 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Linearities Improve OrigiNet based on Active Imaging for Micro Expression Recognition
Paper and Code
May 16, 2020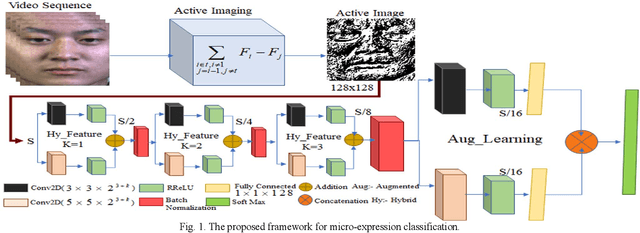

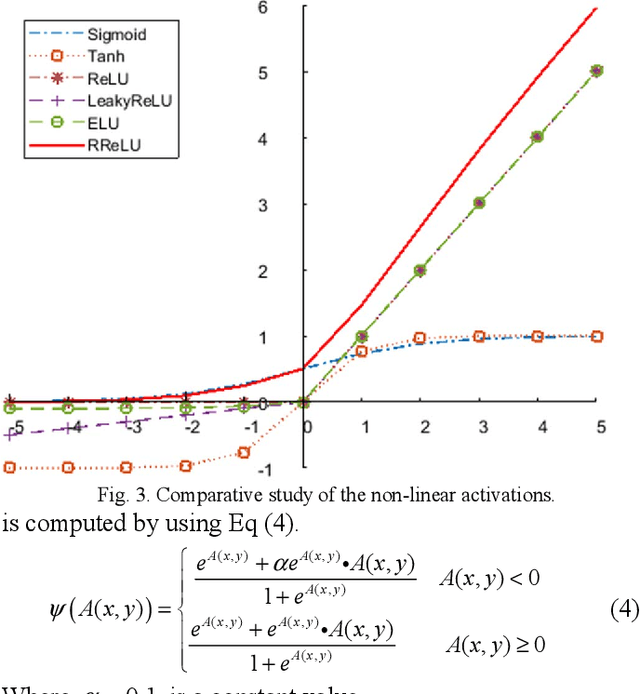

Micro expression recognition (MER)is a very challenging task as the expression lives very short in nature and demands feature modeling with the involvement of both spatial and temporal dynamics. Existing MER systems exploit CNN networks to spot the significant features of minor muscle movements and subtle changes. However, existing networks fail to establish a relationship between spatial features of facial appearance and temporal variations of facial dynamics. Thus, these networks were not able to effectively capture minute variations and subtle changes in expressive regions. To address these issues, we introduce an active imaging concept to segregate active changes in expressive regions of a video into a single frame while preserving facial appearance information. Moreover, we propose a shallow CNN network: hybrid local receptive field based augmented learning network (OrigiNet) that efficiently learns significant features of the micro-expressions in a video. In this paper, we propose a new refined rectified linear unit (RReLU), which overcome the problem of vanishing gradient and dying ReLU. RReLU extends the range of derivatives as compared to existing activation functions. The RReLU not only injects a nonlinearity but also captures the true edges by imposing additive and multiplicative property. Furthermore, we present an augmented feature learning block to improve the learning capabilities of the network by embedding two parallel fully connected layers. The performance of proposed OrigiNet is evaluated by conducting leave one subject out experiments on four comprehensive ME datasets. The experimental results demonstrate that OrigiNet outperformed state-of-the-art techniques with less computational complexity.