 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Cross-Modal Retrieval with Noise-Robust Learning
Aug 26, 2022
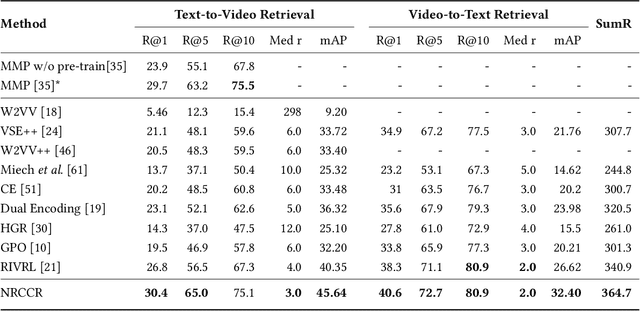
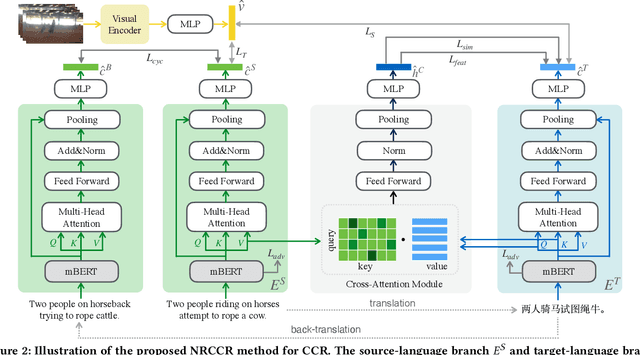
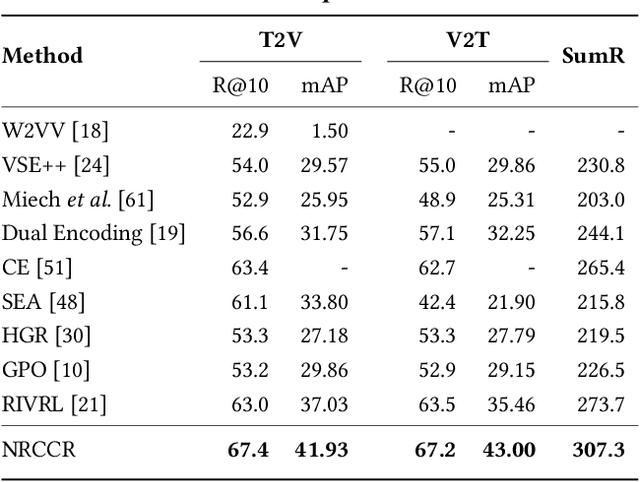
Despite the recent developments in the field of cross-modal retrieval, there has been less research focusing on low-resource languages due to the lack of manually annotated datasets. In this paper, we propose a noise-robust cross-lingual cross-modal retrieval method for low-resource languages. To this end, we use Machine Translation (MT) to construct pseudo-parallel sentence pairs for low-resource languages. However, as MT is not perfect, it tends to introduce noise during translation, rendering textual embeddings corrupted and thereby compromising the retrieval performance. To alleviate this, we introduce a multi-view self-distillation method to learn noise-robust target-language representations, which employs a cross-attention module to generate soft pseudo-targets to provide direct supervision from the similarity-based view and feature-based view. Besides, inspired by the back-translation in unsupervised MT, we minimize the semantic discrepancies between origin sentences and back-translated sentences to further improve the noise robustness of the textual encoder. Extensive experiments are conducted on three video-text and image-text cross-modal retrieval benchmarks across different languages, and the results demonstrate that our method significantly improves the overall performance without using extra human-labeled data. In addition, equipped with a pre-trained visual encoder from a recent vision-and-language pre-training framework, i.e., CLIP, our model achieves a significant performance gain, showing that our method is compatible with popular pre-training models. Code and data are available at https://github.com/HuiGuanLab/nrccr.
Partially Relevant Video Retrieval
Aug 26, 2022
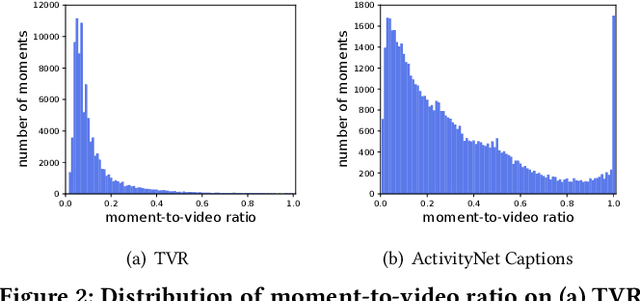
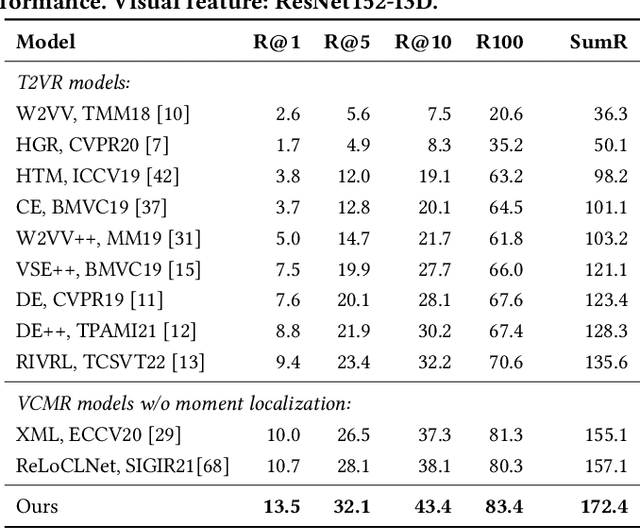
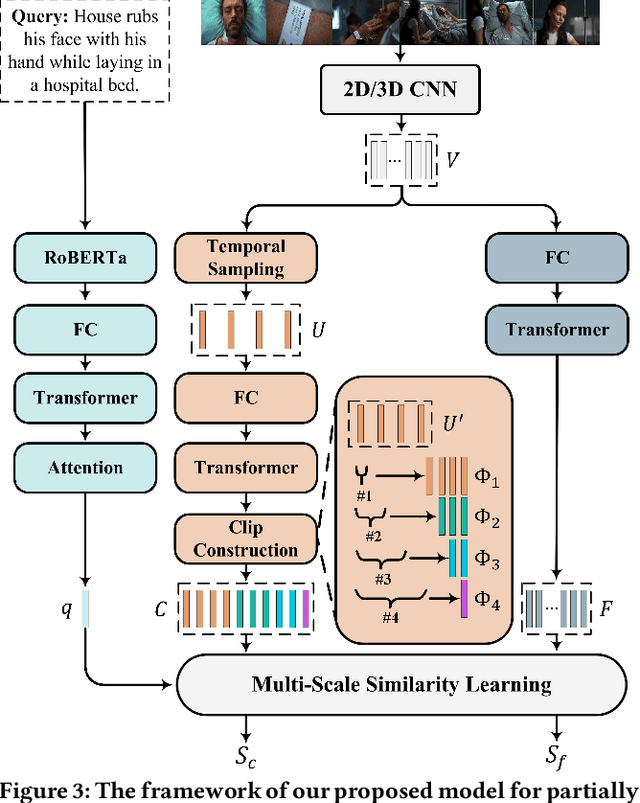
Current methods for text-to-video retrieval (T2VR) are trained and tested on video-captioning oriented datasets such as MSVD, MSR-VTT and VATEX. A key property of these datasets is that videos are assumed to be temporally pre-trimmed with short duration, whilst the provided captions well describe the gist of the video content. Consequently, for a given paired video and caption, the video is supposed to be fully relevant to the caption. In reality, however, as queries are not known a priori, pre-trimmed video clips may not contain sufficient content to fully meet the query. This suggests a gap between the literature and the real world. To fill the gap, we propose in this paper a novel T2VR subtask termed Partially Relevant Video Retrieval (PRVR). An untrimmed video is considered to be partially relevant w.r.t. a given textual query if it contains a moment relevant to the query. PRVR aims to retrieve such partially relevant videos from a large collection of untrimmed videos. PRVR differs from single video moment retrieval and video corpus moment retrieval, as the latter two are to retrieve moments rather than untrimmed videos. We formulate PRVR as a multiple instance learning (MIL) problem, where a video is simultaneously viewed as a bag of video clips and a bag of video frames. Clips and frames represent video content at different time scales. We propose a Multi-Scale Similarity Learning (MS-SL) network that jointly learns clip-scale and frame-scale similarities for PRVR. Extensive experiments on three datasets (TVR, ActivityNet Captions, and Charades-STA) demonstrate the viability of the proposed method. We also show that our method can be used for improving video corpus moment retrieval.