 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the legibility of humanoid robot arm movements in a pointing task
Aug 07, 2025Human--robot interaction requires robots whose actions are legible, allowing humans to interpret, predict, and feel safe around them. This study investigates the legibility of humanoid robot arm movements in a pointing task, aiming to understand how humans predict robot intentions from truncated movements and bodily cues. We designed an experiment using the NICO humanoid robot, where participants observed its arm movements towards targets on a touchscreen. Robot cues varied across conditions: gaze, pointing, and pointing with congruent or incongruent gaze. Arm trajectories were stopped at 60\% or 80\% of their full length, and participants predicted the final target. We tested the multimodal superiority and ocular primacy hypotheses, both of which were supported by the experiment.
Learning Low-Level Causal Relations using a Simulated Robotic Arm
Oct 10, 2024Causal learning allows humans to predict the effect of their actions on the known environment and use this knowledge to plan the execution of more complex actions. Such knowledge also captures the behaviour of the environment and can be used for its analysis and the reasoning behind the behaviour. This type of knowledge is also crucial in the design of intelligent robotic systems with common sense. In this paper, we study causal relations by learning the forward and inverse models based on data generated by a simulated robotic arm involved in two sensorimotor tasks. As a next step, we investigate feature attribution methods for the analysis of the forward model, which reveals the low-level causal effects corresponding to individual features of the state vector related to both the arm joints and the environment features. This type of analysis provides solid ground for dimensionality reduction of the state representations, as well as for the aggregation of knowledge towards the explainability of causal effects at higher levels.
* 14 pages, 5 figures, 3 tables. Appeared in 2024 International Conference on Artificial Neural Networks (ICANN) proceedings. Published version copyrighted by Springer. This work was funded by the Horizon Europe Twinning project TERAIS, G.A. number 101079338 and in part by the Slovak Grant Agency for Science (VEGA), project 1/0373/23
Appearance-based gaze estimation enhanced with synthetic images using deep neural networks
Nov 23, 2023



Human eye gaze estimation is an important cognitive ingredient for successful human-robot interaction, enabling the robot to read and predict human behavior. We approach this problem using artificial neural networks and build a modular system estimating gaze from separately cropped eyes, taking advantage of existing well-functioning components for face detection (RetinaFace) and head pose estimation (6DRepNet). Our proposed method does not require any special hardware or infrared filters but uses a standard notebook-builtin RGB camera, as often approached with appearance-based methods. Using the MetaHuman tool, we also generated a large synthetic dataset of more than 57,000 human faces and made it publicly available. The inclusion of this dataset (with eye gaze and head pose information) on top of the standard Columbia Gaze dataset into training the model led to better accuracy with a mean average error below two degrees in eye pitch and yaw directions, which compares favourably to related methods. We also verified the feasibility of our model by its preliminary testing in real-world setting using the builtin 4K camera in NICO semi-humanoid robot's eye.
Robot at the Mirror: Learning to Imitate via Associating Self-supervised Models
Nov 22, 2023We introduce an approach to building a custom model from ready-made self-supervised models via their associating instead of training and fine-tuning. We demonstrate it with an example of a humanoid robot looking at the mirror and learning to detect the 3D pose of its own body from the image it perceives. To build our model, we first obtain features from the visual input and the postures of the robot's body via models prepared before the robot's operation. Then, we map their corresponding latent spaces by a sample-efficient robot's self-exploration at the mirror. In this way, the robot builds the solicited 3D pose detector, which quality is immediately perfect on the acquired samples instead of obtaining the quality gradually. The mapping, which employs associating the pairs of feature vectors, is then implemented in the same way as the key-value mechanism of the famous transformer models. Finally, deploying our model for imitation to a simulated robot allows us to study, tune up, and systematically evaluate its hyperparameters without the involvement of the human counterpart, advancing our previous research.
Exploration by self-supervised exploitation
Feb 22, 2023Reinforcement learning can solve decision-making problems and train an agent to behave in an environment according to a predesigned reward function. However, such an approach becomes very problematic if the reward is too sparse and the agent does not come across the reward during the environmental exploration. The solution to such a problem may be in equipping the agent with an intrinsic motivation, which will provide informed exploration, during which the agent is likely to also encounter external reward. Novelty detection is one of the promising branches of intrinsic motivation research. We present Self-supervised Network Distillation (SND), a class of internal motivation algorithms based on the distillation error as a novelty indicator, where the target model is trained using self-supervised learning. We adapted three existing self-supervised methods for this purpose and experimentally tested them on a set of ten environments that are considered difficult to explore. The results show that our approach achieves faster growth and higher external reward for the same training time compared to the baseline models, which implies improved exploration in a very sparse reward environment.
Examining the Proximity of Adversarial Examples to Class Manifolds in Deep Networks
Apr 12, 2022

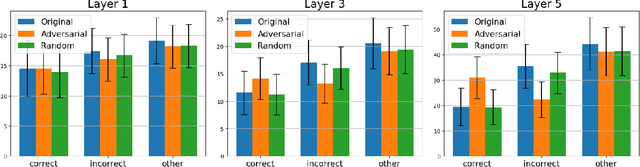

Deep neural networks achieve remarkable performance in multiple fields. However, after proper training they suffer from an inherent vulnerability against adversarial examples (AEs). In this work we shed light on inner representations of the AEs by analysing their activations on the hidden layers. We test various types of AEs, each crafted using a specific norm constraint, which affects their visual appearance and eventually their behavior in the trained networks. Our results in image classification tasks (MNIST and CIFAR-10) reveal qualitative differences between the individual types of AEs, when comparing their proximity to the class-specific manifolds on the inner representations. We propose two methods that can be used to compare the distances to class-specific manifolds, regardless of the changing dimensions throughout the network. Using these methods, we consistently confirm that some of the adversarials do not necessarily leave the proximity of the manifold of the correct class, not even in the last hidden layer of the neural network. Next, using UMAP visualisation technique, we project the class activations to 2D space. The results indicate that the activations of the individual AEs are entangled with the activations of the test set. This, however, does not hold for a group of crafted inputs called the rubbish class. We also confirm the entanglement of adversarials with the test set numerically using the soft nearest neighbour loss.