that provides a new perspective on these issues. Unlike ViTs, Sequencer models long-range dependencies using LSTMs rather than self-attention layers. We also propose a two-dimensional version of Sequencer module, where an LSTM is decomposed into vertical and horizontal LSTMs to enhance performance. Despite its simplicity, several experiments demonstrate that Sequencer performs impressively well: Sequencer2D-L, with 54M parameters, realizes 84.6% top-1 accuracy on only ImageNet-1K. Not only that, we show that it has good transferability and the robust resolution adaptability on double resolution-band.
RaftMLP: Do MLP-based Models Dream of Winning Over Computer Vision?
Aug 09, 2021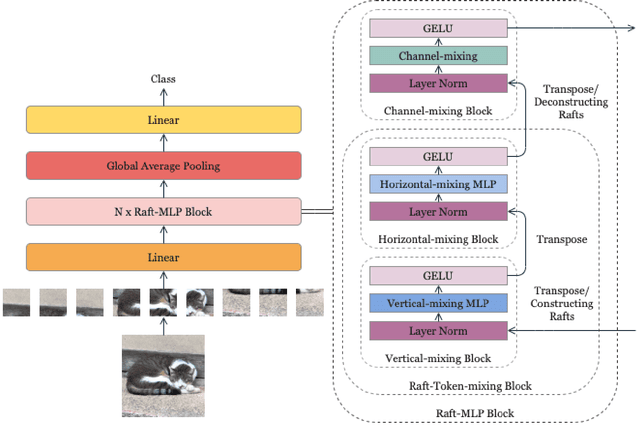
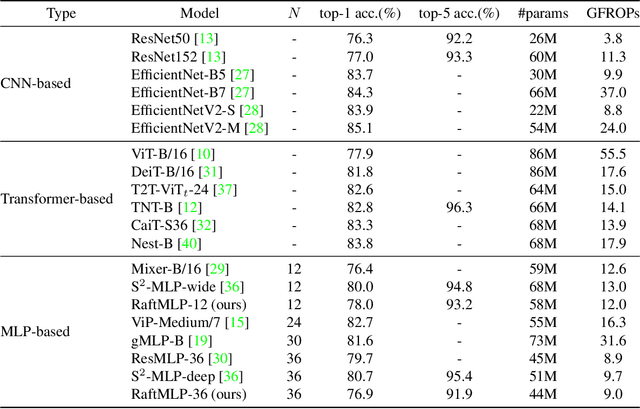
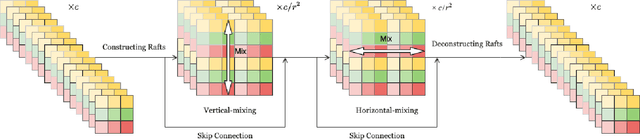
For the past ten years, CNN has reigned supreme in the world of computer vision, but recently, Transformer is on the rise. However, the quadratic computational cost of self-attention has become a severe problem of practice. There has been much research on architectures without CNN and self-attention in this context. In particular, MLP-Mixer is a simple idea designed using MLPs and hit an accuracy comparable to the Vision Transformer. However, the only inductive bias in this architecture is the embedding of tokens. Thus, there is still a possibility to build a non-convolutional inductive bias into the architecture itself, and we built in an inductive bias using two simple ideas. A way is to divide the token-mixing block vertically and horizontally. Another way is to make spatial correlations denser among some channels of token-mixing. With this approach, we were able to improve the accuracy of the MLP-Mixer while reducing its parameters and computational complexity. Compared to other MLP-based models, the proposed model, named RaftMLP has a good balance of computational complexity, the number of parameters, and actual memory usage. In addition, our work indicates that MLP-based models have the potential to replace CNNs by adopting inductive bias. The source code in PyTorch version is available at \url{https://github.com/okojoalg/raft-mlp}.