 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Bidirectional Action-Language Translation with Limited Supervision and Incongruent Extra Input
Jan 09, 2023Human infant learning happens during exploration of the environment, by interaction with objects, and by listening to and repeating utterances casually, which is analogous to unsupervised learning. Only occasionally, a learning infant would receive a matching verbal description of an action it is committing, which is similar to supervised learning. Such a learning mechanism can be mimicked with deep learning. We model this weakly supervised learning paradigm using our Paired Gated Autoencoders (PGAE) model, which combines an action and a language autoencoder. After observing a performance drop when reducing the proportion of supervised training, we introduce the Paired Transformed Autoencoders (PTAE) model, using Transformer-based crossmodal attention. PTAE achieves significantly higher accuracy in language-to-action and action-to-language translations, particularly in realistic but difficult cases when only few supervised training samples are available. We also test whether the trained model behaves realistically with conflicting multimodal input. In accordance with the concept of incongruence in psychology, conflict deteriorates the model output. Conflicting action input has a more severe impact than conflicting language input, and more conflicting features lead to larger interference. PTAE can be trained on mostly unlabelled data where labeled data is scarce, and it behaves plausibly when tested with incongruent input.
Learning Flexible Translation between Robot Actions and Language Descriptions
Jul 15, 2022



Handling various robot action-language translation tasks flexibly is an essential requirement for natural interaction between a robot and a human. Previous approaches require change in the configuration of the model architecture per task during inference, which undermines the premise of multi-task learning. In this work, we propose the paired gated autoencoders (PGAE) for flexible translation between robot actions and language descriptions in a tabletop object manipulation scenario. We train our model in an end-to-end fashion by pairing each action with appropriate descriptions that contain a signal informing about the translation direction. During inference, our model can flexibly translate from action to language and vice versa according to the given language signal. Moreover, with the option to use a pretrained language model as the language encoder, our model has the potential to recognise unseen natural language input. Another capability of our model is that it can recognise and imitate actions of another agent by utilising robot demonstrations. The experiment results highlight the flexible bidirectional translation capabilities of our approach alongside with the ability to generalise to the actions of the opposite-sitting agent.
Language Model-Based Paired Variational Autoencoders for Robotic Language Learning
Jan 17, 2022
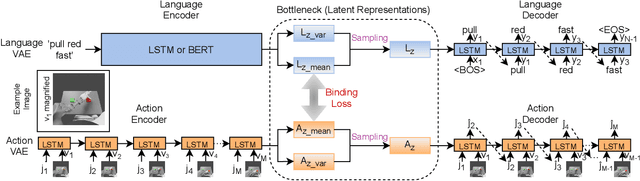

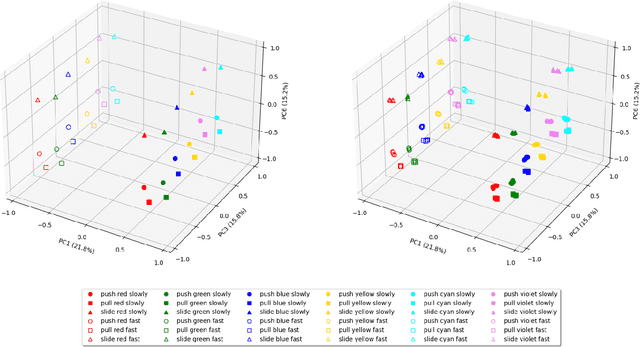
Human infants learn language while interacting with their environment in which their caregivers may describe the objects and actions they perform. Similar to human infants, artificial agents can learn language while interacting with their environment. In this work, first, we present a neural model that bidirectionally binds robot actions and their language descriptions in a simple object manipulation scenario. Building on our previous Paired Variational Autoencoders (PVAE) model, we demonstrate the superiority of the variational autoencoder over standard autoencoders by experimenting with cubes of different colours, and by enabling the production of alternative vocabularies. Additional experiments show that the model's channel-separated visual feature extraction module can cope with objects of different shapes. Next, we introduce PVAE-BERT, which equips the model with a pretrained large-scale language model, i.e., Bidirectional Encoder Representations from Transformers (BERT), enabling the model to go beyond comprehending only the predefined descriptions that the network has been trained on; the recognition of action descriptions generalises to unconstrained natural language as the model becomes capable of understanding unlimited variations of the same descriptions. Our experiments suggest that using a pretrained language model as the language encoder allows our approach to scale up for real-world scenarios with instructions from human users.