 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Machine Learning for Conditional Moment Restrictions: IV regression, Proximal Causal Learning and Beyond
Jun 17, 2025Solving conditional moment restrictions (CMRs) is a key problem considered in statistics, causal inference, and econometrics, where the aim is to solve for a function of interest that satisfies some conditional moment equalities. Specifically, many techniques for causal inference, such as instrumental variable (IV) regression and proximal causal learning (PCL), are CMR problems. Most CMR estimators use a two-stage approach, where the first-stage estimation is directly plugged into the second stage to estimate the function of interest. However, naively plugging in the first-stage estimator can cause heavy bias in the second stage. This is particularly the case for recently proposed CMR estimators that use deep neural network (DNN) estimators for both stages, where regularisation and overfitting bias is present. We propose DML-CMR, a two-stage CMR estimator that provides an unbiased estimate with fast convergence rate guarantees. We derive a novel learning objective to reduce bias and develop the DML-CMR algorithm following the double/debiased machine learning (DML) framework. We show that our DML-CMR estimator can achieve the minimax optimal convergence rate of $O(N^{-1/2})$ under parameterisation and mild regularity conditions, where $N$ is the sample size. We apply DML-CMR to a range of problems using DNN estimators, including IV regression and proximal causal learning on real-world datasets, demonstrating state-of-the-art performance against existing CMR estimators and algorithms tailored to those problems.
A Unifying Framework for Causal Imitation Learning with Hidden Confounders
Feb 11, 2025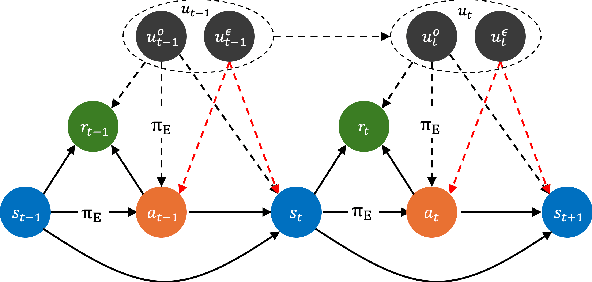

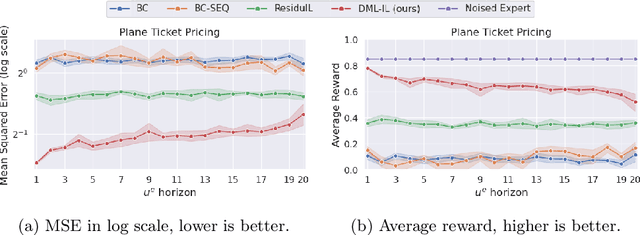
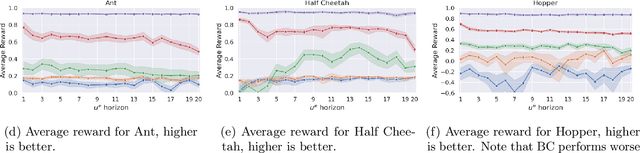
We propose a general and unifying framework for causal Imitation Learning (IL) with hidden confounders that subsumes several existing confounded IL settings from the literature. Our framework accounts for two types of hidden confounders: (a) those observed by the expert, which thus influence the expert's policy, and (b) confounding noise hidden to both the expert and the IL algorithm. For additional flexibility, we also introduce a confounding noise horizon and time-varying expert-observable hidden variables. We show that causal IL in our framework can be reduced to a set of Conditional Moment Restrictions (CMRs) by leveraging trajectory histories as instruments to learn a history-dependent policy. We propose DML-IL, a novel algorithm that uses instrumental variable regression to solve these CMRs and learn a policy. We provide a bound on the imitation gap for DML-IL, which recovers prior results as special cases. Empirical evaluation on a toy environment with continues state-action spaces and multiple Mujoco tasks demonstrate that DML-IL outperforms state-of-the-art causal IL algorithms.
Learning Decision Policies with Instrumental Variables through Double Machine Learning
May 15, 2024A common issue in learning decision-making policies in data-rich settings is spurious correlations in the offline dataset, which can be caused by hidden confounders. Instrumental variable (IV) regression, which utilises a key unconfounded variable known as the instrument, is a standard technique for learning causal relationships between confounded action, outcome, and context variables. Most recent IV regression algorithms use a two-stage approach, where a deep neural network (DNN) estimator learnt in the first stage is directly plugged into the second stage, in which another DNN is used to estimate the causal effect. Naively plugging the estimator can cause heavy bias in the second stage, especially when regularisation bias is present in the first stage estimator. We propose DML-IV, a non-linear IV regression method that reduces the bias in two-stage IV regressions and effectively learns high-performing policies. We derive a novel learning objective to reduce bias and design the DML-IV algorithm following the double/debiased machine learning (DML) framework. The learnt DML-IV estimator has strong convergence rate and $O(N^{-1/2})$ suboptimality guarantees that match those when the dataset is unconfounded. DML-IV outperforms state-of-the-art IV regression methods on IV regression benchmarks and learns high-performing policies in the presence of instruments.
Sample Efficient Model-free Reinforcement Learning from LTL Specifications with Optimality Guarantees
May 03, 2023Linear Temporal Logic (LTL) is widely used to specify high-level objectives for system policies, and it is highly desirable for autonomous systems to learn the optimal policy with respect to such specifications. However, learning the optimal policy from LTL specifications is not trivial. We present a model-free Reinforcement Learning (RL) approach that efficiently learns an optimal policy for an unknown stochastic system, modelled using Markov Decision Processes (MDPs). We propose a novel and more general product MDP, reward structure and discounting mechanism that, when applied in conjunction with off-the-shelf model-free RL algorithms, efficiently learn the optimal policy that maximizes the probability of satisfying a given LTL specification with optimality guarantees. We also provide improved theoretical results on choosing the key parameters in RL to ensure optimality. To directly evaluate the learned policy, we adopt probabilistic model checker PRISM to compute the probability of the policy satisfying such specifications. Several experiments on various tabular MDP environments across different LTL tasks demonstrate the improved sample efficiency and optimal policy convergence.