 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Foundation Models for Music Understanding
Sep 15, 2024
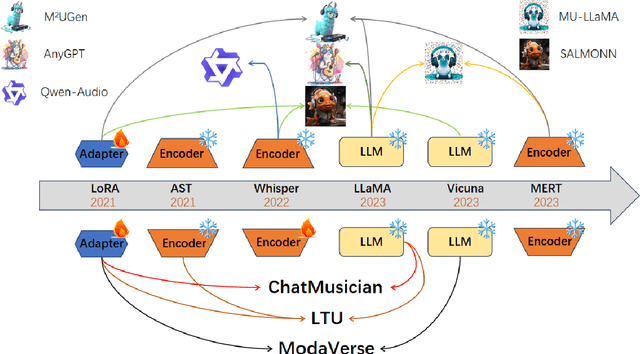
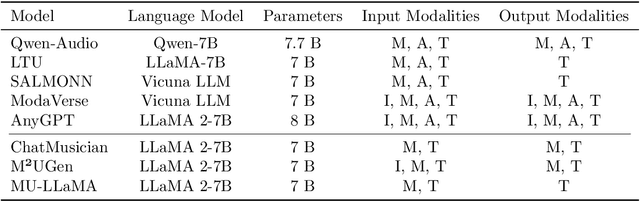
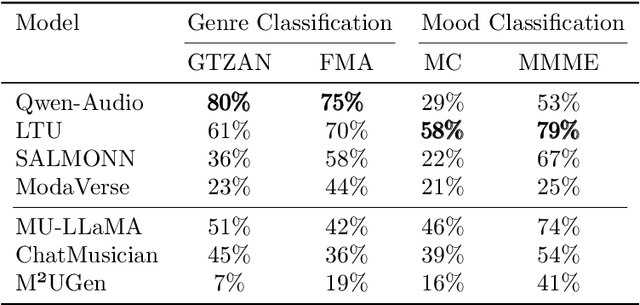
Music is essential in daily life, fulfilling emotional and entertainment needs, and connecting us personally, socially, and culturally. A better understanding of music can enhance our emotions, cognitive skills, and cultural connections. The rapid advancement of artificial intelligence (AI) has introduced new ways to analyze music, aiming to replicate human understanding of music and provide related services. While the traditional models focused on audio features and simple tasks, the recent development of large language models (LLMs) and foundation models (FMs), which excel in various fields by integrating semantic information and demonstrating strong reasoning abilities, could capture complex musical features and patterns, integrate music with language and incorporate rich musical, emotional and psychological knowledge. Therefore, they have the potential in handling complex music understanding tasks from a semantic perspective, producing outputs closer to human perception. This work, to our best knowledge, is one of the early reviews of the intersection of AI techniques and music understanding. We investigated, analyzed, and tested recent large-scale music foundation models in respect of their music comprehension abilities. We also discussed their limitations and proposed possible future directions, offering insights for researchers in this field.
swTVM: Exploring the Automated Compilation for Deep Learning on Sunway Architecture
Apr 18, 2019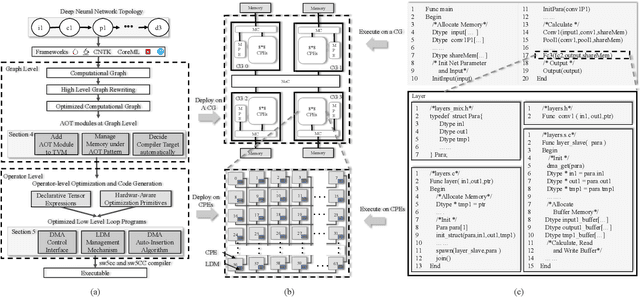
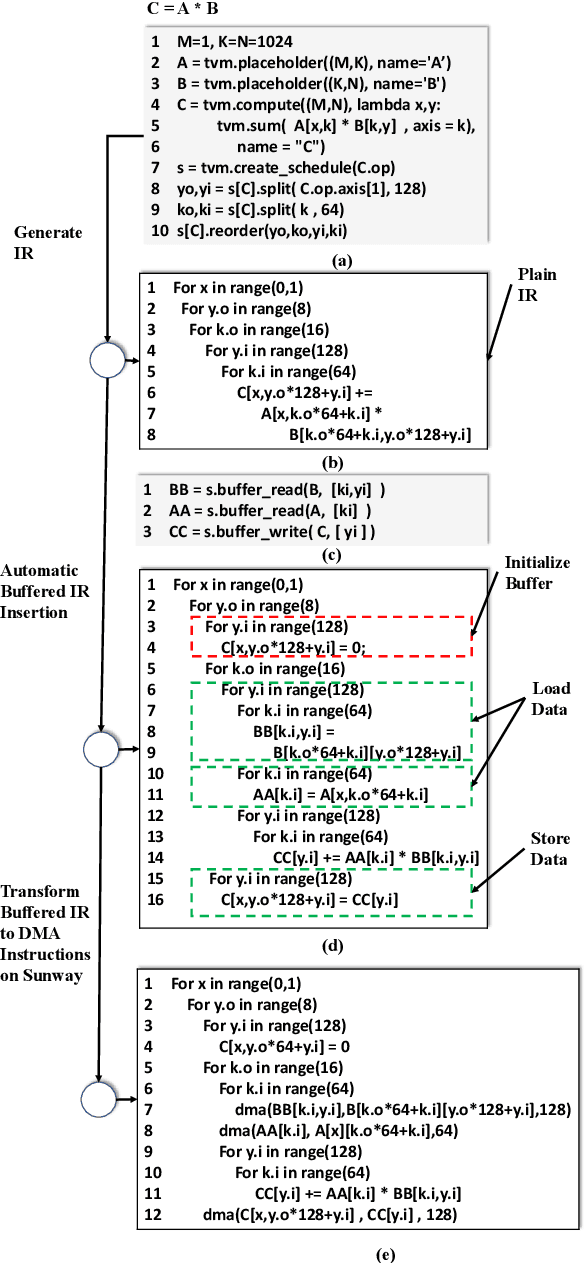

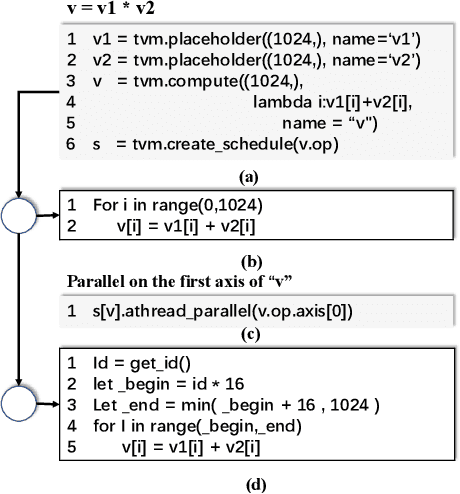
The flourish of deep learning frameworks and hardware platforms has been demanding an efficient compiler that can shield the diversity in both software and hardware in order to provide application portability. Among the exiting deep learning compilers, TVM is well known for its efficiency in code generation and optimization across diverse hardware devices. In the meanwhile, the Sunway many-core processor renders itself as a competitive candidate for its attractive computational power in both scientific and deep learning applications. This paper combines the trends in these two directions. Specifically, we propose swTVM that extends the original TVM to support ahead-of-time compilation for architecture requiring cross-compilation such as Sunway. In addition, we leverage the architecture features during the compilation such as core group for massive parallelism, DMA for high bandwidth memory transfer and local device memory for data locality, in order to generate efficient code for deep learning application on Sunway. The experimental results show the ability of swTVM to automatically generate code for various deep neural network models on Sunway. The performance of automatically generated code for AlexNet and VGG-19 by swTVM achieves 6.71x and 2.45x speedup on average than hand-optimized OpenACC implementations on convolution and fully connected layers respectively. This work is the first attempt from the compiler perspective to bridge the gap of deep learning and high performance architecture particularly with productivity and efficiency in mind. We would like to open source the implementation so that more people can embrace the power of deep learning compiler and Sunway many-core processor.
Layered Optical Flow Estimation Using a Deep Neural Network with a Soft Mask
May 09, 2018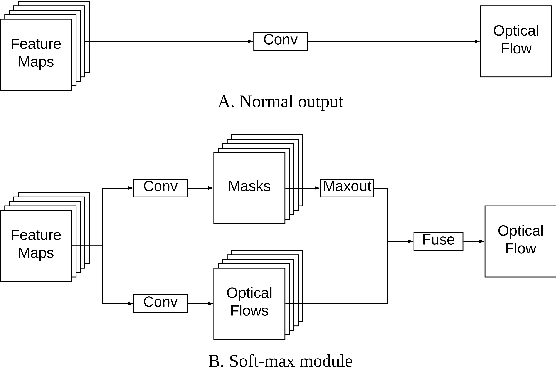
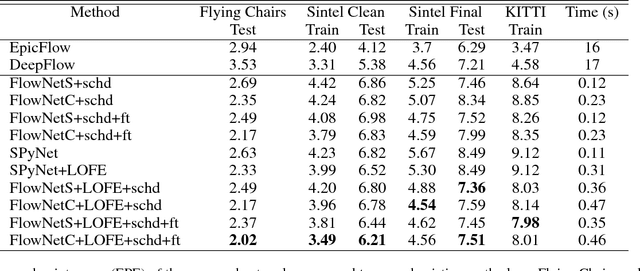
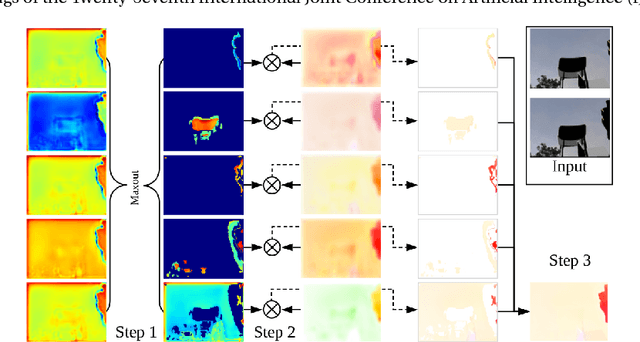
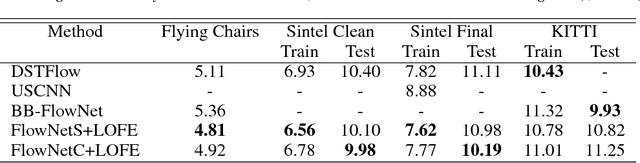
Using a layered representation for motion estimation has the advantage of being able to cope with discontinuities and occlusions. In this paper, we learn to estimate optical flow by combining a layered motion representation with deep learning. Instead of pre-segmenting the image to layers, the proposed approach automatically generates a layered representation of optical flow using the proposed soft-mask module. The essential components of the soft-mask module are maxout and fuse operations, which enable a disjoint layered representation of optical flow and more accurate flow estimation. We show that by using masks the motion estimate results in a quadratic function of input features in the output layer. The proposed soft-mask module can be added to any existing optical flow estimation networks by replacing their flow output layer. In this work, we use FlowNet as the base network to which we add the soft-mask module. The resulting network is tested on three well-known benchmarks with both supervised and unsupervised flow estimation tasks. Evaluation results show that the proposed network achieve better results compared with the original FlowNet.
CGMOS: Certainty Guided Minority OverSampling
Jul 21, 2016



Handling imbalanced datasets is a challenging problem that if not treated correctly results in reduced classification performance. Imbalanced datasets are commonly handled using minority oversampling, whereas the SMOTE algorithm is a successful oversampling algorithm with numerous extensions. SMOTE extensions do not have a theoretical guarantee during training to work better than SMOTE and in many instances their performance is data dependent. In this paper we propose a novel extension to the SMOTE algorithm with a theoretical guarantee for improved classification performance. The proposed approach considers the classification performance of both the majority and minority classes. In the proposed approach CGMOS (Certainty Guided Minority OverSampling) new data points are added by considering certainty changes in the dataset. The paper provides a proof that the proposed algorithm is guaranteed to work better than SMOTE for training data. Further experimental results on 30 real-world datasets show that CGMOS works better than existing algorithms when using 6 different classifiers.