 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Manifold and Itô Dynamics with Branched Neural Rough Differential Equations
Jun 03, 2026Neural rough differential equations (NRDEs) stay accurate under irregular sampling while taking far fewer integration steps than standard neural differential equations, summarising a finely sampled driver by its log-signature and advancing the hidden state over coarse intervals using the log-ODE method. This efficiency rests on the shuffle algebra, the algebraic counterpart of Stratonovich calculus. This reliance means NRDEs cannot expose the quadratic-variation terms Itô dynamics require, nor the ordered covariant derivatives that govern Itô flows on connection-equipped manifolds. Ameliorating this, we introduce Branched Neural Rough Differential Equations (B-NRDEs), a Hopf-algebraic framework that recasts the NRDE log-ODE step as geometric numerical integration on the state-space manifold, matching the driving algebra to the governing calculus: Grossman--Larson rooted trees for Euclidean Itô dynamics, Munthe-Kaas--Wright planar rooted trees for ordered covariant derivatives on manifolds, and the shuffle algebra in the classical Stratonovich case. This yields intrinsic coarse-step dynamics that exactly preserve manifold constraints. Finally, we introduce a branched signature-kernel objective to enable Itô-consistent law matching by making quadratic-variation terms visible during training. On rough Bergomi volatility, sim-to-real $\mathrm{SO}(3)$ dynamics forecasting, and SPD covariance dynamics, B-NRDEs offer a unified, effective approach to stochastic and manifold-valued dynamics beyond the Euclidean--Stratonovich setting.
S$^3$GNN: Efficient Global Mixing and Local Message Passing for Long-Range Graph Learning
May 22, 2026Message-passing neural networks (MPNNs) often suffer from an information bottleneck when capturing long-range dependencies, leading to the oversquashing (OSQ) phenomenon. Alongside spatial connectivity enrichment (e.g., rewiring), recent studies have shown that spectral filtering can yield strong long-range learning outcomes, as spectral operators enable global information mixing that alleviates OSQ. These approaches achieve this either by stabilizing the Jacobian energies in deep propagation or by guaranteeing OSQ mitigation under strong theoretical assumptions. We revisit these conclusions and show that the associated Jacobian sensitivity lower bound is generally difficult to achieve in practice. We then propose S$^3$GNN, which mitigates OSQ without such restrictive assumptions by lightweightly reintroducing omitted components with substantially lower computational complexity, while standard stability constraints on feature transformations remain effective under our new dynamics. Extensive experiments across diverse domains (e.g., long-range benchmarks, KGQA, and mesh-based fluid dynamics) demonstrate that S$^3$GNN achieves up to an order-of-magnitude error reduction with up to 50\% fewer parameters. Our code can be found in https://github.com/EEthanShi/S3-GNN.git.
LOFT: Low-Rank Orthogonal Fine-Tuning via Task-Aware Support Selection
May 12, 2026Orthogonal parameter-efficient fine-tuning (PEFT) adapts pretrained weights through structure-preserving multiplicative transformations, but existing methods often conflate two distinct design choices: the subspace in which adaptation occurs and the transformation applied within that subspace. This paper introduces LOFT, a low-rank orthogonal fine-tuning framework that explicitly separates these two components. By viewing orthogonal adaptation as a multiplicative subspace rotation, LOFT provides a unified formulation that recovers representative orthogonal PEFT methods, including coordinate-, butterfly-, Householder-, and principal-subspace-based variants. More importantly, this perspective exposes support selection as a central design axis rather than a byproduct of a particular parameterization. We develop a first-order analysis showing that useful adaptation supports should be informed by the downstream training signal, motivating practical task-aware support selection strategies. Across language understanding, visual transfer, mathematical reasoning, and multilingual out-of-distribution adaptation, LOFT recovers principal-subspace orthogonal adaptation while gradient-informed supports improve the efficiency-performance trade-off under matched parameter, memory, and compute budgets. These results suggest that principled support selection is an important direction for improving orthogonal PEFT.
Expanding the Chaos: Neural Operator for Stochastic (Partial) Differential Equations
Jan 03, 2026Stochastic differential equations (SDEs) and stochastic partial differential equations (SPDEs) are fundamental tools for modeling stochastic dynamics across the natural sciences and modern machine learning. Developing deep learning models for approximating their solution operators promises not only fast, practical solvers, but may also inspire models that resolve classical learning tasks from a new perspective. In this work, we build on classical Wiener chaos expansions (WCE) to design neural operator (NO) architectures for SPDEs and SDEs: we project the driving noise paths onto orthonormal Wick Hermite features and parameterize the resulting deterministic chaos coefficients with neural operators, so that full solution trajectories can be reconstructed from noise in a single forward pass. On the theoretical side, we investigate the classical WCE results for the class of multi-dimensional SDEs and semilinear SPDEs considered here by explicitly writing down the associated coupled ODE/PDE systems for their chaos coefficients, which makes the separation between stochastic forcing and deterministic dynamics fully explicit and directly motivates our model designs. On the empirical side, we validate our models on a diverse suite of problems: classical SPDE benchmarks, diffusion one-step sampling on images, topological interpolation on graphs, financial extrapolation, parameter estimation, and manifold SDEs for flood prediction, demonstrating competitive accuracy and broad applicability. Overall, our results indicate that WCE-based neural operators provide a practical and scalable way to learn SDE/SPDE solution operators across diverse domains.
OmniSparse: Training-Aware Fine-Grained Sparse Attention for Long-Video MLLMs
Nov 18, 2025Existing sparse attention methods primarily target inference-time acceleration by selecting critical tokens under predefined sparsity patterns. However, they often fail to bridge the training-inference gap and lack the capacity for fine-grained token selection across multiple dimensions such as queries, key-values (KV), and heads, leading to suboptimal performance and limited acceleration gains. In this paper, we introduce OmniSparse, a training-aware fine-grained sparse attention framework for long-video MLLMs, which operates in both training and inference with dynamic token budget allocation. Specifically, OmniSparse contains three adaptive and complementary mechanisms: (1) query selection via lazy-active classification, retaining active queries that capture broad semantic similarity while discarding most lazy ones that focus on limited local context and exhibit high functional redundancy; (2) KV selection with head-level dynamic budget allocation, where a shared budget is determined based on the flattest head and applied uniformly across all heads to ensure attention recall; and (3) KV cache slimming to reduce head-level redundancy by selectively fetching visual KV cache according to the head-level decoding query pattern. Experimental results show that OmniSparse matches the performance of full attention while achieving up to 2.7x speedup during prefill and 2.4x memory reduction during decoding.
ACT as Human: Multimodal Large Language Model Data Annotation with Critical Thinking
Nov 13, 2025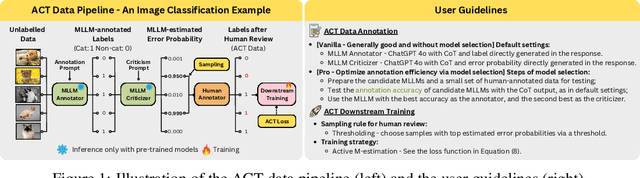



Supervised learning relies on high-quality labeled data, but obtaining such data through human annotation is both expensive and time-consuming. Recent work explores using large language models (LLMs) for annotation, but LLM-generated labels still fall short of human-level quality. To address this problem, we propose the Annotation with Critical Thinking (ACT) data pipeline, where LLMs serve not only as annotators but also as judges to critically identify potential errors. Human effort is then directed towards reviewing only the most "suspicious" cases, significantly improving the human annotation efficiency. Our major contributions are as follows: (1) ACT is applicable to a wide range of domains, including natural language processing (NLP), computer vision (CV), and multimodal understanding, by leveraging multimodal-LLMs (MLLMs). (2) Through empirical studies, we derive 7 insights on how to enhance annotation quality while efficiently reducing the human cost, and then translate these findings into user-friendly guidelines. (3) We theoretically analyze how to modify the loss function so that models trained on ACT data achieve similar performance to those trained on fully human-annotated data. Our experiments show that the performance gap can be reduced to less than 2% on most benchmark datasets while saving up to 90% of human costs.
ZipR1: Reinforcing Token Sparsity in MLLMs
Apr 23, 2025Sparse attention mechanisms aim to reduce computational overhead by selectively processing a subset of salient tokens while preserving model performance. Despite the effectiveness of such designs, how to actively encourage token sparsity of well-posed MLLMs remains under-explored, which fundamentally limits the achievable acceleration effect during inference. In this paper, we propose a simple RL-based post-training method named \textbf{ZipR1} that treats the token reduction ratio as the efficiency reward and answer accuracy as the performance reward. In this way, our method can jointly alleviate the computation and memory bottlenecks via directly optimizing the inference-consistent efficiency-performance tradeoff. Experimental results demonstrate that ZipR1 can reduce the token ratio of Qwen2/2.5-VL from 80\% to 25\% with a minimal accuracy reduction on 13 image and video benchmarks.
Graph Pseudotime Analysis and Neural Stochastic Differential Equations for Analyzing Retinal Degeneration Dynamics and Beyond
Feb 10, 2025
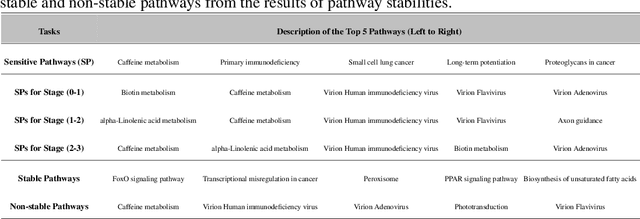


Understanding disease progression at the molecular pathway level usually requires capturing both structural dependencies between pathways and the temporal dynamics of disease evolution. In this work, we solve the former challenge by developing a biologically informed graph-forming method to efficiently construct pathway graphs for subjects from our newly curated JR5558 mouse transcriptomics dataset. We then develop Graph-level Pseudotime Analysis (GPA) to infer graph-level trajectories that reveal how disease progresses at the population level, rather than in individual subjects. Based on the trajectories estimated by GPA, we identify the most sensitive pathways that drive disease stage transitions. In addition, we measure changes in pathway features using neural stochastic differential equations (SDEs), which enables us to formally define and compute pathway stability and disease bifurcation points (points of no return), two fundamental problems in disease progression research. We further extend our theory to the case when pathways can interact with each other, enabling a more comprehensive and multi-faceted characterization of disease phenotypes. The comprehensive experimental results demonstrate the effectiveness of our framework in reconstructing the dynamics of the pathway, identifying critical transitions, and providing novel insights into the mechanistic understanding of disease evolution.
When Graph Neural Networks Meet Dynamic Mode Decomposition
Oct 08, 2024



Graph Neural Networks (GNNs) have emerged as fundamental tools for a wide range of prediction tasks on graph-structured data. Recent studies have drawn analogies between GNN feature propagation and diffusion processes, which can be interpreted as dynamical systems. In this paper, we delve deeper into this perspective by connecting the dynamics in GNNs to modern Koopman theory and its numerical method, Dynamic Mode Decomposition (DMD). We illustrate how DMD can estimate a low-rank, finite-dimensional linear operator based on multiple states of the system, effectively approximating potential nonlinear interactions between nodes in the graph. This approach allows us to capture complex dynamics within the graph accurately and efficiently. We theoretically establish a connection between the DMD-estimated operator and the original dynamic operator between system states. Building upon this foundation, we introduce a family of DMD-GNN models that effectively leverage the low-rank eigenfunctions provided by the DMD algorithm. We further discuss the potential of enhancing our approach by incorporating domain-specific constraints such as symmetry into the DMD computation, allowing the corresponding GNN models to respect known physical properties of the underlying system. Our work paves the path for applying advanced dynamical system analysis tools via GNNs. We validate our approach through extensive experiments on various learning tasks, including directed graphs, large-scale graphs, long-range interactions, and spatial-temporal graphs. We also empirically verify that our proposed models can serve as powerful encoders for link prediction tasks. The results demonstrate that our DMD-enhanced GNNs achieve state-of-the-art performance, highlighting the effectiveness of integrating DMD into GNN frameworks.
Diffusing to the Top: Boost Graph Neural Networks with Minimal Hyperparameter Tuning
Oct 08, 2024



Graph Neural Networks (GNNs) are proficient in graph representation learning and achieve promising performance on versatile tasks such as node classification and link prediction. Usually, a comprehensive hyperparameter tuning is essential for fully unlocking GNN's top performance, especially for complicated tasks such as node classification on large graphs and long-range graphs. This is usually associated with high computational and time costs and careful design of appropriate search spaces. This work introduces a graph-conditioned latent diffusion framework (GNN-Diff) to generate high-performing GNNs based on the model checkpoints of sub-optimal hyperparameters selected by a light-tuning coarse search. We validate our method through 166 experiments across four graph tasks: node classification on small, large, and long-range graphs, as well as link prediction. Our experiments involve 10 classic and state-of-the-art target models and 20 publicly available datasets. The results consistently demonstrate that GNN-Diff: (1) boosts the performance of GNNs with efficient hyperparameter tuning; and (2) presents high stability and generalizability on unseen data across multiple generation runs. The code is available at https://github.com/lequanlin/GNN-Diff.