 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskMed: Decoupled Mask and Class Prediction for Medical Image Segmentation
Nov 19, 2025Medical image segmentation typically adopts a point-wise convolutional segmentation head to predict dense labels, where each output channel is heuristically tied to a specific class. This rigid design limits both feature sharing and semantic generalization. In this work, we propose a unified decoupled segmentation head that separates multi-class prediction into class-agnostic mask prediction and class label prediction using shared object queries. Furthermore, we introduce a Full-Scale Aware Deformable Transformer module that enables low-resolution encoder features to attend across full-resolution encoder features via deformable attention, achieving memory-efficient and spatially aligned full-scale fusion. Our proposed method, named MaskMed, achieves state-of-the-art performance, surpassing nnUNet by +2.0% Dice on AMOS 2022 and +6.9% Dice on BTCV.
MSLoRA: Multi-Scale Low-Rank Adaptation via Attention Reweighting
Nov 16, 2025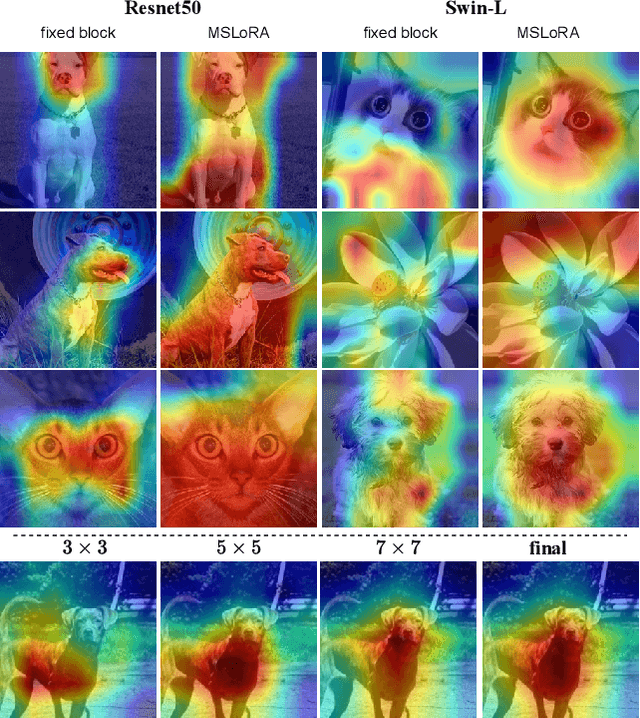
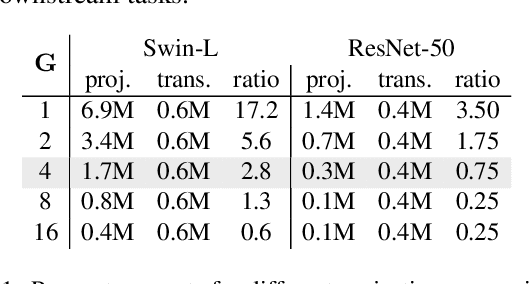
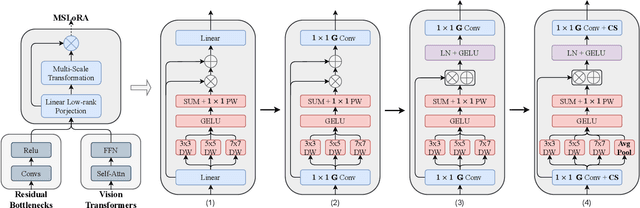
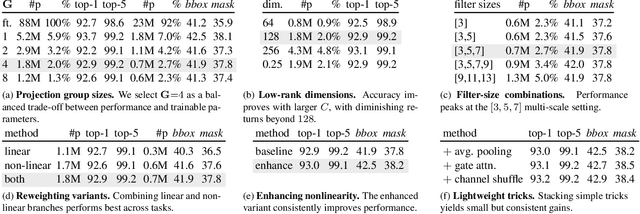
We introduce MSLoRA, a backbone-agnostic, parameter-efficient adapter that reweights feature responses rather than re-tuning the underlying backbone. Existing low-rank adaptation methods are mostly confined to vision transformers (ViTs) and struggle to generalize across architectures. MSLoRA unifies adaptation for both convolutional neural networks (CNNs) and ViTs by combining a low-rank linear projection with a multi-scale nonlinear transformation that jointly modulates spatial and channel attention. The two components are fused through pointwise multiplication and a residual connection, yielding a lightweight module that shifts feature attention while keeping pretrained weights frozen. Extensive experiments demonstrate that MSLoRA consistently improves transfer performance on classification, detection, and segmentation tasks with roughly less than 5\% of backbone parameters. The design further enables stable optimization, fast convergence, and strong cross-architecture generalization. By reweighting rather than re-tuning, MSLoRA provides a simple and universal approach for efficient adaptation of frozen vision backbones.
RFMedSAM 2: Automatic Prompt Refinement for Enhanced Volumetric Medical Image Segmentation with SAM 2
Feb 04, 2025



Segment Anything Model 2 (SAM 2), a prompt-driven foundation model extending SAM to both image and video domains, has shown superior zero-shot performance compared to its predecessor. Building on SAM's success in medical image segmentation, SAM 2 presents significant potential for further advancement. However, similar to SAM, SAM 2 is limited by its output of binary masks, inability to infer semantic labels, and dependence on precise prompts for the target object area. Additionally, direct application of SAM and SAM 2 to medical image segmentation tasks yields suboptimal results. In this paper, we explore the upper performance limit of SAM 2 using custom fine-tuning adapters, achieving a Dice Similarity Coefficient (DSC) of 92.30% on the BTCV dataset, surpassing the state-of-the-art nnUNet by 12%. Following this, we address the prompt dependency by investigating various prompt generators. We introduce a UNet to autonomously generate predicted masks and bounding boxes, which serve as input to SAM 2. Subsequent dual-stage refinements by SAM 2 further enhance performance. Extensive experiments show that our method achieves state-of-the-art results on the AMOS2022 dataset, with a Dice improvement of 2.9% compared to nnUNet, and outperforms nnUNet by 6.4% on the BTCV dataset.
Rethinking Timesteps Samplers and Prediction Types
Feb 04, 2025



Diffusion models suffer from the huge consumption of time and resources to train. For example, diffusion models need hundreds of GPUs to train for several weeks for a high-resolution generative task to meet the requirements of an extremely large number of iterations and a large batch size. Training diffusion models become a millionaire's game. With limited resources that only fit a small batch size, training a diffusion model always fails. In this paper, we investigate the key reasons behind the difficulties of training diffusion models with limited resources. Through numerous experiments and demonstrations, we identified a major factor: the significant variation in the training losses across different timesteps, which can easily disrupt the progress made in previous iterations. Moreover, different prediction types of $x_0$ exhibit varying effectiveness depending on the task and timestep. We hypothesize that using a mixed-prediction approach to identify the most accurate $x_0$ prediction type could potentially serve as a breakthrough in addressing this issue. In this paper, we outline several challenges and insights, with the hope of inspiring further research aimed at tackling the limitations of training diffusion models with constrained resources, particularly for high-resolution tasks.
Fine-grained Text to Image Synthesis
Dec 10, 2024Fine-grained text to image synthesis involves generating images from texts that belong to different categories. In contrast to general text to image synthesis, in fine-grained synthesis there is high similarity between images of different subclasses, and there may be linguistic discrepancy among texts describing the same image. Recent Generative Adversarial Networks (GAN), such as the Recurrent Affine Transformation (RAT) GAN model, are able to synthesize clear and realistic images from texts. However, GAN models ignore fine-grained level information. In this paper we propose an approach that incorporates an auxiliary classifier in the discriminator and a contrastive learning method to improve the accuracy of fine-grained details in images synthesized by RAT GAN. The auxiliary classifier helps the discriminator classify the class of images, and helps the generator synthesize more accurate fine-grained images. The contrastive learning method minimizes the similarity between images from different subclasses and maximizes the similarity between images from the same subclass. We evaluate on several state-of-the-art methods on the commonly used CUB-200-2011 bird dataset and Oxford-102 flower dataset, and demonstrated superior performance.
LSTM Framework for Classification of Radar and Communications Signals
May 04, 2023



Although radar and communications signal classification are usually treated separately, they share similar characteristics, and methods applied in one domain can be potentially applied in the other. We propose a simple and unified scheme for the classification of radar and communications signals using Long Short-Term Memory (LSTM) neural networks. This proposal provides an improvement of the state of the art on radar signals where LSTM models are starting to be applied within schemes of higher complexity. To date, there is no standard public dataset for radar signals. Therefore, we propose DeepRadar2022, a radar dataset used in our systematic evaluations that is available publicly and will facilitate a standard comparison between methods.
Semi-supervised Domain Adaptation for Semantic Segmentation
Oct 20, 2021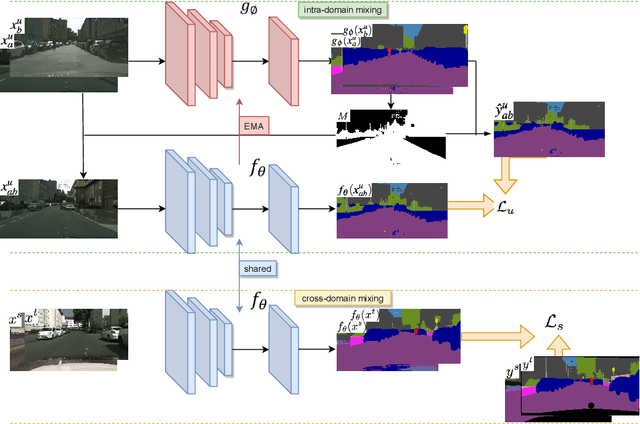
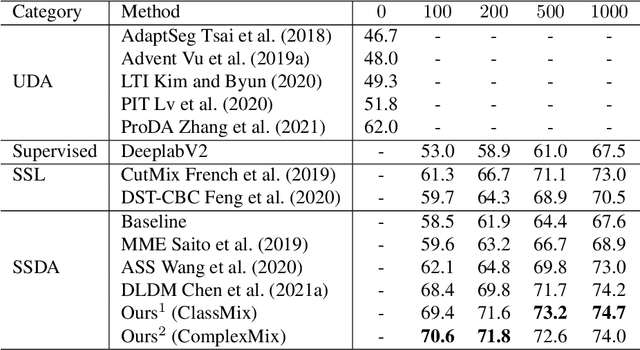
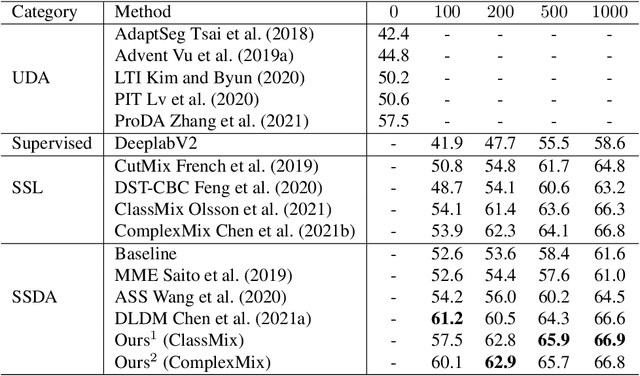

Deep learning approaches for semantic segmentation rely primarily on supervised learning approaches and require substantial efforts in producing pixel-level annotations. Further, such approaches may perform poorly when applied to unseen image domains. To cope with these limitations, both unsupervised domain adaptation (UDA) with full source supervision but without target supervision and semi-supervised learning (SSL) with partial supervision have been proposed. While such methods are effective at aligning different feature distributions, there is still a need to efficiently exploit unlabeled data to address the performance gap with respect to fully-supervised methods. In this paper we address semi-supervised domain adaptation (SSDA) for semantic segmentation, where a large amount of labeled source data as well as a small amount of labeled target data are available. We propose a novel and effective two-step semi-supervised dual-domain adaptation (SSDDA) approach to address both cross- and intra-domain gaps in semantic segmentation. The proposed framework is comprised of two mixing modules. First, we conduct a cross-domain adaptation via an image-level mixing strategy, which learns to align the distribution shift of features between the source data and target data. Second, intra-domain adaptation is achieved using a separate student-teacher network which is built to generate category-level data augmentation by mixing unlabeled target data in a way that respects predicted object boundaries. We demonstrate that the proposed approach outperforms state-of-the-art methods on two common synthetic-to-real semantic segmentation benchmarks. An extensive ablation study is provided to further validate the effectiveness of our approach.
Mask-based Data Augmentation for Semi-supervised Semantic Segmentation
Jan 25, 2021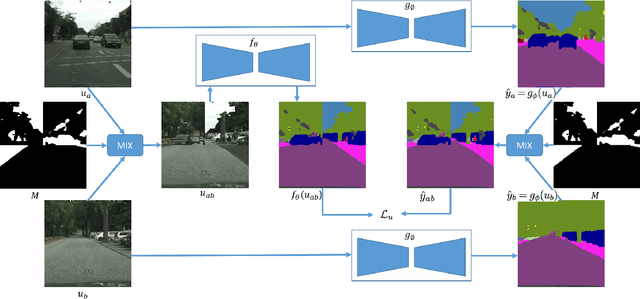
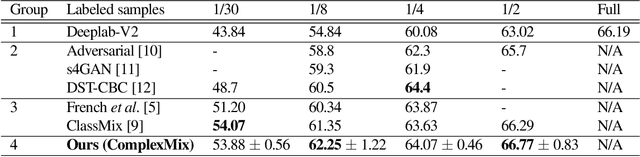
Semantic segmentation using convolutional neural networks (CNN) is a crucial component in image analysis. Training a CNN to perform semantic segmentation requires a large amount of labeled data, where the production of such labeled data is both costly and labor intensive. Semi-supervised learning algorithms address this issue by utilizing unlabeled data and so reduce the amount of labeled data needed for training. In particular, data augmentation techniques such as CutMix and ClassMix generate additional training data from existing labeled data. In this paper we propose a new approach for data augmentation, termed ComplexMix, which incorporates aspects of CutMix and ClassMix with improved performance. The proposed approach has the ability to control the complexity of the augmented data while attempting to be semantically-correct and address the tradeoff between complexity and correctness. The proposed ComplexMix approach is evaluated on a standard dataset for semantic segmentation and compared to other state-of-the-art techniques. Experimental results show that our method yields improvement over state-of-the-art methods on standard datasets for semantic image segmentation.
Domain Adaptation on Semantic Segmentation for Aerial Images
Dec 11, 2020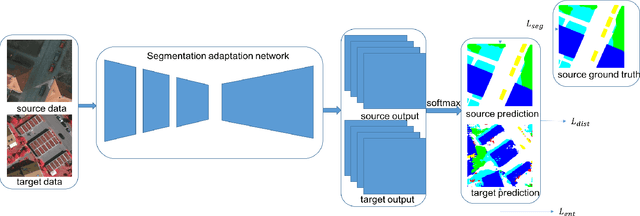
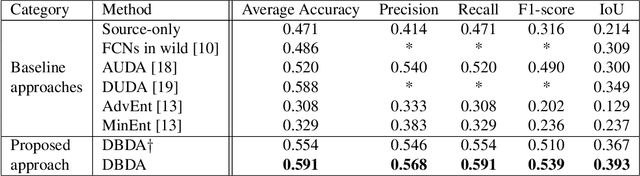

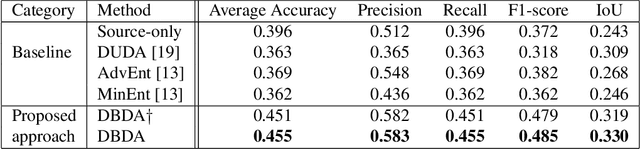
Semantic segmentation has achieved significant advances in recent years. While deep neural networks perform semantic segmentation well, their success rely on pixel level supervision which is expensive and time-consuming. Further, training using data from one domain may not generalize well to data from a new domain due to a domain gap between data distributions in the different domains. This domain gap is particularly evident in aerial images where visual appearance depends on the type of environment imaged, season, weather, and time of day when the environment is imaged. Subsequently, this distribution gap leads to severe accuracy loss when using a pretrained segmentation model to analyze new data with different characteristics. In this paper, we propose a novel unsupervised domain adaptation framework to address domain shift in the context of aerial semantic image segmentation. To this end, we solve the problem of domain shift by learn the soft label distribution difference between the source and target domains. Further, we also apply entropy minimization on the target domain to produce high-confident prediction rather than using high-confident prediction by pseudo-labeling. We demonstrate the effectiveness of our domain adaptation framework using the challenge image segmentation dataset of ISPRS, and show improvement over state-of-the-art methods in terms of various metrics.
Adaptive WGAN with loss change rate balancing
Aug 28, 2020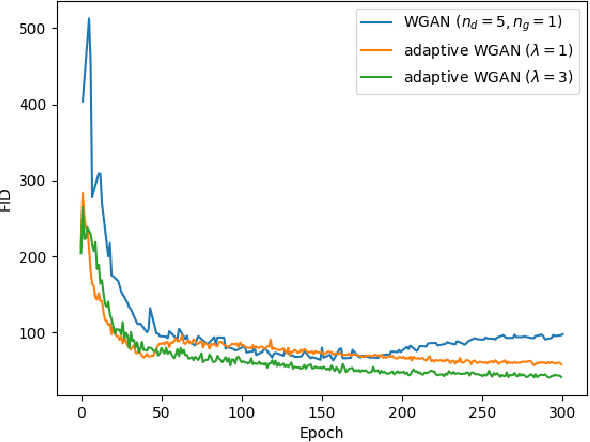
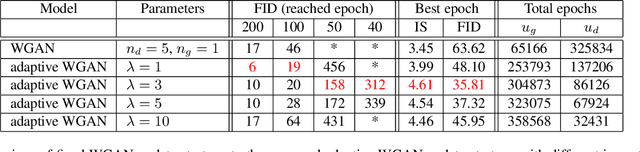
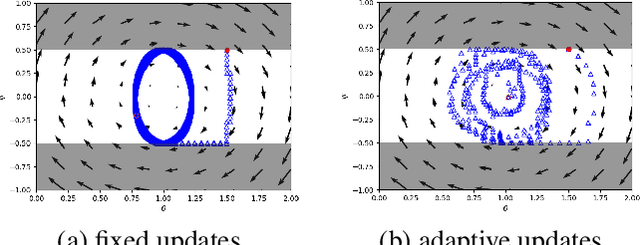
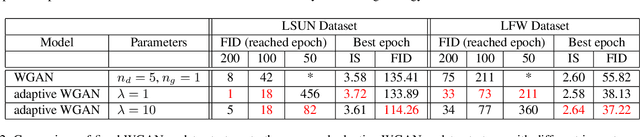
Optimizing the discriminator in Generative Adversarial Networks (GANs) to completion in the inner training loop is computationally prohibitive, and on finite datasets would result in overfitting. To address this, a common update strategy is to alternate between k optimization steps for the discriminator D and one optimization step for the generator G. This strategy is repeated in various GAN algorithms where k is selected empirically. In this paper, we show that this update strategy is not optimal in terms of accuracy and convergence speed, and propose a new update strategy for Wasserstein GANs (WGAN) and other GANs using the WGAN loss(e.g. WGAN-GP, Deblur GAN, and Super-resolution GAN). The proposed update strategy is based on a loss change ratio comparison of G and D. We demonstrate that the proposed strategy improves both convergence speed and accuracy.