 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-RASTER: Contraction Clustering for Evolving Data Streams
Paper and Code
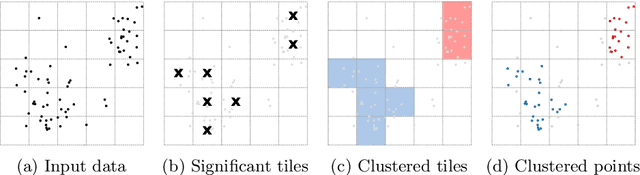
Contraction Clustering (RASTER) is a very fast algorithm for density-based clustering, which requires only a single pass. It can process arbitrary amounts of data in linear time and in constant memory, quickly identifying approximate clusters. It also exhibits good scalability in the presence of multiple CPU cores. Yet, RASTER is limited to batch processing. In contrast, S-RASTER is an adaptation of RASTER to the stream processing paradigm that is able to identify clusters in evolving data streams. This algorithm retains the main benefits of its parent algorithm, i.e. single-pass linear time cost and constant memory requirements for each discrete time step in the sliding window. The sliding window is efficiently pruned, and clustering is still performed in linear time. Like RASTER, S-RASTER trades off an often negligible amount of precision for speed. It is therefore very well suited to real-world scenarios where clustering does not happen continually but only periodically. We describe the algorithm, including a discussion of implementation details.