 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGloPath: An Entity-Centric Foundation Model for Glomerular Lesion Assessment and Clinicopathological Insights
Mar 03, 2026Glomerular pathology is central to the diagnosis and prognosis of renal diseases, yet the heterogeneity of glomerular morphology and fine-grained lesion patterns remain challenging for current AI approaches. We present GloPath, an entity-centric foundation model trained on over one million glomeruli extracted from 14,049 renal biopsy specimens using multi-scale and multi-view self-supervised learning. GloPath addresses two major challenges in nephropathology: glomerular lesion assessment and clinicopathological insights discovery. For lesion assessment, GloPath was benchmarked across three independent cohorts on 52 tasks, including lesion recognition, grading, few-shot classification, and cross-modality diagnosis-outperforming state-of-the-art methods in 42 tasks (80.8%). In the large-scale real-world study, it achieved an ROC-AUC of 91.51% for lesion recognition, demonstrating strong robustness in routine clinical settings. For clinicopathological insights, GloPath systematically revealed statistically significant associations between glomerular morphological parameters and clinical indicators across 224 morphology-clinical variable pairs, demonstrating its capacity to connect tissue-level pathology with patient-level outcomes. Together, these results position GloPath as a scalable and interpretable platform for glomerular lesion assessment and clinicopathological discovery, representing a step toward clinically translatable AI in renal pathology.
When LRP Diverges from Leave-One-Out in Transformers
Oct 21, 2025


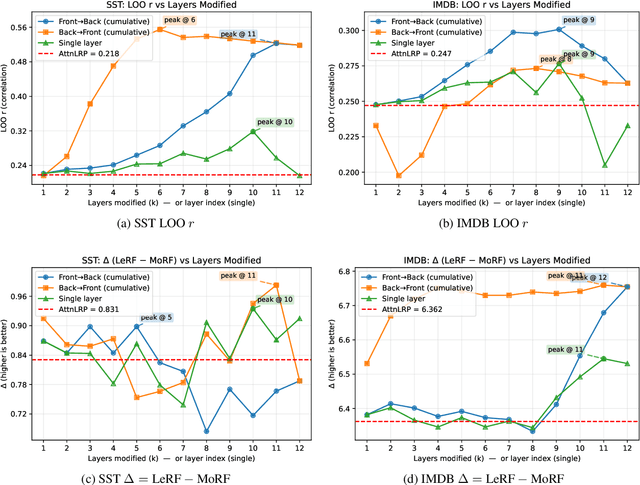
Leave-One-Out (LOO) provides an intuitive measure of feature importance but is computationally prohibitive. While Layer-Wise Relevance Propagation (LRP) offers a potentially efficient alternative, its axiomatic soundness in modern Transformers remains largely under-examined. In this work, we first show that the bilinear propagation rules used in recent advances of AttnLRP violate the implementation invariance axiom. We prove this analytically and confirm it empirically in linear attention layers. Second, we also revisit CP-LRP as a diagnostic baseline and find that bypassing relevance propagation through the softmax layer -- backpropagating relevance only through the value matrices -- significantly improves alignment with LOO, particularly in middle-to-late Transformer layers. Overall, our results suggest that (i) bilinear factorization sensitivity and (ii) softmax propagation error potentially jointly undermine LRP's ability to approximate LOO in Transformers.
MergeBench: A Benchmark for Merging Domain-Specialized LLMs
May 16, 2025Model merging provides a scalable alternative to multi-task training by combining specialized finetuned models through parameter arithmetic, enabling efficient deployment without the need for joint training or access to all task data. While recent methods have shown promise, existing evaluations are limited in both model scale and task diversity, leaving open questions about their applicability to large, domain-specialized LLMs. To tackle the challenges, we introduce MergeBench, a comprehensive evaluation suite designed to assess model merging at scale. MergeBench builds on state-of-the-art open-source language models, including Llama and Gemma families at 2B to 9B scales, and covers five key domains: instruction following, mathematics, multilingual understanding, coding and safety. We standardize finetuning and evaluation protocols, and assess eight representative merging methods across multi-task performance, forgetting and runtime efficiency. Based on extensive experiments, we provide practical guidelines for algorithm selection and share insights showing that model merging tends to perform better on stronger base models, with techniques such as merging coefficient tuning and sparsification improving knowledge retention. However, several challenges remain, including the computational cost on large models, the gap for in-domain performance compared to multi-task models, and the underexplored role of model merging in standard LLM training pipelines. We hope MergeBench provides a foundation for future research to advance the understanding and practical application of model merging. We open source our code at \href{https://github.com/uiuctml/MergeBench}{https://github.com/uiuctml/MergeBench}.
Efficient Model Editing with Task Vector Bases: A Theoretical Framework and Scalable Approach
Feb 03, 2025

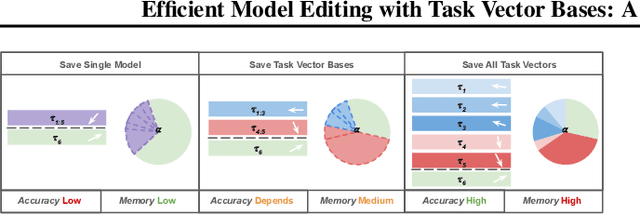

Task vectors, which are derived from the difference between pre-trained and fine-tuned model weights, enable flexible task adaptation and model merging through arithmetic operations such as addition and negation. However, existing approaches often rely on heuristics with limited theoretical support, often leading to performance gaps comparing to direct task fine tuning. Meanwhile, although it is easy to manipulate saved task vectors with arithmetic for different purposes, such compositional flexibility demands high memory usage, especially when dealing with a huge number of tasks, limiting scalability. This work addresses these issues with a theoretically grounded framework that explains task vector arithmetic and introduces the task vector bases framework. Building upon existing task arithmetic literature, our method significantly reduces the memory cost for downstream arithmetic with little effort, while achieving competitive performance and maintaining compositional advantage, providing a practical solution for large-scale task arithmetic.
FECT: Classification of Breast Cancer Pathological Images Based on Fusion Features
Jan 17, 2025



Breast cancer is one of the most common cancers among women globally, with early diagnosis and precise classification being crucial. With the advancement of deep learning and computer vision, the automatic classification of breast tissue pathological images has emerged as a research focus. Existing methods typically rely on singular cell or tissue features and lack design considerations for morphological characteristics of challenging-to-classify categories, resulting in suboptimal classification performance. To address these problems, we proposes a novel breast cancer tissue classification model that Fused features of Edges, Cells, and Tissues (FECT), employing the ResMTUNet and an attention-based aggregator to extract and aggregate these features. Extensive testing on the BRACS dataset demonstrates that our model surpasses current advanced methods in terms of classification accuracy and F1 scores. Moreover, due to its feature fusion that aligns with the diagnostic approach of pathologists, our model exhibits interpretability and holds promise for significant roles in future clinical applications.
Learning Structured Representations with Hyperbolic Embeddings
Dec 02, 2024


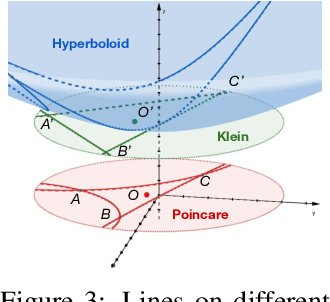
Most real-world datasets consist of a natural hierarchy between classes or an inherent label structure that is either already available or can be constructed cheaply. However, most existing representation learning methods ignore this hierarchy, treating labels as permutation invariant. Recent work [Zeng et al., 2022] proposes using this structured information explicitly, but the use of Euclidean distance may distort the underlying semantic context [Chen et al., 2013]. In this work, motivated by the advantage of hyperbolic spaces in modeling hierarchical relationships, we propose a novel approach HypStructure: a Hyperbolic Structured regularization approach to accurately embed the label hierarchy into the learned representations. HypStructure is a simple-yet-effective regularizer that consists of a hyperbolic tree-based representation loss along with a centering loss, and can be combined with any standard task loss to learn hierarchy-informed features. Extensive experiments on several large-scale vision benchmarks demonstrate the efficacy of HypStructure in reducing distortion and boosting generalization performance especially under low dimensional scenarios. For a better understanding of structured representation, we perform eigenvalue analysis that links the representation geometry to improved Out-of-Distribution (OOD) detection performance seen empirically. The code is available at \url{https://github.com/uiuctml/HypStructure}.
Learning Structured Representations by Embedding Class Hierarchy with Fast Optimal Transport
Oct 04, 2024To embed structured knowledge within labels into feature representations, prior work (Zeng et al., 2022) proposed to use the Cophenetic Correlation Coefficient (CPCC) as a regularizer during supervised learning. This regularizer calculates pairwise Euclidean distances of class means and aligns them with the corresponding shortest path distances derived from the label hierarchy tree. However, class means may not be good representatives of the class conditional distributions, especially when they are multi-mode in nature. To address this limitation, under the CPCC framework, we propose to use the Earth Mover's Distance (EMD) to measure the pairwise distances among classes in the feature space. We show that our exact EMD method generalizes previous work, and recovers the existing algorithm when class-conditional distributions are Gaussian in the feature space. To further improve the computational efficiency of our method, we introduce the Optimal Transport-CPCC family by exploring four EMD approximation variants. Our most efficient OT-CPCC variant runs in linear time in the size of the dataset, while maintaining competitive performance across datasets and tasks.
RELand: Risk Estimation of Landmines via Interpretable Invariant Risk Minimization
Nov 06, 2023
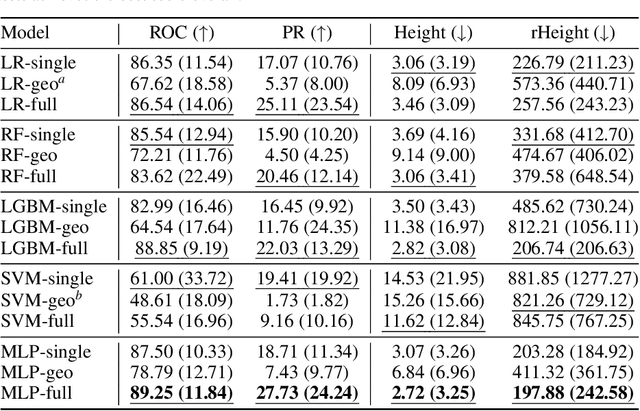

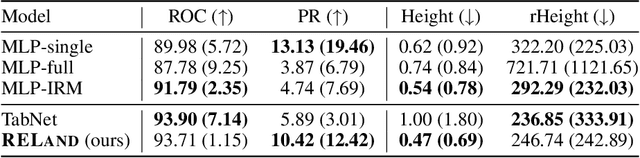
Landmines remain a threat to war-affected communities for years after conflicts have ended, partly due to the laborious nature of demining tasks. Humanitarian demining operations begin by collecting relevant information from the sites to be cleared, which is then analyzed by human experts to determine the potential risk of remaining landmines. In this paper, we propose RELand system to support these tasks, which consists of three major components. We (1) provide general feature engineering and label assigning guidelines to enhance datasets for landmine risk modeling, which are widely applicable to global demining routines, (2) formulate landmine presence as a classification problem and design a novel interpretable model based on sparse feature masking and invariant risk minimization, and run extensive evaluation under proper protocols that resemble real-world demining operations to show a significant improvement over the state-of-the-art, and (3) build an interactive web interface to suggest priority areas for demining organizations. We are currently collaborating with a humanitarian demining NGO in Colombia that is using our system as part of their field operations in two areas recently prioritized for demining.