 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaftMLP: Do MLP-based Models Dream of Winning Over Computer Vision?
Paper and Code
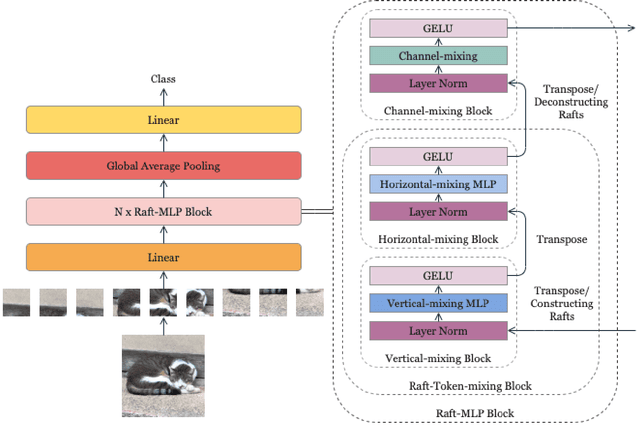
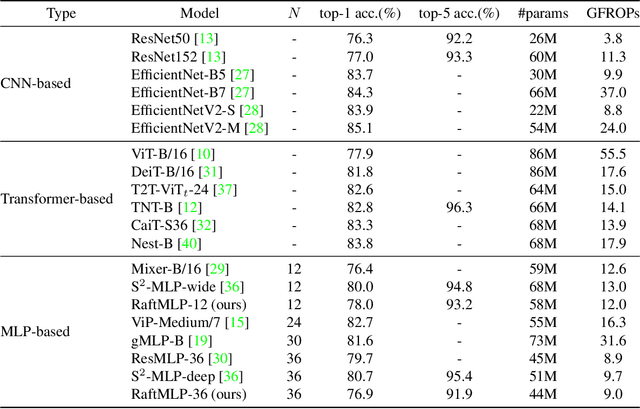
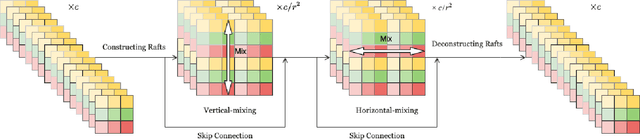
For the past ten years, CNN has reigned supreme in the world of computer vision, but recently, Transformer is on the rise. However, the quadratic computational cost of self-attention has become a severe problem of practice. There has been much research on architectures without CNN and self-attention in this context. In particular, MLP-Mixer is a simple idea designed using MLPs and hit an accuracy comparable to the Vision Transformer. However, the only inductive bias in this architecture is the embedding of tokens. Thus, there is still a possibility to build a non-convolutional inductive bias into the architecture itself, and we built in an inductive bias using two simple ideas. A way is to divide the token-mixing block vertically and horizontally. Another way is to make spatial correlations denser among some channels of token-mixing. With this approach, we were able to improve the accuracy of the MLP-Mixer while reducing its parameters and computational complexity. Compared to other MLP-based models, the proposed model, named RaftMLP has a good balance of computational complexity, the number of parameters, and actual memory usage. In addition, our work indicates that MLP-based models have the potential to replace CNNs by adopting inductive bias. The source code in PyTorch version is available at \url{https://github.com/okojoalg/raft-mlp}.