 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Large Language Model for Visual Navigation
Oct 12, 2023Recent efforts to enable visual navigation using large language models have mainly focused on developing complex prompt systems. These systems incorporate instructions, observations, and history into massive text prompts, which are then combined with pre-trained large language models to facilitate visual navigation. In contrast, our approach aims to fine-tune large language models for visual navigation without extensive prompt engineering. Our design involves a simple text prompt, current observations, and a history collector model that gathers information from previous observations as input. For output, our design provides a probability distribution of possible actions that the agent can take during navigation. We train our model using human demonstrations and collision signals from the Habitat-Matterport 3D Dataset (HM3D). Experimental results demonstrate that our method outperforms state-of-the-art behavior cloning methods and effectively reduces collision rates.
3DFR: A Swift 3D Feature Reductionist Framework for Scene Independent Change Detection
Dec 26, 2019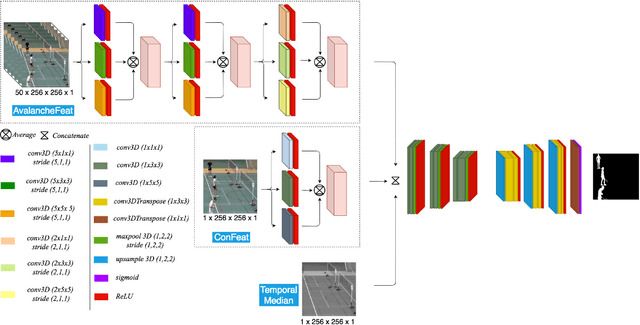

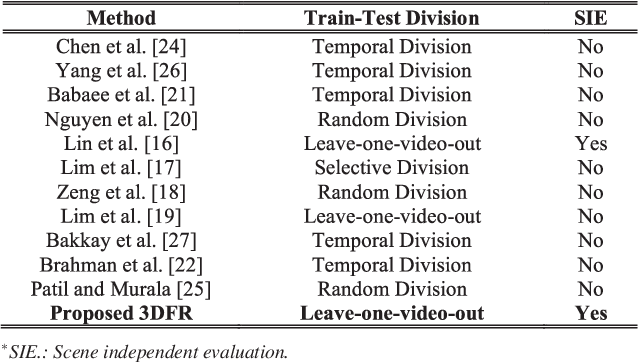
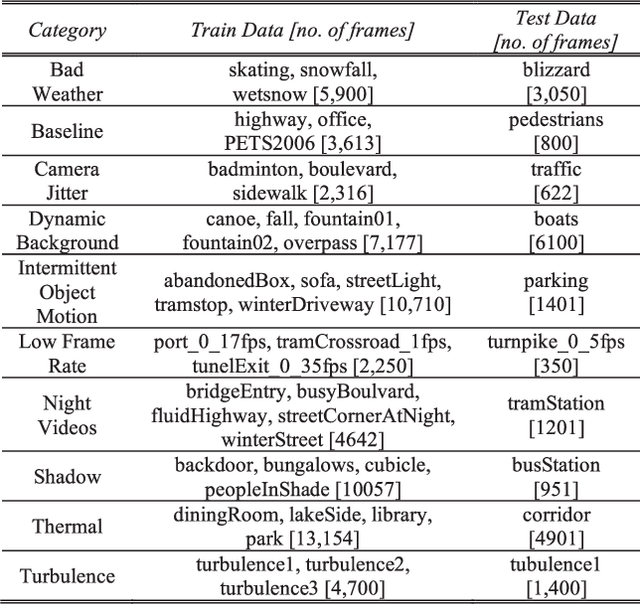
In this paper we propose an end-to-end swift 3D feature reductionist framework (3DFR) for scene independent change detection. The 3DFR framework consists of three feature streams: a swift 3D feature reductionist stream (AvFeat), a contemporary feature stream (ConFeat) and a temporal median feature map. These multilateral foreground/background features are further refined through an encoder-decoder network. As a result, the proposed framework not only detects temporal changes but also learns high-level appearance features. Thus, it incorporates the object semantics for effective change detection. Furthermore, the proposed framework is validated through a scene independent evaluation scheme in order to demonstrate the robustness and generalization capability of the network. The performance of the proposed method is evaluated on the benchmark CDnet 2014 dataset. The experimental results show that the proposed 3DFR network outperforms the state-of-the-art approaches.
* IEEE Signal Processing Letters