 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-RASTER: Contraction Clustering for Evolving Data Streams
Nov 21, 2019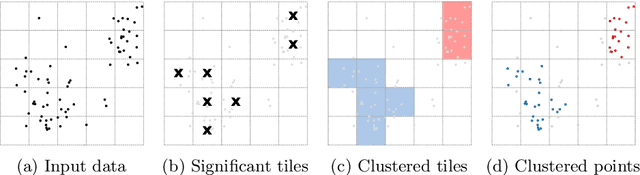
Contraction Clustering (RASTER) is a very fast algorithm for density-based clustering, which requires only a single pass. It can process arbitrary amounts of data in linear time and in constant memory, quickly identifying approximate clusters. It also exhibits good scalability in the presence of multiple CPU cores. Yet, RASTER is limited to batch processing. In contrast, S-RASTER is an adaptation of RASTER to the stream processing paradigm that is able to identify clusters in evolving data streams. This algorithm retains the main benefits of its parent algorithm, i.e. single-pass linear time cost and constant memory requirements for each discrete time step in the sliding window. The sliding window is efficiently pruned, and clustering is still performed in linear time. Like RASTER, S-RASTER trades off an often negligible amount of precision for speed. It is therefore very well suited to real-world scenarios where clustering does not happen continually but only periodically. We describe the algorithm, including a discussion of implementation details.
Contraction Clustering : A Very Fast Big Data Algorithm for Sequential and Parallel Density-Based Clustering in Linear Time, Constant Memory, and a Single Pass
Jul 08, 2019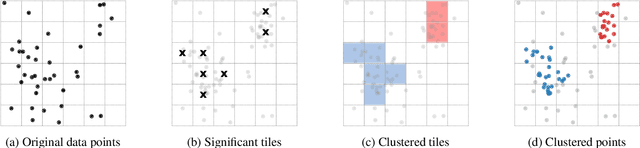

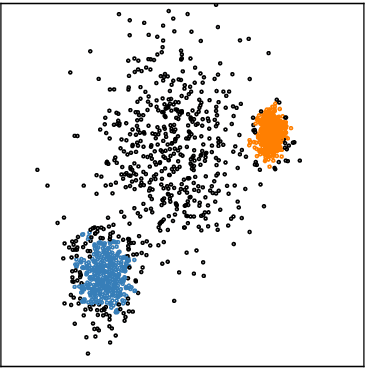
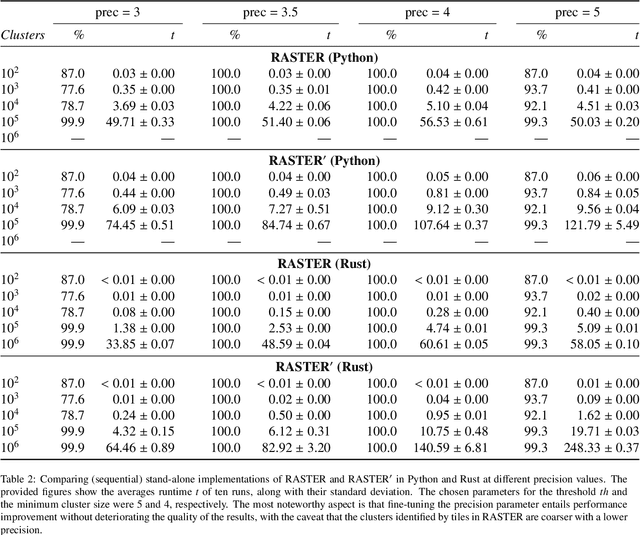
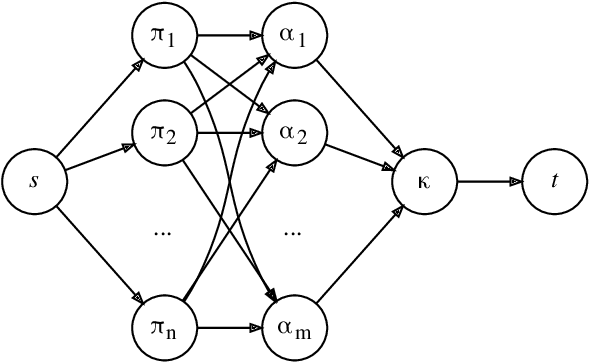
Clustering is an essential data mining tool for analyzing and grouping similar objects. In big data applications, however, many clustering algorithms are infeasible due to their high memory requirements and/or unfavorable runtime complexity. In contrast, Contraction Clustering (RASTER) is a single-pass algorithm for identifying density-based clusters with linear time complexity. Due to its favorable runtime and the fact that its memory requirements are constant, this algorithm is highly suitable for big data applications where the amount of data to be processed is huge. It consists of two steps: (1) a contraction step which projects objects onto tiles and (2) an agglomeration step which groups tiles into clusters. This algorithm is extremely fast in both sequential and parallel execution. In single-threaded execution on a contemporary workstation, an implementation in Rust processes a batch of 500 million points with 1 million clusters in less than 50 seconds. The speedup due to parallelization is significant, amounting to a factor of around 4 on an 8-core machine.
Learning to Play Guess Who? and Inventing a Grounded Language as a Consequence
Mar 15, 2017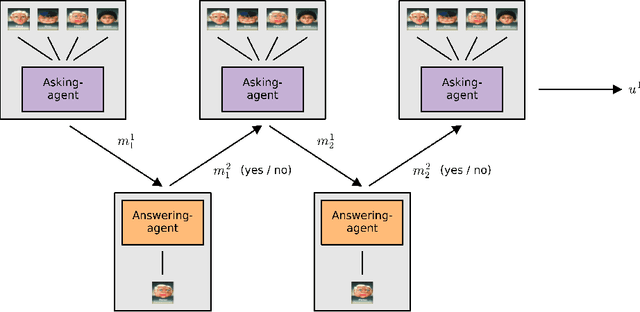
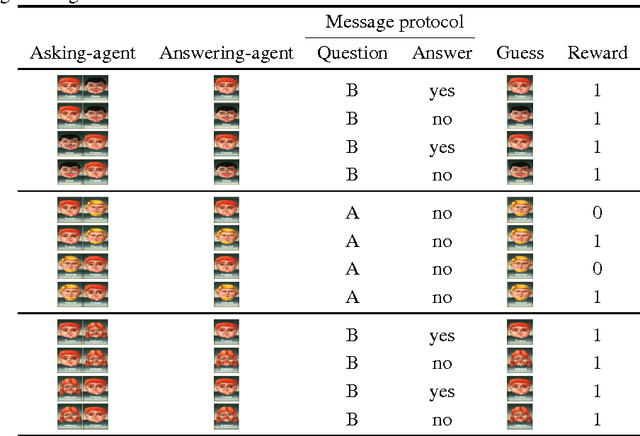
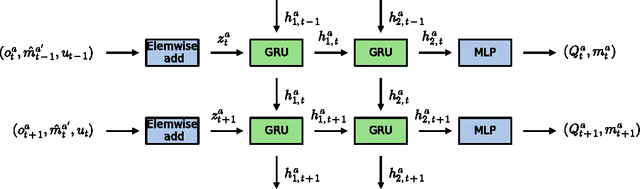
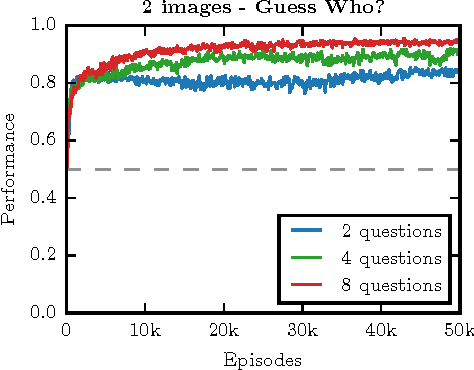
Acquiring your first language is an incredible feat and not easily duplicated. Learning to communicate using nothing but a few pictureless books, a corpus, would likely be impossible even for humans. Nevertheless, this is the dominating approach in most natural language processing today. As an alternative, we propose the use of situated interactions between agents as a driving force for communication, and the framework of Deep Recurrent Q-Networks for evolving a shared language grounded in the provided environment. We task the agents with interactive image search in the form of the game Guess Who?. The images from the game provide a non trivial environment for the agents to discuss and a natural grounding for the concepts they decide to encode in their communication. Our experiments show that the agents learn not only to encode physical concepts in their words, i.e. grounding, but also that the agents learn to hold a multi-step dialogue remembering the state of the dialogue from step to step.