 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting 3D Line Segments for 6DoF Pose Estimation with Limited Data
Jan 17, 2026The task of 6DoF object pose estimation is one of the fundamental problems of 3D vision with many practical applications such as industrial automation. Traditional deep learning approaches for this task often require extensive training data or CAD models, limiting their application in real-world industrial settings where data is scarce and object instances vary. We propose a novel method for 6DoF pose estimation focused specifically on bins used in industrial settings. We exploit the cuboid geometry of bins by first detecting intermediate 3D line segments corresponding to their top edges. Our approach extends the 2D line segment detection network LeTR to operate on structured point cloud data. The detected 3D line segments are then processed using a simple geometric procedure to robustly determine the bin's 6DoF pose. To evaluate our method, we extend an existing dataset with a newly collected and annotated dataset, which we make publicly available. We show that incorporating synthetic training data significantly improves pose estimation accuracy on real scans. Moreover, we show that our method significantly outperforms current state-of-the-art 6DoF pose estimation methods in terms of the pose accuracy (3 cm translation error, 8.2$^\circ$ rotation error) while not requiring instance-specific CAD models during inference.
Decentralized Privacy-Preserving Federal Learning of Computer Vision Models on Edge Devices
Jan 08, 2026Collaborative training of a machine learning model comes with a risk of sharing sensitive or private data. Federated learning offers a way of collectively training a single global model without the need to share client data, by sharing only the updated parameters from each client's local model. A central server is then used to aggregate parameters from all clients and redistribute the aggregated model back to the clients. Recent findings have shown that even in this scenario, private data can be reconstructed only using information about model parameters. Current efforts to mitigate this are mainly focused on reducing privacy risks on the server side, assuming that other clients will not act maliciously. In this work, we analyzed various methods for improving the privacy of client data concerning both the server and other clients for neural networks. Some of these methods include homomorphic encryption, gradient compression, gradient noising, and discussion on possible usage of modified federated learning systems such as split learning, swarm learning or fully encrypted models. We have analyzed the negative effects of gradient compression and gradient noising on the accuracy of convolutional neural networks used for classification. We have shown the difficulty of data reconstruction in the case of segmentation networks. We have also implemented a proof of concept on the NVIDIA Jetson TX2 module used in edge devices and simulated a federated learning process.
Shaken, Not Stirred: A Novel Dataset for Visual Understanding of Glasses in Human-Robot Bartending Tasks
Mar 06, 2025



Datasets for object detection often do not account for enough variety of glasses, due to their transparent and reflective properties. Specifically, open-vocabulary object detectors, widely used in embodied robotic agents, fail to distinguish subclasses of glasses. This scientific gap poses an issue to robotic applications that suffer from accumulating errors between detection, planning, and action execution. The paper introduces a novel method for the acquisition of real-world data from RGB-D sensors that minimizes human effort. We propose an auto-labeling pipeline that generates labels for all the acquired frames based on the depth measurements. We provide a novel real-world glass object dataset that was collected on the Neuro-Inspired COLlaborator (NICOL), a humanoid robot platform. The data set consists of 7850 images recorded from five different cameras. We show that our trained baseline model outperforms state-of-the-art open-vocabulary approaches. In addition, we deploy our baseline model in an embodied agent approach to the NICOL platform, on which it achieves a success rate of 81% in a human-robot bartending scenario.
Enhancement of 3D Camera Synthetic Training Data with Noise Models
Feb 26, 2024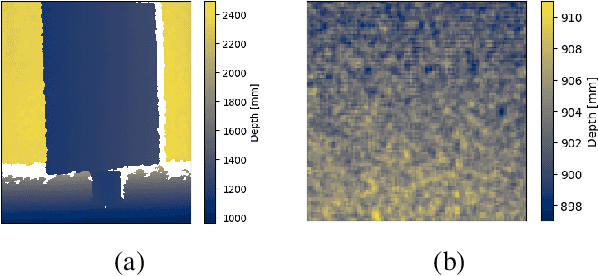


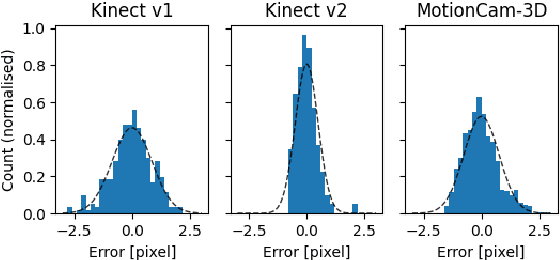
The goal of this paper is to assess the impact of noise in 3D camera-captured data by modeling the noise of the imaging process and applying it on synthetic training data. We compiled a dataset of specifically constructed scenes to obtain a noise model. We specifically model lateral noise, affecting the position of captured points in the image plane, and axial noise, affecting the position along the axis perpendicular to the image plane. The estimated models can be used to emulate noise in synthetic training data. The added benefit of adding artificial noise is evaluated in an experiment with rendered data for object segmentation. We train a series of neural networks with varying levels of noise in the data and measure their ability to generalize on real data. The results show that using too little or too much noise can hurt the networks' performance indicating that obtaining a model of noise from real scanners is beneficial for synthetic data generation.
* Published in 2024 Proceedings of the 27th Computer Vision Winter Workshop (CVWW). Accepted: 19.1.2024. Published: 16.2.2024. This work was funded by the Horizon-Widera-2021 European Twinning project TERAIS G.A. n. 101079338. Code: https://doi.org/10.5281/zenodo.10581562 Data: https://doi.org/10.5281/zenodo.10581278
Processing and Segmentation of Human Teeth from 2D Images using Weakly Supervised Learning
Nov 13, 2023



Teeth segmentation is an essential task in dental image analysis for accurate diagnosis and treatment planning. While supervised deep learning methods can be utilized for teeth segmentation, they often require extensive manual annotation of segmentation masks, which is time-consuming and costly. In this research, we propose a weakly supervised approach for teeth segmentation that reduces the need for manual annotation. Our method utilizes the output heatmaps and intermediate feature maps from a keypoint detection network to guide the segmentation process. We introduce the TriDental dataset, consisting of 3000 oral cavity images annotated with teeth keypoints, to train a teeth keypoint detection network. We combine feature maps from different layers of the keypoint detection network, enabling accurate teeth segmentation without explicit segmentation annotations. The detected keypoints are also used for further refinement of the segmentation masks. Experimental results on the TriDental dataset demonstrate the superiority of our approach in terms of accuracy and robustness compared to state-of-the-art segmentation methods. Our method offers a cost-effective and efficient solution for teeth segmentation in real-world dental applications, eliminating the need for extensive manual annotation efforts.
Supersampling of Data from Structured-light Scanner with Deep Learning
Nov 13, 2023



This paper focuses on increasing the resolution of depth maps obtained from 3D cameras using structured light technology. Two deep learning models FDSR and DKN are modified to work with high-resolution data, and data pre-processing techniques are implemented for stable training. The models are trained on our custom dataset of 1200 3D scans. The resulting high-resolution depth maps are evaluated using qualitative and quantitative metrics. The approach for depth map upsampling offers benefits such as reducing the processing time of a pipeline by first downsampling a high-resolution depth map, performing various processing steps at the lower resolution and upsampling the resulting depth map or increasing the resolution of a point cloud captured in lower resolution by a cheaper device. The experiments demonstrate that the FDSR model excels in terms of faster processing time, making it a suitable choice for applications where speed is crucial. On the other hand, the DKN model provides results with higher precision, making it more suitable for applications that prioritize accuracy.
Automatic Estimation of Anthropometric Human Body Measurements
Dec 22, 2021



Research tasks related to human body analysis have been drawing a lot of attention in computer vision area over the last few decades, considering its potential benefits on our day-to-day life. Anthropometry is a field defining physical measures of a human body size, form, and functional capacities. Specifically, the accurate estimation of anthropometric body measurements from visual human body data is one of the challenging problems, where the solution would ease many different areas of applications, including ergonomics, garment manufacturing, etc. This paper formulates a research in the field of deep learning and neural networks, to tackle the challenge of body measurements estimation from various types of visual input data (such as 2D images or 3D point clouds). Also, we deal with the lack of real human data annotated with ground truth body measurements required for training and evaluation, by generating a synthetic dataset of various human body shapes and performing a skeleton-driven annotation.
Towards Deep Learning-based 6D Bin Pose Estimation in 3D Scans
Dec 17, 2021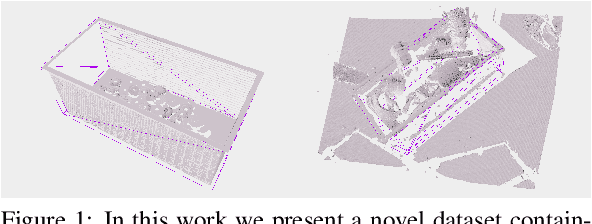

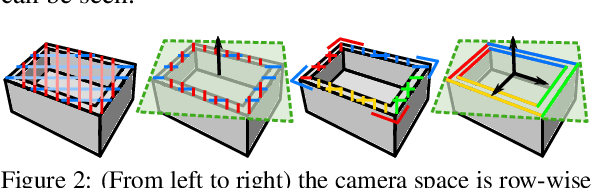
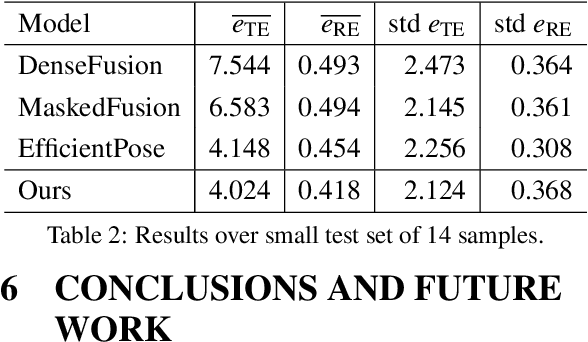
An automated robotic system needs to be as robust as possible and fail-safe in general while having relatively high precision and repeatability. Although deep learning-based methods are becoming research standard on how to approach 3D scan and image processing tasks, the industry standard for processing this data is still analytically-based. Our paper claims that analytical methods are less robust and harder for testing, updating, and maintaining. This paper focuses on a specific task of 6D pose estimation of a bin in 3D scans. Therefore, we present a high-quality dataset composed of synthetic data and real scans captured by a structured-light scanner with precise annotations. Additionally, we propose two different methods for 6D bin pose estimation, an analytical method as the industrial standard and a baseline data-driven method. Both approaches are cross-evaluated, and our experiments show that augmenting the training on real scans with synthetic data improves our proposed data-driven neural model. This position paper is preliminary, as proposed methods are trained and evaluated on a relatively small initial dataset which we plan to extend in the future.