 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsoperimetry is All We Need: Langevin Posterior Sampling for RL with Sublinear Regret
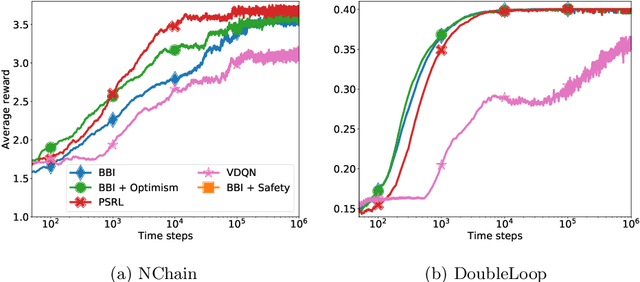
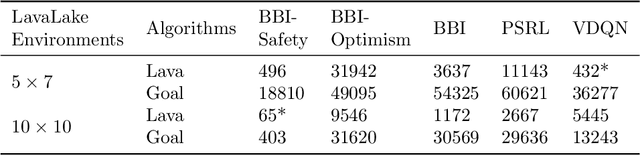
Dec 30, 2024In Reinforcement Learning (RL) theory, we impose restrictive assumptions to design an algorithm with provably sublinear regret. Common assumptions, like linear or RKHS models, and Gaussian or log-concave posteriors over the models, do not explain practical success of RL across a wider range of distributions and models. Thus, we study how to design RL algorithms with sublinear regret for isoperimetric distributions, specifically the ones satisfying the Log-Sobolev Inequality (LSI). LSI distributions include the standard setups of RL and others, such as many non-log-concave and perturbed distributions. First, we show that the Posterior Sampling-based RL (PSRL) yields sublinear regret if the data distributions satisfy LSI under some mild additional assumptions. Also, when we cannot compute or sample from an exact posterior, we propose a Langevin sampling-based algorithm design: LaPSRL. We show that LaPSRL achieves order optimal regret and subquadratic complexity per episode. Finally, we deploy LaPSRL with a Langevin sampler -- SARAH-LD, and test it for different bandit and MDP environments. Experimental results validate the generality of LaPSRL across environments and its competitive performance with respect to the baselines.
Minimax-Bayes Reinforcement Learning
Feb 21, 2023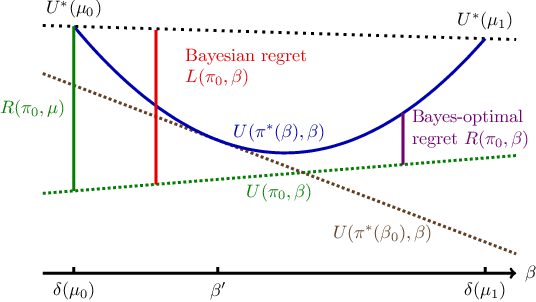

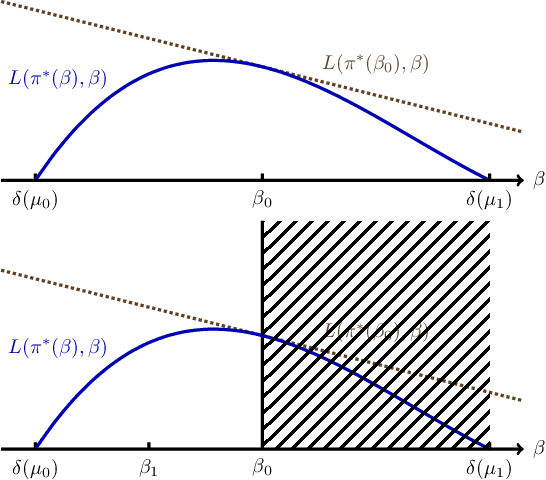
While the Bayesian decision-theoretic framework offers an elegant solution to the problem of decision making under uncertainty, one question is how to appropriately select the prior distribution. One idea is to employ a worst-case prior. However, this is not as easy to specify in sequential decision making as in simple statistical estimation problems. This paper studies (sometimes approximate) minimax-Bayes solutions for various reinforcement learning problems to gain insights into the properties of the corresponding priors and policies. We find that while the worst-case prior depends on the setting, the corresponding minimax policies are more robust than those that assume a standard (i.e. uniform) prior.
Inferential Induction: Joint Bayesian Estimation of MDPs and Value Functions
Feb 08, 2020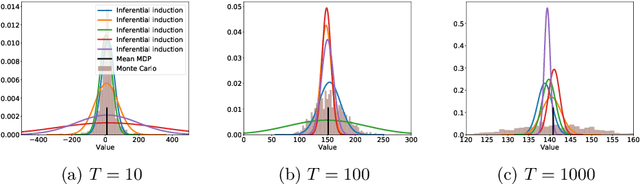

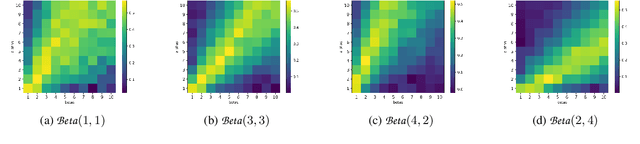
Bayesian reinforcement learning (BRL) offers a decision-theoretic solution to the problem of reinforcement learning. However, typical model-based BRL algorithms have focused either on ma intaining a posterior distribution on models or value functions and combining this with approx imate dynamic programming or tree search. This paper describes a novel backwards induction pri nciple for performing joint Bayesian estimation of models and value functions, from which many new BRL algorithms can be obtained. We demonstrate this idea with algorithms and experiments in discrete state spaces.
Spectral Analysis of Kernel and Neural Embeddings: Optimization and Generalization
May 13, 2019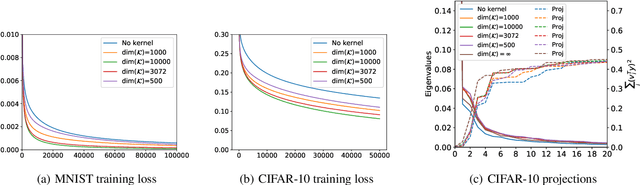
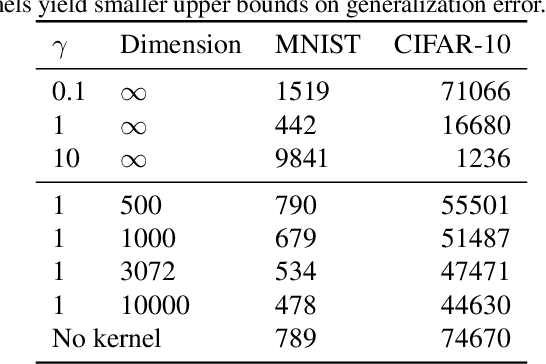
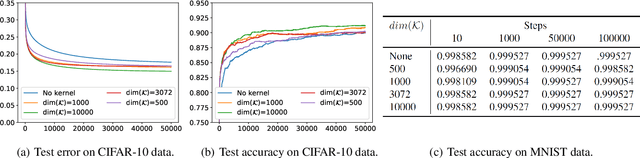
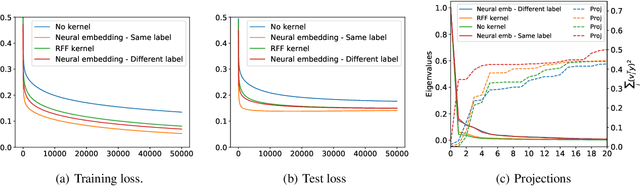
We extend the recent results of (Arora et al., 2019) by a spectral analysis of representations corresponding to kernel and neural embeddings. They showed that in a simple single layer network, the alignment of the labels to the eigenvectors of the corresponding Gram matrix determines both the convergence of the optimization during training as well as the generalization properties. We show quantitatively that kernel and neural representations improve both optimization and generalization. We give results for the Gaussian kernel and approximations by random Fourier features as well as for embeddings produced by two layer networks trained on different tasks.
Learning to Play Guess Who? and Inventing a Grounded Language as a Consequence
Mar 15, 2017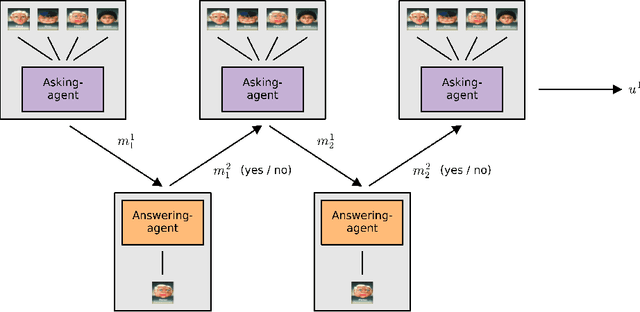
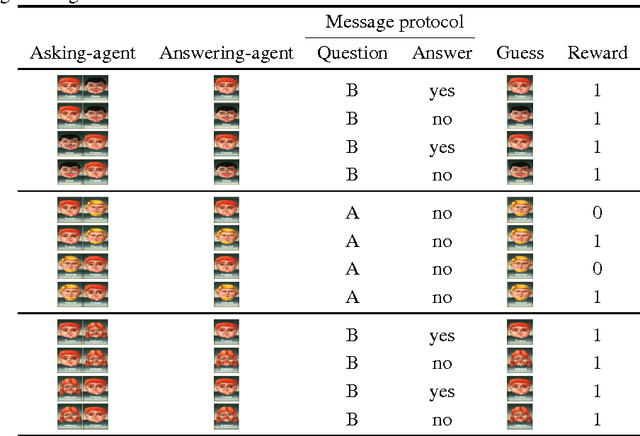
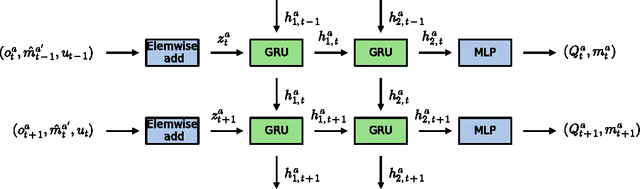
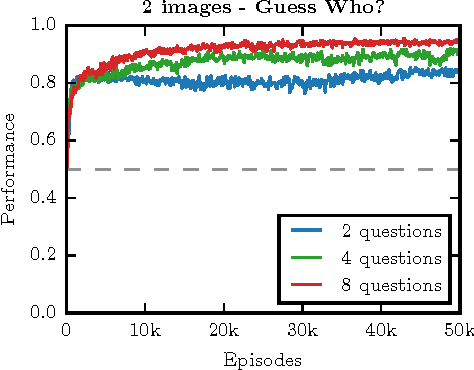
Acquiring your first language is an incredible feat and not easily duplicated. Learning to communicate using nothing but a few pictureless books, a corpus, would likely be impossible even for humans. Nevertheless, this is the dominating approach in most natural language processing today. As an alternative, we propose the use of situated interactions between agents as a driving force for communication, and the framework of Deep Recurrent Q-Networks for evolving a shared language grounded in the provided environment. We task the agents with interactive image search in the form of the game Guess Who?. The images from the game provide a non trivial environment for the agents to discuss and a natural grounding for the concepts they decide to encode in their communication. Our experiments show that the agents learn not only to encode physical concepts in their words, i.e. grounding, but also that the agents learn to hold a multi-step dialogue remembering the state of the dialogue from step to step.