 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Insights of Learning based Micro Expression Recognition: A Perspective on Promises, Challenges and Research Needs
Oct 10, 2022



Micro expression recognition (MER) is a very challenging area of research due to its intrinsic nature and fine-grained changes. In the literature, the problem of MER has been solved through handcrafted/descriptor-based techniques. However, in recent times, deep learning (DL) based techniques have been adopted to gain higher performance for MER. Also, rich survey articles on MER are available by summarizing the datasets, experimental settings, conventional and deep learning methods. In contrast, these studies lack the ability to convey the impact of network design paradigms and experimental setting strategies for DL-based MER. Therefore, this paper aims to provide a deep insight into the DL-based MER frameworks with a perspective on promises in network model designing, experimental strategies, challenges, and research needs. Also, the detailed categorization of available MER frameworks is presented in various aspects of model design and technical characteristics. Moreover, an empirical analysis of the experimental and validation protocols adopted by MER methods is presented. The challenges mentioned earlier and network design strategies may assist the affective computing research community in forging ahead in MER research. Finally, we point out the future directions, research needs, and draw our conclusions.
Cross-Centroid Ripple Pattern for Facial Expression Recognition
Jan 16, 2022



In this paper, we propose a new feature descriptor Cross-Centroid Ripple Pattern (CRIP) for facial expression recognition. CRIP encodes the transitional pattern of a facial expression by incorporating cross-centroid relationship between two ripples located at radius r1 and r2 respectively. These ripples are generated by dividing the local neighborhood region into subregions. Thus, CRIP has ability to preserve macro and micro structural variations in an extensive region, which enables it to deal with side views and spontaneous expressions. Furthermore, gradient information between cross centroid ripples provides strenght to captures prominent edge features in active patches: eyes, nose and mouth, that define the disparities between different facial expressions. Cross centroid information also provides robustness to irregular illumination. Moreover, CRIP utilizes the averaging behavior of pixels at subregions that yields robustness to deal with noisy conditions. The performance of proposed descriptor is evaluated on seven comprehensive expression datasets consisting of challenging conditions such as age, pose, ethnicity and illumination variations. The experimental results show that our descriptor consistently achieved better accuracy rate as compared to existing state-of-art approaches.
Non-Linearities Improve OrigiNet based on Active Imaging for Micro Expression Recognition
May 16, 2020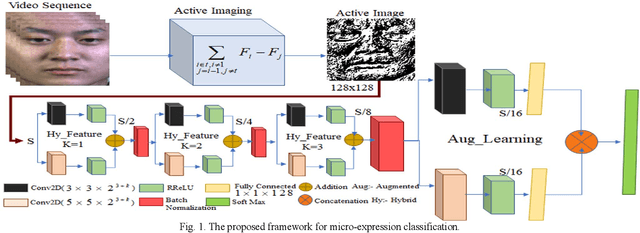

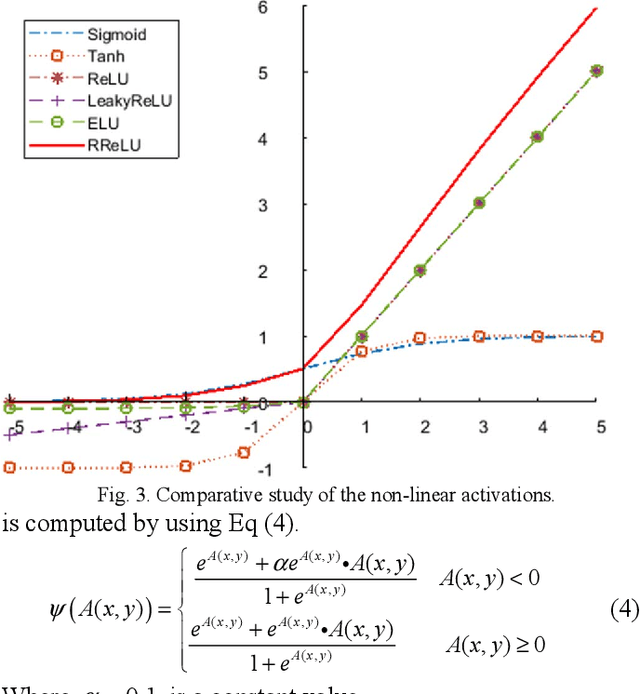

Micro expression recognition (MER)is a very challenging task as the expression lives very short in nature and demands feature modeling with the involvement of both spatial and temporal dynamics. Existing MER systems exploit CNN networks to spot the significant features of minor muscle movements and subtle changes. However, existing networks fail to establish a relationship between spatial features of facial appearance and temporal variations of facial dynamics. Thus, these networks were not able to effectively capture minute variations and subtle changes in expressive regions. To address these issues, we introduce an active imaging concept to segregate active changes in expressive regions of a video into a single frame while preserving facial appearance information. Moreover, we propose a shallow CNN network: hybrid local receptive field based augmented learning network (OrigiNet) that efficiently learns significant features of the micro-expressions in a video. In this paper, we propose a new refined rectified linear unit (RReLU), which overcome the problem of vanishing gradient and dying ReLU. RReLU extends the range of derivatives as compared to existing activation functions. The RReLU not only injects a nonlinearity but also captures the true edges by imposing additive and multiplicative property. Furthermore, we present an augmented feature learning block to improve the learning capabilities of the network by embedding two parallel fully connected layers. The performance of proposed OrigiNet is evaluated by conducting leave one subject out experiments on four comprehensive ME datasets. The experimental results demonstrate that OrigiNet outperformed state-of-the-art techniques with less computational complexity.
LEARNet Dynamic Imaging Network for Micro Expression Recognition
Apr 20, 2019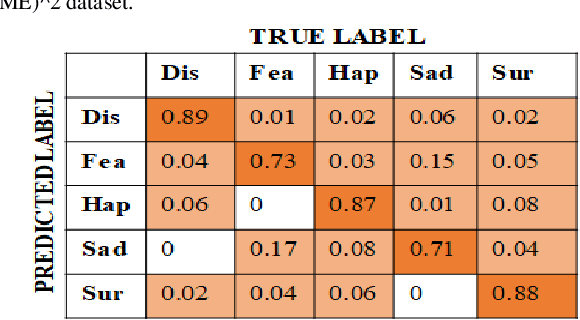
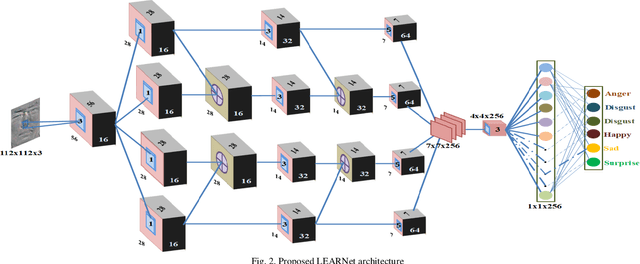


Unlike prevalent facial expressions, micro expressions have subtle, involuntary muscle movements which are short-lived in nature. These minute muscle movements reflect true emotions of a person. Due to the short duration and low intensity, these micro-expressions are very difficult to perceive and interpret correctly. In this paper, we propose the dynamic representation of micro-expressions to preserve facial movement information of a video in a single frame. We also propose a Lateral Accretive Hybrid Network (LEARNet) to capture micro-level features of an expression in the facial region. The LEARNet refines the salient expression features in accretive manner by incorporating accretion layers (AL) in the network. The response of the AL holds the hybrid feature maps generated by prior laterally connected convolution layers. Moreover, LEARNet architecture incorporates the cross decoupled relationship between convolution layers which helps in preserving the tiny but influential facial muscle change information. The visual responses of the proposed LEARNet depict the effectiveness of the system by preserving both high- and micro-level edge features of facial expression. The effectiveness of the proposed LEARNet is evaluated on four benchmark datasets: CASME-I, CASME-II, CAS(ME)^2 and SMIC. The experimental results after investigation show a significant improvement of 4.03%, 1.90%, 1.79% and 2.82% as compared with ResNet on CASME-I, CASME-II, CAS(ME)^2 and SMIC datasets respectively.
EXPERTNet Exigent Features Preservative Network for Facial Expression Recognition
Apr 14, 2019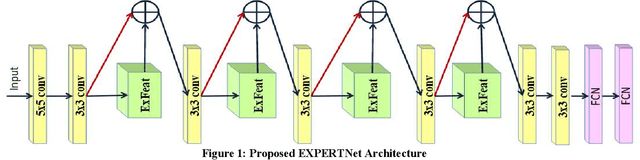
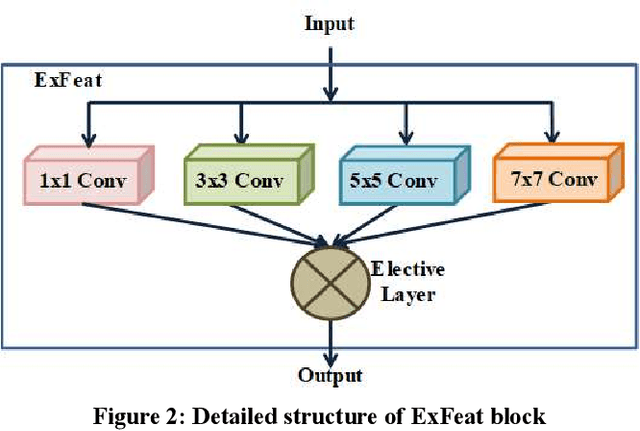

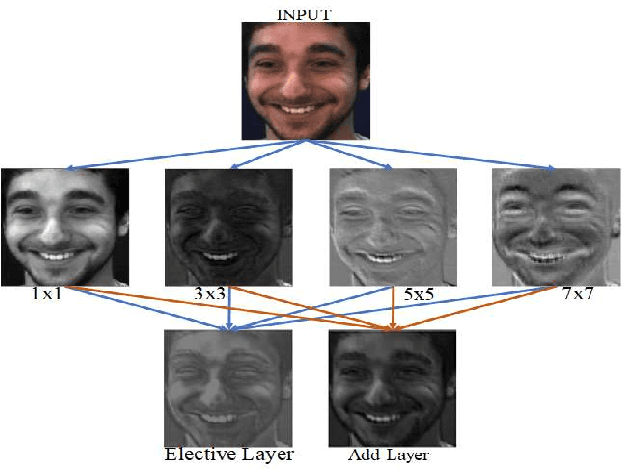
Facial expressions have essential cues to infer the humans state of mind, that conveys adequate information to understand individuals actual feelings. Thus, automatic facial expression recognition is an interesting and crucial task to interpret the humans cognitive state through the machine. In this paper, we proposed an Exigent Features Preservative Network (EXPERTNet), to describe the features of the facial expressions. The EXPERTNet extracts only pertinent features and neglect others by using exigent feature (ExFeat) block, mainly comprises of elective layer. Specifically, elective layer selects the desired edge variation features from the previous layer outcomes, which are generated by applying different sized filters as 1 x 1, 3 x 3, 5 x 5 and 7 x 7. Different sized filters aid to elicits both micro and high-level features that enhance the learnability of neurons. ExFeat block preserves the spatial structural information of the facial expression, which allows to discriminate between different classes of facial expressions. Visual representation of the proposed method over different facial expressions shows the learning capability of the neurons of different layers. Experimental and comparative analysis results over four comprehensive datasets CK+, MMI DISFA and GEMEP-FERA, ensures the better performance of the proposed network as compared to existing networks.
Region Based Extensive Response Index Pattern for Facial Expression Recognition
Nov 26, 2018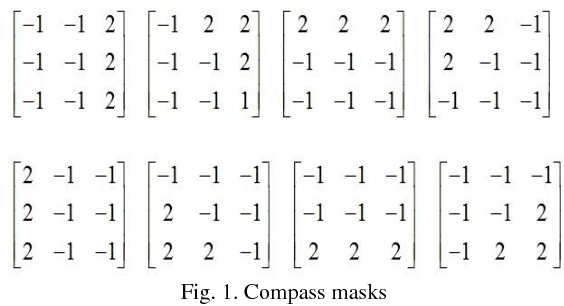

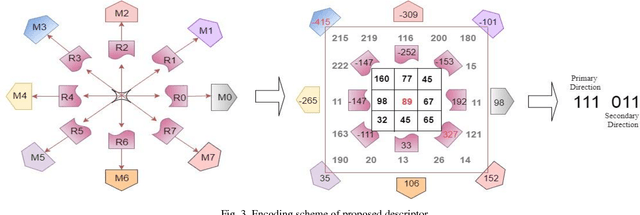
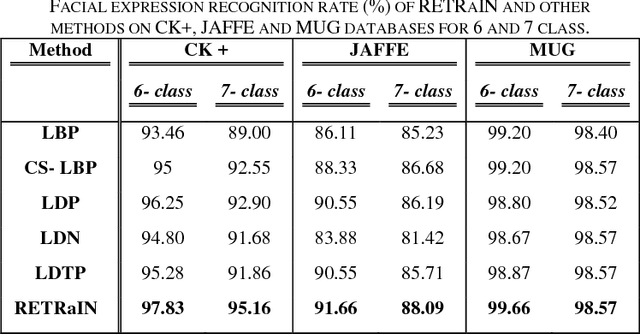
This paper presents a novel descriptor named Region based Extensive Response Index Pattern (RETRaIN) for facial expression recognition. The RETRaIN encodes the relation among the reference and neighboring pixels of facial active regions. These relations are computed by using directional compass mask on an input image and extract the high edge responses in foremost directions. Further extreme edge index positions are selected and encoded into six-bit compact code to reduce feature dimensionality and distinguish between the uniform and non-uniform patterns in the facial features. The performance of the proposed descriptor is tested and evaluated on three benchmark datasets Extended Cohn Kanade, JAFFE, and MUG. The RETRaIN achieves superior recognition accuracy in comparison to state-of-the-art techniques.