 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Proximity of Adversarial Examples to Class Manifolds in Deep Networks
Apr 12, 2022

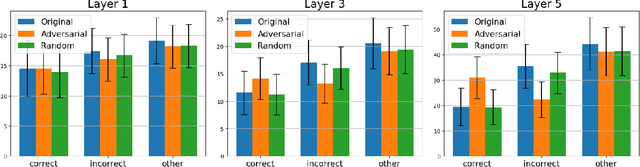

Deep neural networks achieve remarkable performance in multiple fields. However, after proper training they suffer from an inherent vulnerability against adversarial examples (AEs). In this work we shed light on inner representations of the AEs by analysing their activations on the hidden layers. We test various types of AEs, each crafted using a specific norm constraint, which affects their visual appearance and eventually their behavior in the trained networks. Our results in image classification tasks (MNIST and CIFAR-10) reveal qualitative differences between the individual types of AEs, when comparing their proximity to the class-specific manifolds on the inner representations. We propose two methods that can be used to compare the distances to class-specific manifolds, regardless of the changing dimensions throughout the network. Using these methods, we consistently confirm that some of the adversarials do not necessarily leave the proximity of the manifold of the correct class, not even in the last hidden layer of the neural network. Next, using UMAP visualisation technique, we project the class activations to 2D space. The results indicate that the activations of the individual AEs are entangled with the activations of the test set. This, however, does not hold for a group of crafted inputs called the rubbish class. We also confirm the entanglement of adversarials with the test set numerically using the soft nearest neighbour loss.