 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevice-Cloud Collaborative Correction for On-Device Recommendation
Jun 15, 2025With the rapid development of recommendation models and device computing power, device-based recommendation has become an important research area due to its better real-time performance and privacy protection. Previously, Transformer-based sequential recommendation models have been widely applied in this field because they outperform Recurrent Neural Network (RNN)-based recommendation models in terms of performance. However, as the length of interaction sequences increases, Transformer-based models introduce significantly more space and computational overhead compared to RNN-based models, posing challenges for device-based recommendation. To balance real-time performance and high performance on devices, we propose Device-Cloud \underline{Co}llaborative \underline{Corr}ection Framework for On-Device \underline{Rec}ommendation (CoCorrRec). CoCorrRec uses a self-correction network (SCN) to correct parameters with extremely low time cost. By updating model parameters during testing based on the input token, it achieves performance comparable to current optimal but more complex Transformer-based models. Furthermore, to prevent SCN from overfitting, we design a global correction network (GCN) that processes hidden states uploaded from devices and provides a global correction solution. Extensive experiments on multiple datasets show that CoCorrRec outperforms existing Transformer-based and RNN-based device recommendation models in terms of performance, with fewer parameters and lower FLOPs, thereby achieving a balance between real-time performance and high efficiency.
Collaboration of Large Language Models and Small Recommendation Models for Device-Cloud Recommendation
Jan 10, 2025Large Language Models (LLMs) for Recommendation (LLM4Rec) is a promising research direction that has demonstrated exceptional performance in this field. However, its inability to capture real-time user preferences greatly limits the practical application of LLM4Rec because (i) LLMs are costly to train and infer frequently, and (ii) LLMs struggle to access real-time data (its large number of parameters poses an obstacle to deployment on devices). Fortunately, small recommendation models (SRMs) can effectively supplement these shortcomings of LLM4Rec diagrams by consuming minimal resources for frequent training and inference, and by conveniently accessing real-time data on devices. In light of this, we designed the Device-Cloud LLM-SRM Collaborative Recommendation Framework (LSC4Rec) under a device-cloud collaboration setting. LSC4Rec aims to integrate the advantages of both LLMs and SRMs, as well as the benefits of cloud and edge computing, achieving a complementary synergy. We enhance the practicability of LSC4Rec by designing three strategies: collaborative training, collaborative inference, and intelligent request. During training, LLM generates candidate lists to enhance the ranking ability of SRM in collaborative scenarios and enables SRM to update adaptively to capture real-time user interests. During inference, LLM and SRM are deployed on the cloud and on the device, respectively. LLM generates candidate lists and initial ranking results based on user behavior, and SRM get reranking results based on the candidate list, with final results integrating both LLM's and SRM's scores. The device determines whether a new candidate list is needed by comparing the consistency of the LLM's and SRM's sorted lists. Our comprehensive and extensive experimental analysis validates the effectiveness of each strategy in LSC4Rec.
Preliminary Evaluation of the Test-Time Training Layers in Recommendation System (Student Abstract)
Nov 19, 2024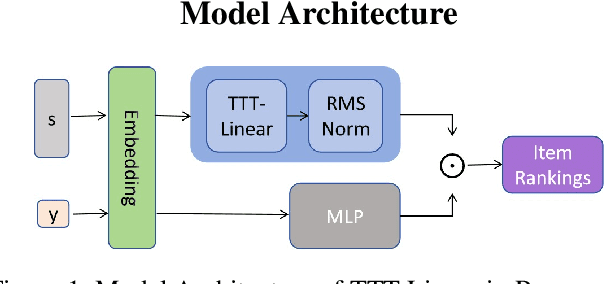



This paper explores the application and effectiveness of Test-Time Training (TTT) layers in improving the performance of recommendation systems. We developed a model, TTT4Rec, utilizing TTT-Linear as the feature extraction layer. Our tests across multiple datasets indicate that TTT4Rec, as a base model, performs comparably or even surpasses other baseline models in similar environments.
Semantic Codebook Learning for Dynamic Recommendation Models
Jul 31, 2024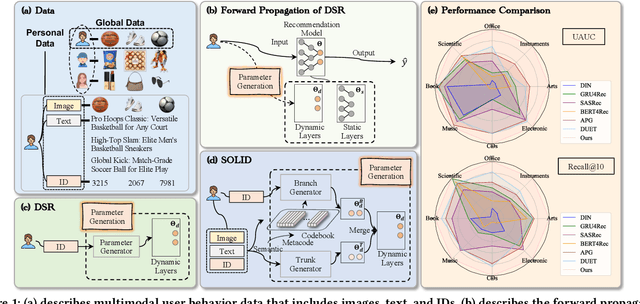
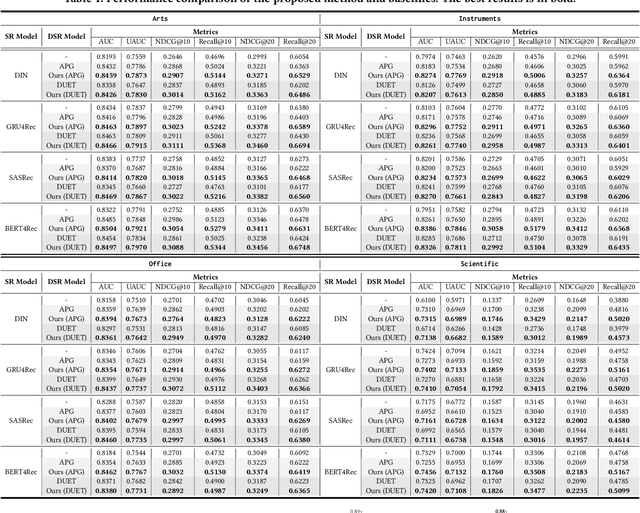
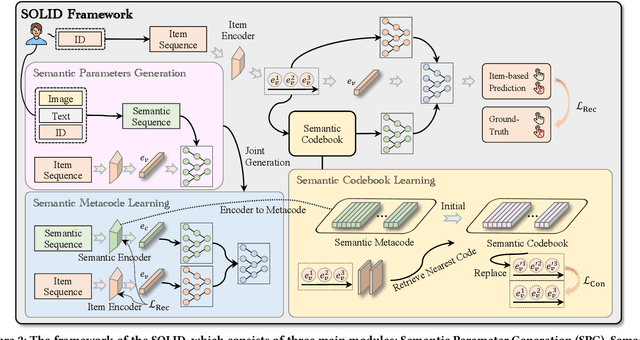

Dynamic sequential recommendation (DSR) can generate model parameters based on user behavior to improve the personalization of sequential recommendation under various user preferences. However, it faces the challenges of large parameter search space and sparse and noisy user-item interactions, which reduces the applicability of the generated model parameters. The Semantic Codebook Learning for Dynamic Recommendation Models (SOLID) framework presents a significant advancement in DSR by effectively tackling these challenges. By transforming item sequences into semantic sequences and employing a dual parameter model, SOLID compresses the parameter generation search space and leverages homogeneity within the recommendation system. The introduction of the semantic metacode and semantic codebook, which stores disentangled item representations, ensures robust and accurate parameter generation. Extensive experiments demonstrates that SOLID consistently outperforms existing DSR, delivering more accurate, stable, and robust recommendations.
MergeNet: Knowledge Migration across Heterogeneous Models, Tasks, and Modalities
Apr 20, 2024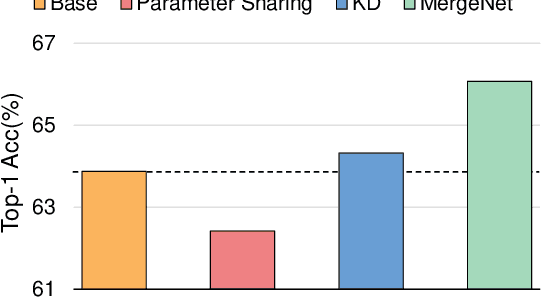
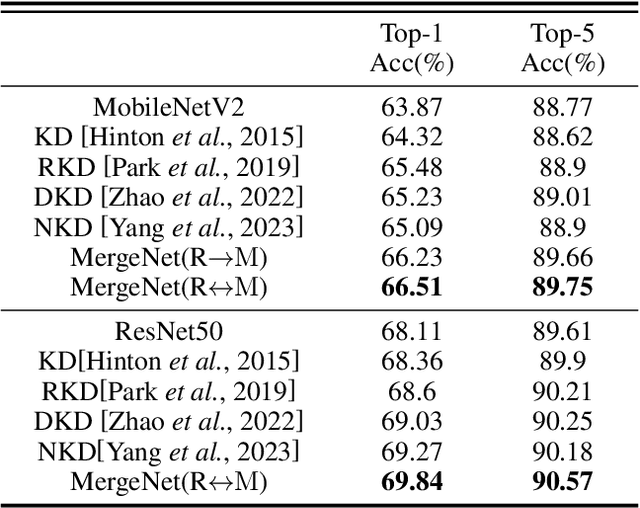
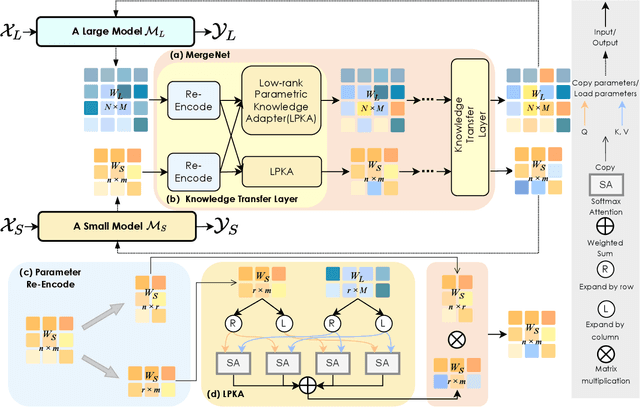

In this study, we focus on heterogeneous knowledge transfer across entirely different model architectures, tasks, and modalities. Existing knowledge transfer methods (e.g., backbone sharing, knowledge distillation) often hinge on shared elements within model structures or task-specific features/labels, limiting transfers to complex model types or tasks. To overcome these challenges, we present MergeNet, which learns to bridge the gap of parameter spaces of heterogeneous models, facilitating the direct interaction, extraction, and application of knowledge within these parameter spaces. The core mechanism of MergeNet lies in the parameter adapter, which operates by querying the source model's low-rank parameters and adeptly learning to identify and map parameters into the target model. MergeNet is learned alongside both models, allowing our framework to dynamically transfer and adapt knowledge relevant to the current stage, including the training trajectory knowledge of the source model. Extensive experiments on heterogeneous knowledge transfer demonstrate significant improvements in challenging settings, where representative approaches may falter or prove less applicable.