 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Radius and Integrated Codebook Transforms for Differentiable Vector Quantization
Feb 01, 2026Vector quantization (VQ) underpins modern generative and representation models by turning continuous latents into discrete tokens. Yet hard nearest-neighbor assignments are non-differentiable and are typically optimized with heuristic straight-through estimators, which couple the update step size to the quantization gap and train each code in isolation, leading to unstable gradients and severe codebook under-utilization at scale. In this paper, we introduce GRIT-VQ (Generalized Radius and Integrated Transform-Vector Quantization), a unified surrogate framework that keeps hard assignments in the forward pass while making VQ fully differentiable. GRIT-VQ replaces the straight-through estimator with a radius-based update that moves latents along the quantization direction with a controllable, geometry-aware step, and applies a data-agnostic integrated transform to the codebook so that all codes are updated through shared parameters instead of independently. Our theoretical analysis clarifies the fundamental optimization dynamics introduced by GRIT-VQ, establishing conditions for stable gradient flow, coordinated codebook evolution, and reliable avoidance of collapse across a broad family of quantizers. Across image reconstruction, image generation, and recommendation tokenization benchmarks, GRIT-VQ consistently improves reconstruction error, generative quality, and recommendation accuracy while substantially increasing codebook utilization compared to existing VQ variants.
PhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models
Jan 22, 2026Modern foundational Multimodal Large Language Models (MLLMs) and video world models have advanced significantly in mathematical, common-sense, and visual reasoning, but their grasp of the underlying physics remains underexplored. Existing benchmarks attempting to measure this matter rely on synthetic, Visual Question Answer templates or focus on perceptual video quality that is tangential to measuring how well the video abides by physical laws. To address this fragmentation, we introduce PhysicsMind, a unified benchmark with both real and simulation environments that evaluates law-consistent reasoning and generation over three canonical principles: Center of Mass, Lever Equilibrium, and Newton's First Law. PhysicsMind comprises two main tasks: i) VQA tasks, testing whether models can reason and determine physical quantities and values from images or short videos, and ii) Video Generation(VG) tasks, evaluating if predicted motion trajectories obey the same center-of-mass, torque, and inertial constraints as the ground truth. A broad range of recent models and video generation models is evaluated on PhysicsMind and found to rely on appearance heuristics while often violating basic mechanics. These gaps indicate that current scaling and training are still insufficient for robust physical understanding, underscoring PhysicsMind as a focused testbed for physics-aware multimodal models. Our data will be released upon acceptance.
Modular MeanFlow: Towards Stable and Scalable One-Step Generative Modeling
Aug 24, 2025One-step generative modeling seeks to generate high-quality data samples in a single function evaluation, significantly improving efficiency over traditional diffusion or flow-based models. In this work, we introduce Modular MeanFlow (MMF), a flexible and theoretically grounded approach for learning time-averaged velocity fields. Our method derives a family of loss functions based on a differential identity linking instantaneous and average velocities, and incorporates a gradient modulation mechanism that enables stable training without sacrificing expressiveness. We further propose a curriculum-style warmup schedule to smoothly transition from coarse supervision to fully differentiable training. The MMF formulation unifies and generalizes existing consistency-based and flow-matching methods, while avoiding expensive higher-order derivatives. Empirical results across image synthesis and trajectory modeling tasks demonstrate that MMF achieves competitive sample quality, robust convergence, and strong generalization, particularly under low-data or out-of-distribution settings.
MoA: Heterogeneous Mixture of Adapters for Parameter-Efficient Fine-Tuning of Large Language Models
Jun 06, 2025Recent studies integrate Low-Rank Adaptation (LoRA) and Mixture-of-Experts (MoE) to further enhance the performance of parameter-efficient fine-tuning (PEFT) methods in Large Language Model (LLM) applications. Existing methods employ \emph{homogeneous} MoE-LoRA architectures composed of LoRA experts with either similar or identical structures and capacities. However, these approaches often suffer from representation collapse and expert load imbalance, which negatively impact the potential of LLMs. To address these challenges, we propose a \emph{heterogeneous} \textbf{Mixture-of-Adapters (MoA)} approach. This method dynamically integrates PEFT adapter experts with diverse structures, leveraging their complementary representational capabilities to foster expert specialization, thereby enhancing the effective transfer of pre-trained knowledge to downstream tasks. MoA supports two variants: \textbf{(i)} \textit{Soft MoA} achieves fine-grained integration by performing a weighted fusion of all expert outputs; \textbf{(ii)} \textit{Sparse MoA} activates adapter experts sparsely based on their contribution, achieving this with negligible performance degradation. Experimental results demonstrate that heterogeneous MoA outperforms homogeneous MoE-LoRA methods in both performance and parameter efficiency. Our project is available at https://github.com/DCDmllm/MoA.
Optimizing Multi-Round Enhanced Training in Diffusion Models for Improved Preference Understanding
Apr 25, 2025Generative AI has significantly changed industries by enabling text-driven image generation, yet challenges remain in achieving high-resolution outputs that align with fine-grained user preferences. Consequently, multi-round interactions are necessary to ensure the generated images meet expectations. Previous methods enhanced prompts via reward feedback but did not optimize over a multi-round dialogue dataset. In this work, we present a Visual Co-Adaptation (VCA) framework incorporating human-in-the-loop feedback, leveraging a well-trained reward model aligned with human preferences. Using a diverse multi-turn dialogue dataset, our framework applies multiple reward functions, such as diversity, consistency, and preference feedback, while fine-tuning the diffusion model through LoRA, thus optimizing image generation based on user input. We also construct multi-round dialogue datasets of prompts and image pairs aligned with user intent. Experiments demonstrate that our method outperforms state-of-the-art baselines, significantly improving image consistency and alignment with user intent. Our approach consistently surpasses competing models in user satisfaction, especially in multi-turn dialogue scenarios.
Efficient Temporal Consistency in Diffusion-Based Video Editing with Adaptor Modules: A Theoretical Framework
Apr 22, 2025Adapter-based methods are commonly used to enhance model performance with minimal additional complexity, especially in video editing tasks that require frame-to-frame consistency. By inserting small, learnable modules into pretrained diffusion models, these adapters can maintain temporal coherence without extensive retraining. Approaches that incorporate prompt learning with both shared and frame-specific tokens are particularly effective in preserving continuity across frames at low training cost. In this work, we want to provide a general theoretical framework for adapters that maintain frame consistency in DDIM-based models under a temporal consistency loss. First, we prove that the temporal consistency objective is differentiable under bounded feature norms, and we establish a Lipschitz bound on its gradient. Second, we show that gradient descent on this objective decreases the loss monotonically and converges to a local minimum if the learning rate is within an appropriate range. Finally, we analyze the stability of modules in the DDIM inversion procedure, showing that the associated error remains controlled. These theoretical findings will reinforce the reliability of diffusion-based video editing methods that rely on adapter strategies and provide theoretical insights in video generation tasks.
Twin Co-Adaptive Dialogue for Progressive Image Generation
Apr 21, 2025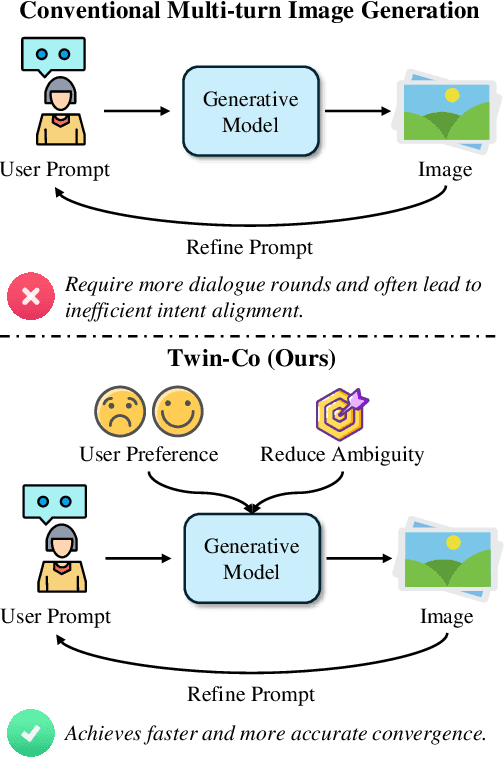
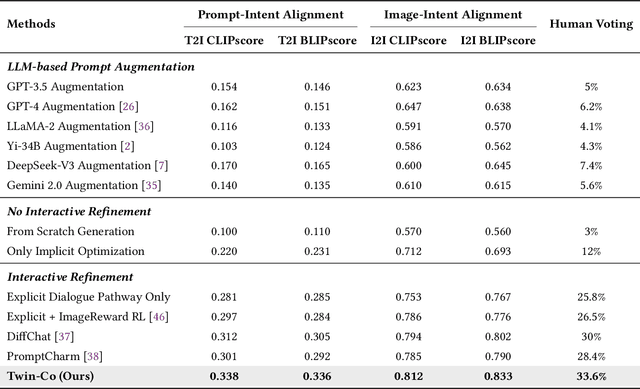
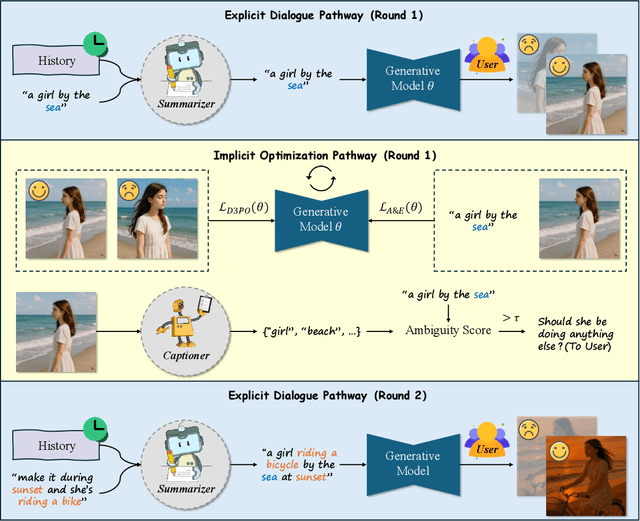

Modern text-to-image generation systems have enabled the creation of remarkably realistic and high-quality visuals, yet they often falter when handling the inherent ambiguities in user prompts. In this work, we present Twin-Co, a framework that leverages synchronized, co-adaptive dialogue to progressively refine image generation. Instead of a static generation process, Twin-Co employs a dynamic, iterative workflow where an intelligent dialogue agent continuously interacts with the user. Initially, a base image is generated from the user's prompt. Then, through a series of synchronized dialogue exchanges, the system adapts and optimizes the image according to evolving user feedback. The co-adaptive process allows the system to progressively narrow down ambiguities and better align with user intent. Experiments demonstrate that Twin-Co not only enhances user experience by reducing trial-and-error iterations but also improves the quality of the generated images, streamlining the creative process across various applications.
M2IV: Towards Efficient and Fine-grained Multimodal In-Context Learning in Large Vision-Language Models
Apr 06, 2025Multimodal in-context learning (ICL) is a vital capability for Large Vision-Language Models (LVLMs), allowing task adaptation via contextual prompts without parameter retraining. However, its application is hindered by the token-intensive nature of inputs and the high complexity of cross-modal few-shot learning, which limits the expressive power of representation methods. To tackle these challenges, we propose \textbf{M2IV}, a method that substitutes explicit demonstrations with learnable \textbf{I}n-context \textbf{V}ectors directly integrated into LVLMs. By exploiting the complementary strengths of multi-head attention (\textbf{M}HA) and multi-layer perceptrons (\textbf{M}LP), M2IV achieves robust cross-modal fidelity and fine-grained semantic distillation through training. This significantly enhances performance across diverse LVLMs and tasks and scales efficiently to many-shot scenarios, bypassing the context window limitations. We also introduce \textbf{VLibrary}, a repository for storing and retrieving M2IV, enabling flexible LVLM steering for tasks like cross-modal alignment, customized generation and safety improvement. Experiments across seven benchmarks and three LVLMs show that M2IV surpasses Vanilla ICL and prior representation engineering approaches, with an average accuracy gain of \textbf{3.74\%} over ICL with the same shot count, alongside substantial efficiency advantages.
MHITNet: a minimize network with a hierarchical context-attentional filter for segmenting medical ct images
Nov 01, 2022



In the field of medical CT image processing, convolutional neural networks (CNNs) have been the dominant technique.Encoder-decoder CNNs utilise locality for efficiency, but they cannot simulate distant pixel interactions properly.Recent research indicates that self-attention or transformer layers can be stacked to efficiently learn long-range dependencies.By constructing and processing picture patches as embeddings, transformers have been applied to computer vision applications. However, transformer-based architectures lack global semantic information interaction and require a large-scale training dataset, making it challenging to train with small data samples. In order to solve these challenges, we present a hierarchical contextattention transformer network (MHITNet) that combines the multi-scale, transformer, and hierarchical context extraction modules in skip-connections. The multi-scale module captures deeper CT semantic information, enabling transformers to encode feature maps of tokenized picture patches from various CNN stages as input attention sequences more effectively. The hierarchical context attention module augments global data and reweights pixels to capture semantic context.Extensive trials on three datasets show that the proposed MHITNet beats current best practises