 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA positive feedback method based on F-measure value for Salient Object Detection
Paper and Code
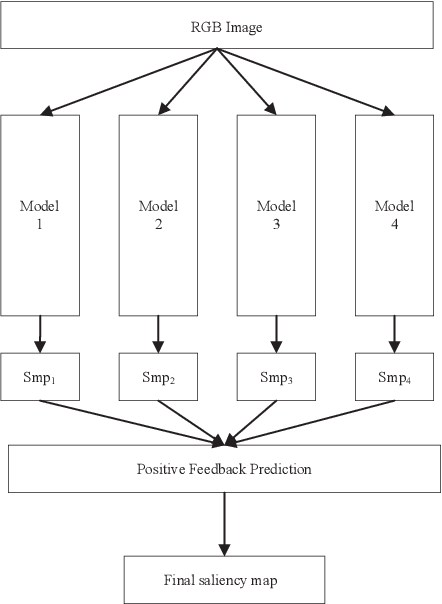


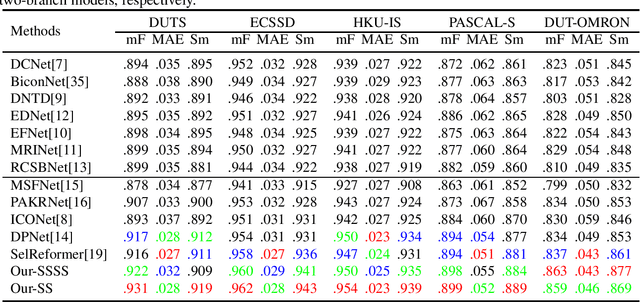
The majority of current salient object detection (SOD) models are focused on designing a series of decoders based on fully convolutional networks (FCNs) or Transformer architectures and integrating them in a skillful manner. These models have achieved remarkable high performance and made significant contributions to the development of SOD. Their primary research objective is to develop novel algorithms that can outperform state-of-the-art models, a task that is extremely difficult and time-consuming. In contrast, this paper proposes a positive feedback method based on F-measure value for SOD, aiming to improve the accuracy of saliency prediction using existing methods. Specifically, our proposed method takes an image to be detected and inputs it into several existing models to obtain their respective prediction maps. These prediction maps are then fed into our positive feedback method to generate the final prediction result, without the need for careful decoder design or model training. Moreover, our method is adaptive and can be implemented based on existing models without any restrictions. Experimental results on five publicly available datasets show that our proposed positive feedback method outperforms the latest 12 methods in five evaluation metrics for saliency map prediction. Additionally, we conducted a robustness experiment, which shows that when at least one good prediction result exists in the selected existing model, our proposed approach can ensure that the prediction result is not worse. Our approach achieves a prediction speed of 20 frames per second (FPS) when evaluated on a low configuration host and after removing the prediction time overhead of inserted models. These results highlight the effectiveness, efficiency, and robustness of our proposed approach for salient object detection.