 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Phaseformer: Phase-based Attention Mechanism for Underwater Image Restoration and Beyond
Dec 02, 2024



Quality degradation is observed in underwater images due to the effects of light refraction and absorption by water, leading to issues like color cast, haziness, and limited visibility. This degradation negatively affects the performance of autonomous underwater vehicles used in marine applications. To address these challenges, we propose a lightweight phase-based transformer network with 1.77M parameters for underwater image restoration (UIR). Our approach focuses on effectively extracting non-contaminated features using a phase-based self-attention mechanism. We also introduce an optimized phase attention block to restore structural information by propagating prominent attentive features from the input. We evaluate our method on both synthetic (UIEB, UFO-120) and real-world (UIEB, U45, UCCS, SQUID) underwater image datasets. Additionally, we demonstrate its effectiveness for low-light image enhancement using the LOL dataset. Through extensive ablation studies and comparative analysis, it is clear that the proposed approach outperforms existing state-of-the-art (SOTA) methods.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024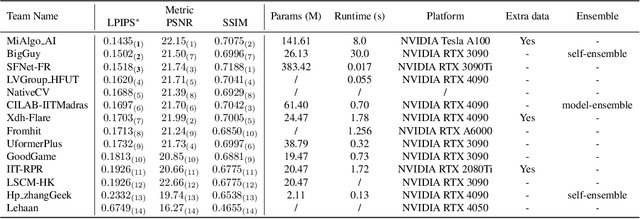
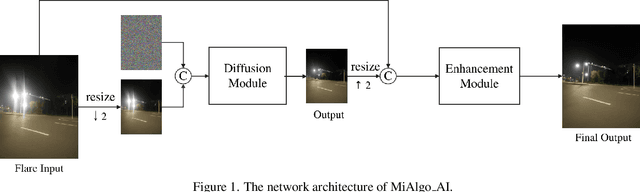
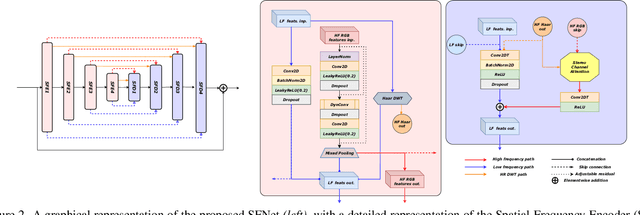
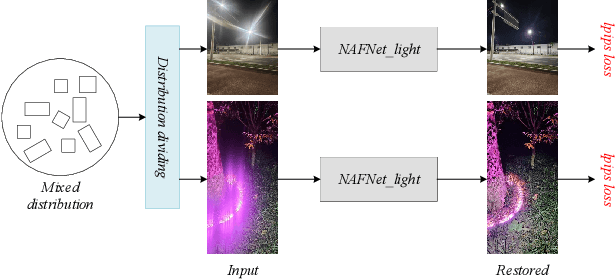
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Efficient Neural Architecture Search for Emotion Recognition
Mar 23, 2023



Automated human emotion recognition from facial expressions is a well-studied problem and still remains a very challenging task. Some efficient or accurate deep learning models have been presented in the literature. However, it is quite difficult to design a model that is both efficient and accurate at the same time. Moreover, identifying the minute feature variations in facial regions for both macro and micro-expressions requires expertise in network design. In this paper, we proposed to search for a highly efficient and robust neural architecture for both macro and micro-level facial expression recognition. To the best of our knowledge, this is the first attempt to design a NAS-based solution for both macro and micro-expression recognition. We produce lightweight models with a gradient-based architecture search algorithm. To maintain consistency between macro and micro-expressions, we utilize dynamic imaging and convert microexpression sequences into a single frame, preserving the spatiotemporal features in the facial regions. The EmoNAS has evaluated over 13 datasets (7 macro expression datasets: CK+, DISFA, MUG, ISED, OULU-VIS CASIA, FER2013, RAF-DB, and 6 micro-expression datasets: CASME-I, CASME-II, CAS(ME)2, SAMM, SMIC, MEGC2019 challenge). The proposed models outperform the existing state-of-the-art methods and perform very well in terms of speed and space complexity.
Deep Insights of Learning based Micro Expression Recognition: A Perspective on Promises, Challenges and Research Needs
Oct 10, 2022



Micro expression recognition (MER) is a very challenging area of research due to its intrinsic nature and fine-grained changes. In the literature, the problem of MER has been solved through handcrafted/descriptor-based techniques. However, in recent times, deep learning (DL) based techniques have been adopted to gain higher performance for MER. Also, rich survey articles on MER are available by summarizing the datasets, experimental settings, conventional and deep learning methods. In contrast, these studies lack the ability to convey the impact of network design paradigms and experimental setting strategies for DL-based MER. Therefore, this paper aims to provide a deep insight into the DL-based MER frameworks with a perspective on promises in network model designing, experimental strategies, challenges, and research needs. Also, the detailed categorization of available MER frameworks is presented in various aspects of model design and technical characteristics. Moreover, an empirical analysis of the experimental and validation protocols adopted by MER methods is presented. The challenges mentioned earlier and network design strategies may assist the affective computing research community in forging ahead in MER research. Finally, we point out the future directions, research needs, and draw our conclusions.
RARITYNet: Rarity Guided Affective Emotion Learning Framework
May 17, 2022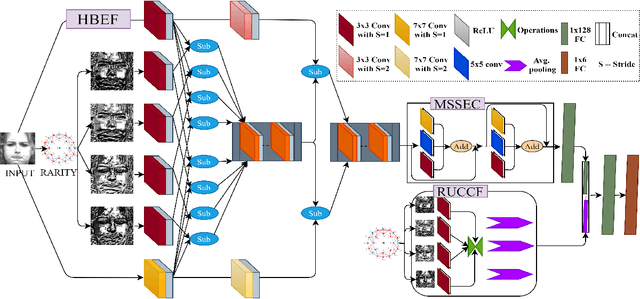
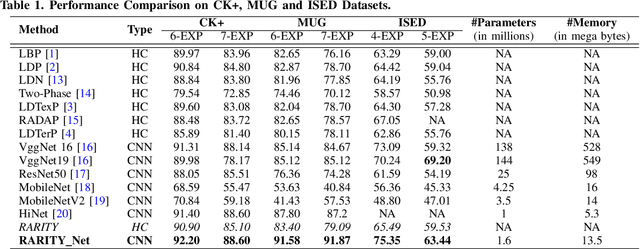
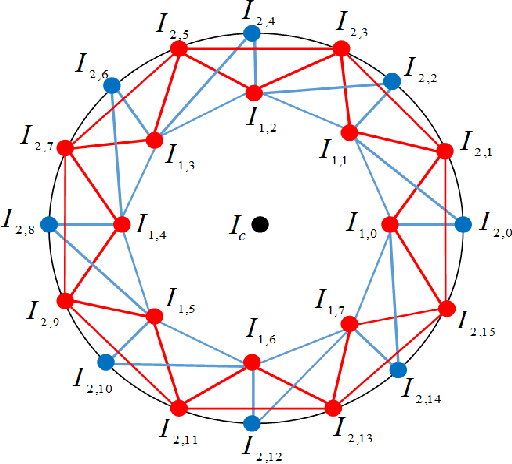
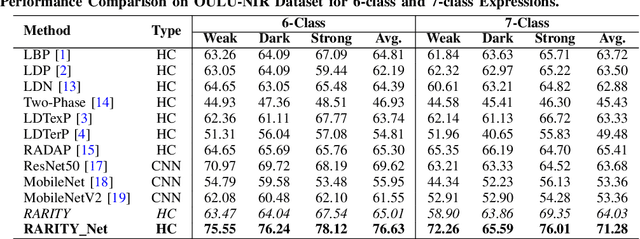
Inspired from the assets of handcrafted and deep learning approaches, we proposed a RARITYNet: RARITY guided affective emotion learning framework to learn the appearance features and identify the emotion class of facial expressions. The RARITYNet framework is designed by combining the shallow (RARITY) and deep (AffEmoNet) features to recognize the facial expressions from challenging images as spontaneous expressions, pose variations, ethnicity changes, and illumination conditions. The RARITY is proposed to encode the inter-radial transitional patterns in the local neighbourhood. The AffEmoNet: affective emotion learning network is proposed by incorporating three feature streams: high boost edge filtering (HBSEF) stream, to extract the edge information of highly affected facial expressive regions, multi-scale sophisticated edge cumulative (MSSEC) stream is to learns the sophisticated edge information from multi-receptive fields and RARITY uplift complementary context feature (RUCCF) stream refines the RARITY-encoded features and aid the MSSEC stream features to enrich the learning ability of RARITYNet.
Cross-Centroid Ripple Pattern for Facial Expression Recognition
Jan 16, 2022



In this paper, we propose a new feature descriptor Cross-Centroid Ripple Pattern (CRIP) for facial expression recognition. CRIP encodes the transitional pattern of a facial expression by incorporating cross-centroid relationship between two ripples located at radius r1 and r2 respectively. These ripples are generated by dividing the local neighborhood region into subregions. Thus, CRIP has ability to preserve macro and micro structural variations in an extensive region, which enables it to deal with side views and spontaneous expressions. Furthermore, gradient information between cross centroid ripples provides strenght to captures prominent edge features in active patches: eyes, nose and mouth, that define the disparities between different facial expressions. Cross centroid information also provides robustness to irregular illumination. Moreover, CRIP utilizes the averaging behavior of pixels at subregions that yields robustness to deal with noisy conditions. The performance of proposed descriptor is evaluated on seven comprehensive expression datasets consisting of challenging conditions such as age, pose, ethnicity and illumination variations. The experimental results show that our descriptor consistently achieved better accuracy rate as compared to existing state-of-art approaches.
An Empirical Review of Deep Learning Frameworks for Change Detection: Model Design, Experimental Frameworks, Challenges and Research Needs
May 04, 2021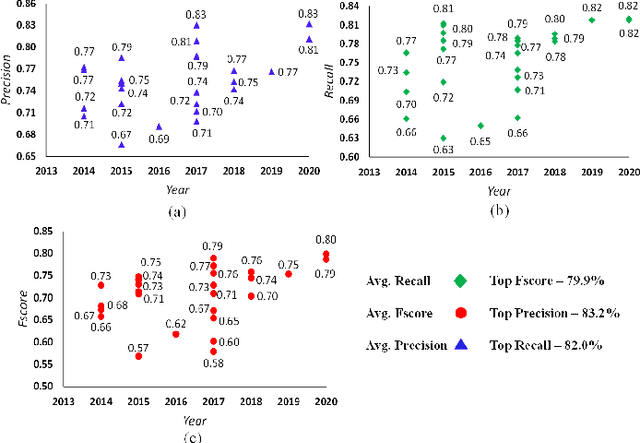
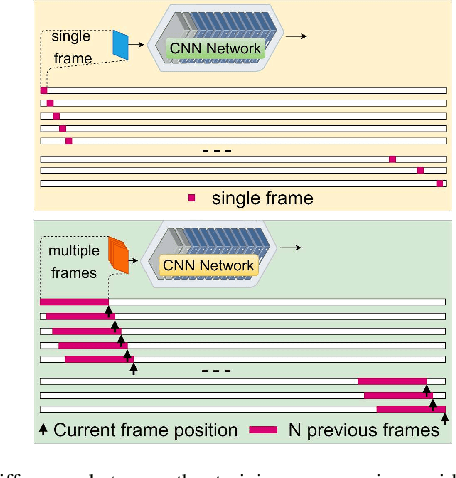
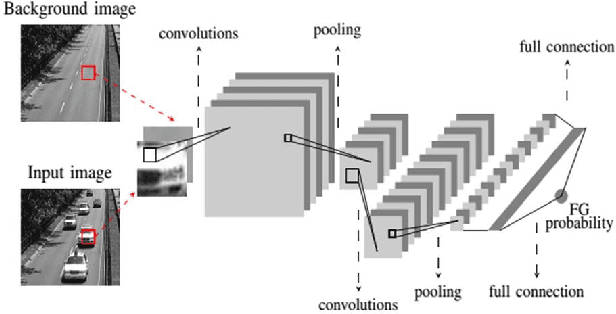
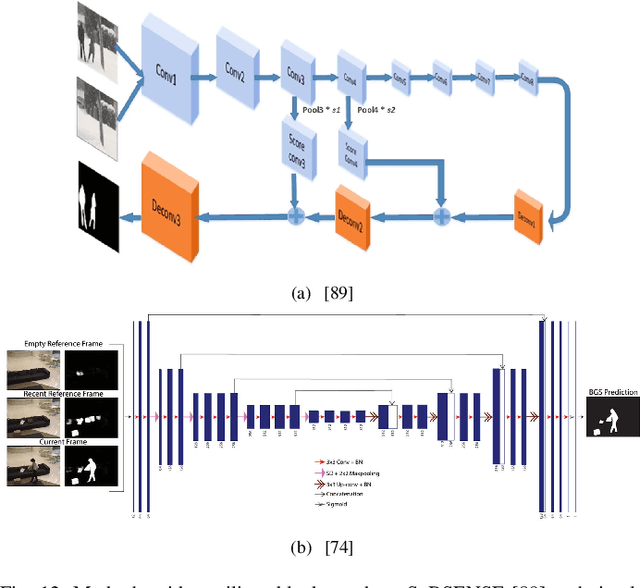
Visual change detection, aiming at segmentation of video frames into foreground and background regions, is one of the elementary tasks in computer vision and video analytics. The applications of change detection include anomaly detection, object tracking, traffic monitoring, human machine interaction, behavior analysis, action recognition, and visual surveillance. Some of the challenges in change detection include background fluctuations, illumination variation, weather changes, intermittent object motion, shadow, fast/slow object motion, camera motion, heterogeneous object shapes and real-time processing. Traditionally, this problem has been solved using hand-crafted features and background modelling techniques. In recent years, deep learning frameworks have been successfully adopted for robust change detection. This article aims to provide an empirical review of the state-of-the-art deep learning methods for change detection. More specifically, we present a detailed analysis of the technical characteristics of different model designs and experimental frameworks. We provide model design based categorization of the existing approaches, including the 2D-CNN, 3D-CNN, ConvLSTM, multi-scale features, residual connections, autoencoders and GAN based methods. Moreover, an empirical analysis of the evaluation settings adopted by the existing deep learning methods is presented. To the best of our knowledge, this is a first attempt to comparatively analyze the different evaluation frameworks used in the existing deep change detection methods. Finally, we point out the research needs, future directions and draw our own conclusions.