 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEARNet Dynamic Imaging Network for Micro Expression Recognition
Paper and Code
Apr 20, 2019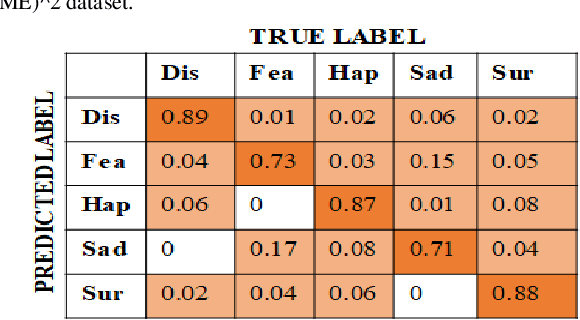
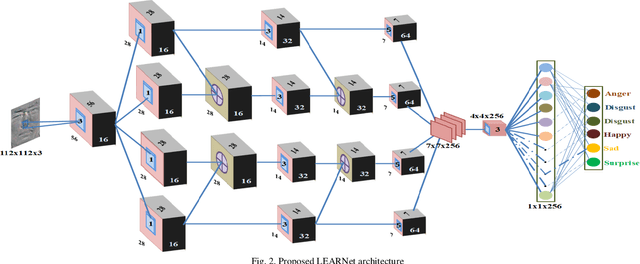


Unlike prevalent facial expressions, micro expressions have subtle, involuntary muscle movements which are short-lived in nature. These minute muscle movements reflect true emotions of a person. Due to the short duration and low intensity, these micro-expressions are very difficult to perceive and interpret correctly. In this paper, we propose the dynamic representation of micro-expressions to preserve facial movement information of a video in a single frame. We also propose a Lateral Accretive Hybrid Network (LEARNet) to capture micro-level features of an expression in the facial region. The LEARNet refines the salient expression features in accretive manner by incorporating accretion layers (AL) in the network. The response of the AL holds the hybrid feature maps generated by prior laterally connected convolution layers. Moreover, LEARNet architecture incorporates the cross decoupled relationship between convolution layers which helps in preserving the tiny but influential facial muscle change information. The visual responses of the proposed LEARNet depict the effectiveness of the system by preserving both high- and micro-level edge features of facial expression. The effectiveness of the proposed LEARNet is evaluated on four benchmark datasets: CASME-I, CASME-II, CAS(ME)^2 and SMIC. The experimental results after investigation show a significant improvement of 4.03%, 1.90%, 1.79% and 2.82% as compared with ResNet on CASME-I, CASME-II, CAS(ME)^2 and SMIC datasets respectively.