 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARDMath2: A Benchmark for Applied Mathematics Built by Students as Part of a Graduate Class
May 17, 2025Large language models (LLMs) have shown remarkable progress in mathematical problem-solving, but evaluation has largely focused on problems that have exact analytical solutions or involve formal proofs, often overlooking approximation-based problems ubiquitous in applied science and engineering. To fill this gap, we build on prior work and present HARDMath2, a dataset of 211 original problems covering the core topics in an introductory graduate applied math class, including boundary-layer analysis, WKB methods, asymptotic solutions of nonlinear partial differential equations, and the asymptotics of oscillatory integrals. This dataset was designed and verified by the students and instructors of a core graduate applied mathematics course at Harvard. We build the dataset through a novel collaborative environment that challenges students to write and refine difficult problems consistent with the class syllabus, peer-validate solutions, test different models, and automatically check LLM-generated solutions against their own answers and numerical ground truths. Evaluation results show that leading frontier models still struggle with many of the problems in the dataset, highlighting a gap in the mathematical reasoning skills of current LLMs. Importantly, students identified strategies to create increasingly difficult problems by interacting with the models and exploiting common failure modes. This back-and-forth with the models not only resulted in a richer and more challenging benchmark but also led to qualitative improvements in the students' understanding of the course material, which is increasingly important as we enter an age where state-of-the-art language models can solve many challenging problems across a wide domain of fields.
Intent Tagging: Exploring Micro-Prompting Interactions for Supporting Granular Human-GenAI Co-Creation Workflows
Feb 26, 2025Despite Generative AI (GenAI) systems' potential for enhancing content creation, users often struggle to effectively integrate GenAI into their creative workflows. Core challenges include misalignment of AI-generated content with user intentions (intent elicitation and alignment), user uncertainty around how to best communicate their intents to the AI system (prompt formulation), and insufficient flexibility of AI systems to support diverse creative workflows (workflow flexibility). Motivated by these challenges, we created IntentTagger: a system for slide creation based on the notion of Intent Tags - small, atomic conceptual units that encapsulate user intent - for exploring granular and non-linear micro-prompting interactions for Human-GenAI co-creation workflows. Our user study with 12 participants provides insights into the value of flexibly expressing intent across varying levels of ambiguity, meta-intent elicitation, and the benefits and challenges of intent tag-driven workflows. We conclude by discussing the broader implications of our findings and design considerations for GenAI-supported content creation workflows.
AI-Instruments: Embodying Prompts as Instruments to Abstract & Reflect Graphical Interface Commands as General-Purpose Tools
Feb 26, 2025



Chat-based prompts respond with verbose linear-sequential texts, making it difficult to explore and refine ambiguous intents, back up and reinterpret, or shift directions in creative AI-assisted design work. AI-Instruments instead embody "prompts" as interface objects via three key principles: (1) Reification of user-intent as reusable direct-manipulation instruments; (2) Reflection of multiple interpretations of ambiguous user-intents (Reflection-in-intent) as well as the range of AI-model responses (Reflection-in-response) to inform design "moves" towards a desired result; and (3) Grounding to instantiate an instrument from an example, result, or extrapolation directly from another instrument. Further, AI-Instruments leverage LLM's to suggest, vary, and refine new instruments, enabling a system that goes beyond hard-coded functionality by generating its own instrumental controls from content. We demonstrate four technology probes, applied to image generation, and qualitative insights from twelve participants, showing how AI-Instruments address challenges of intent formulation, steering via direct manipulation, and non-linear iterative workflows to reflect and resolve ambiguous intents.
TreeMatch: A Fully Unsupervised WSD System Using Dependency Knowledge on a Specific Domain
Jan 05, 2025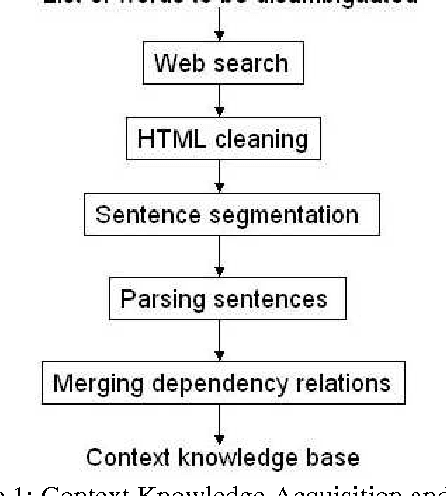
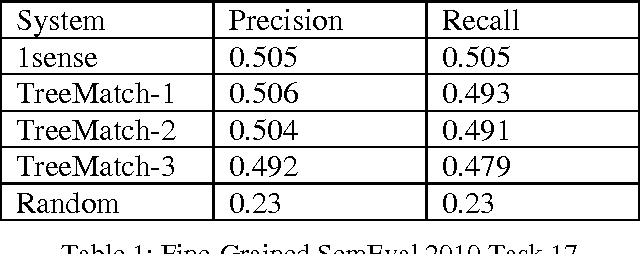
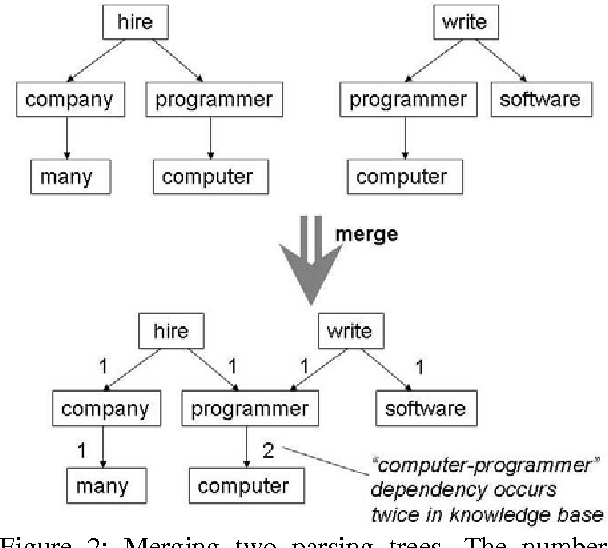
Word sense disambiguation (WSD) is one of the main challenges in Computational Linguistics. TreeMatch is a WSD system originally developed using data from SemEval 2007 Task 7 (Coarse-grained English All-words Task) that has been adapted for use in SemEval 2010 Task 17 (All-words Word Sense Disambiguation on a Specific Domain). The system is based on a fully unsupervised method using dependency knowledge drawn from a domain specific knowledge base that was built for this task. When evaluated on the task, the system precision performs above the Most Frequent Selection baseline.
Using Machine Learning to Select High-Quality Measurements
May 28, 2021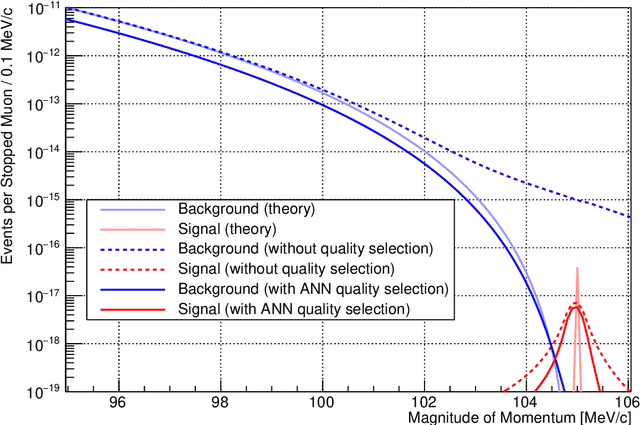



We describe the use of machine learning algorithms to select high-quality measurements for the Mu2e experiment. This technique is important for experiments with backgrounds that arise due to measurement errors. The algorithms use multiple pieces of ancillary information that are sensitive to measurement quality to separate high-quality and low-quality measurements.