 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Representations for Manipulation of Sentiment in Text
Dec 22, 2017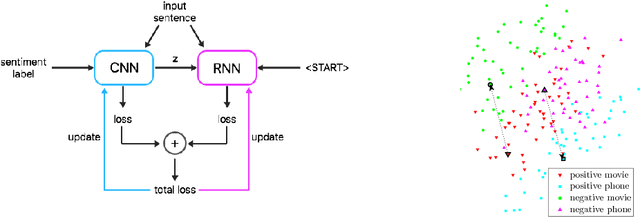

The ability to change arbitrary aspects of a text while leaving the core message intact could have a strong impact in fields like marketing and politics by enabling e.g. automatic optimization of message impact and personalized language adapted to the receiver's profile. In this paper we take a first step towards such a system by presenting an algorithm that can manipulate the sentiment of a text while preserving its semantics using disentangled representations. Validation is performed by examining trajectories in embedding space and analyzing transformed sentences for semantic preservation while expression of desired sentiment shift.
Query-Based Abstractive Summarization Using Neural Networks
Dec 17, 2017


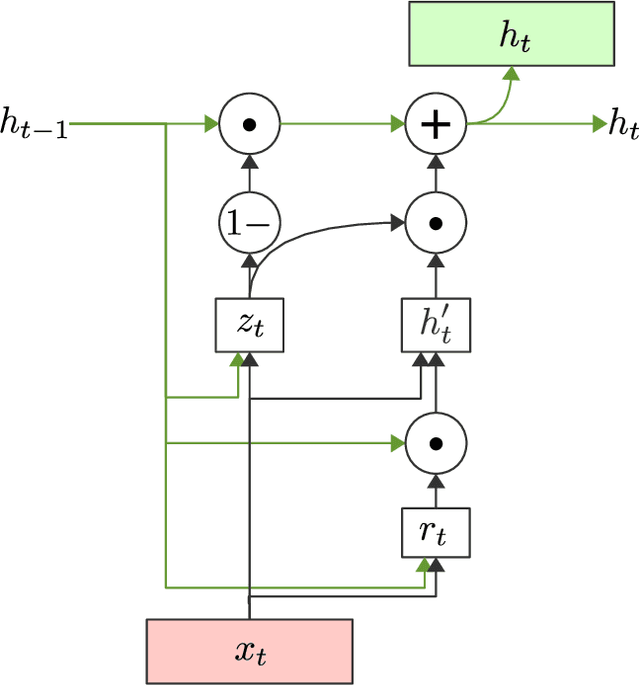
In this paper, we present a model for generating summaries of text documents with respect to a query. This is known as query-based summarization. We adapt an existing dataset of news article summaries for the task and train a pointer-generator model using this dataset. The generated summaries are evaluated by measuring similarity to reference summaries. Our results show that a neural network summarization model, similar to existing neural network models for abstractive summarization, can be constructed to make use of queries to produce targeted summaries.
Learning to Play Guess Who? and Inventing a Grounded Language as a Consequence
Mar 15, 2017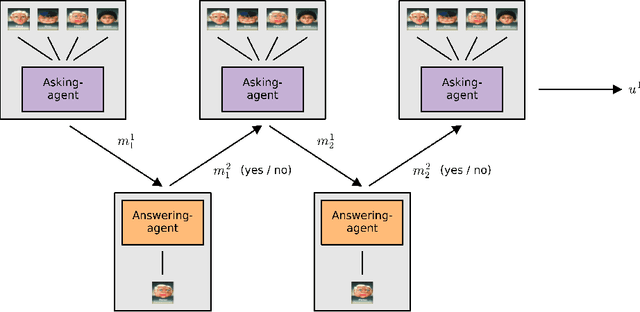
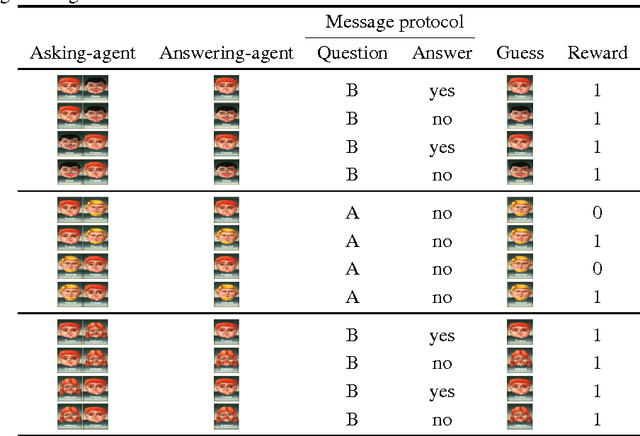
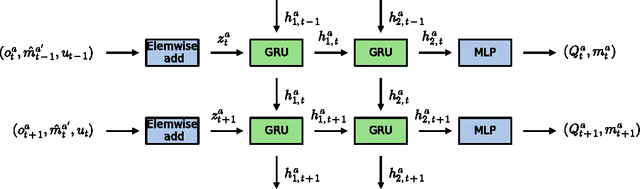
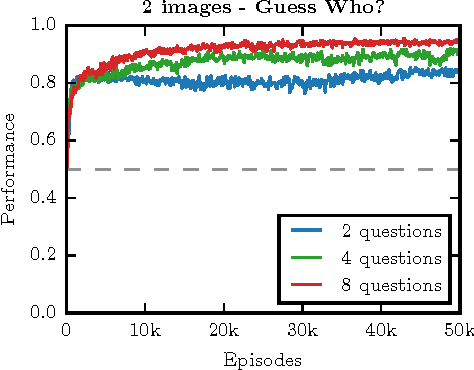
Acquiring your first language is an incredible feat and not easily duplicated. Learning to communicate using nothing but a few pictureless books, a corpus, would likely be impossible even for humans. Nevertheless, this is the dominating approach in most natural language processing today. As an alternative, we propose the use of situated interactions between agents as a driving force for communication, and the framework of Deep Recurrent Q-Networks for evolving a shared language grounded in the provided environment. We task the agents with interactive image search in the form of the game Guess Who?. The images from the game provide a non trivial environment for the agents to discuss and a natural grounding for the concepts they decide to encode in their communication. Our experiments show that the agents learn not only to encode physical concepts in their words, i.e. grounding, but also that the agents learn to hold a multi-step dialogue remembering the state of the dialogue from step to step.
Word Sense Disambiguation using a Bidirectional LSTM
Nov 18, 2016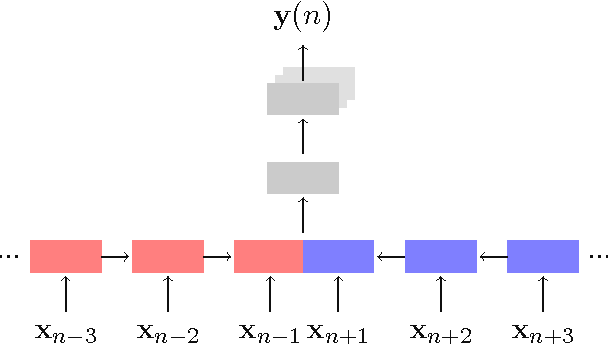

In this paper we present a clean, yet effective, model for word sense disambiguation. Our approach leverage a bidirectional long short-term memory network which is shared between all words. This enables the model to share statistical strength and to scale well with vocabulary size. The model is trained end-to-end, directly from the raw text to sense labels, and makes effective use of word order. We evaluate our approach on two standard datasets, using identical hyperparameter settings, which are in turn tuned on a third set of held out data. We employ no external resources (e.g. knowledge graphs, part-of-speech tagging, etc), language specific features, or hand crafted rules, but still achieve statistically equivalent results to the best state-of-the-art systems, that employ no such limitations.