 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContraction Clustering : A Very Fast Big Data Algorithm for Sequential and Parallel Density-Based Clustering in Linear Time, Constant Memory, and a Single Pass
Paper and Code
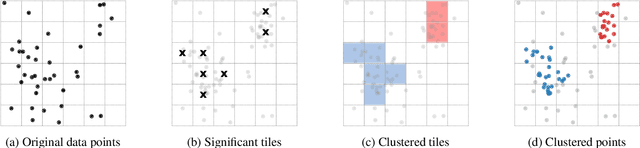

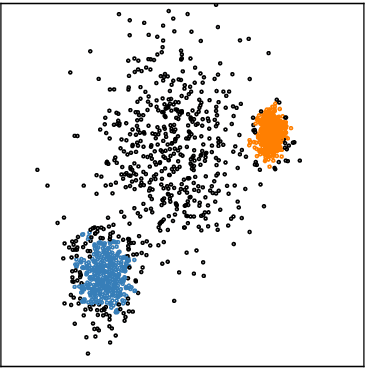
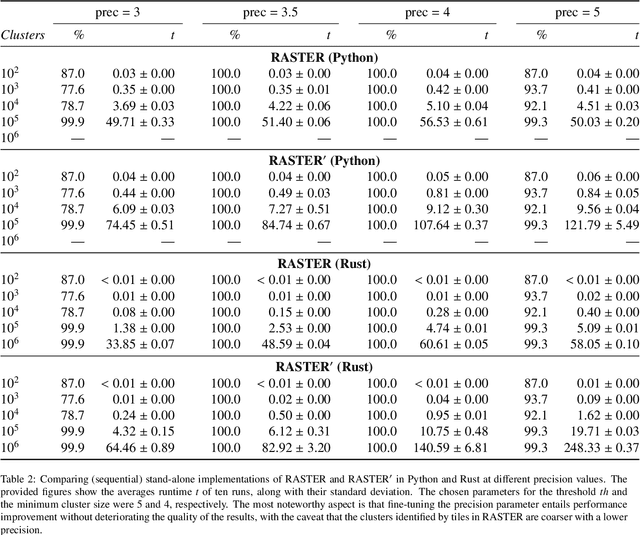
Clustering is an essential data mining tool for analyzing and grouping similar objects. In big data applications, however, many clustering algorithms are infeasible due to their high memory requirements and/or unfavorable runtime complexity. In contrast, Contraction Clustering (RASTER) is a single-pass algorithm for identifying density-based clusters with linear time complexity. Due to its favorable runtime and the fact that its memory requirements are constant, this algorithm is highly suitable for big data applications where the amount of data to be processed is huge. It consists of two steps: (1) a contraction step which projects objects onto tiles and (2) an agglomeration step which groups tiles into clusters. This algorithm is extremely fast in both sequential and parallel execution. In single-threaded execution on a contemporary workstation, an implementation in Rust processes a batch of 500 million points with 1 million clusters in less than 50 seconds. The speedup due to parallelization is significant, amounting to a factor of around 4 on an 8-core machine.