 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeswTVM: Exploring the Automated Compilation for Deep Learning on Sunway Architecture
Apr 18, 2019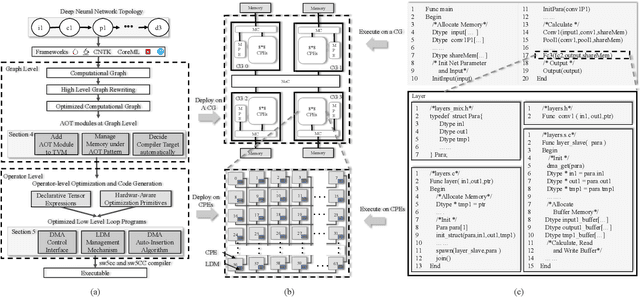
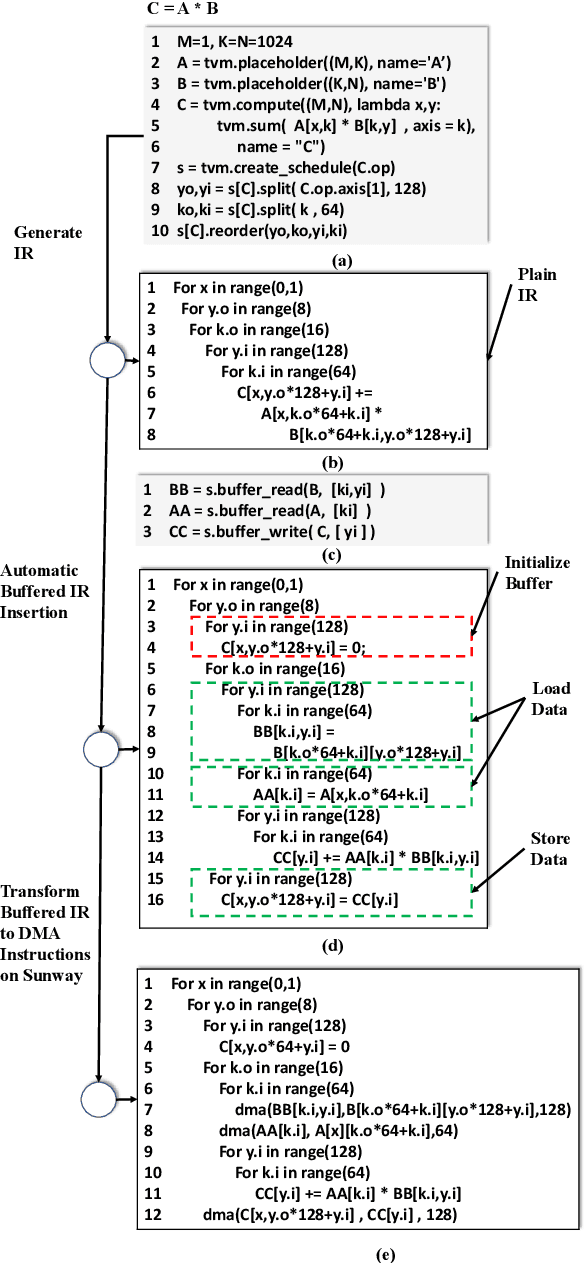

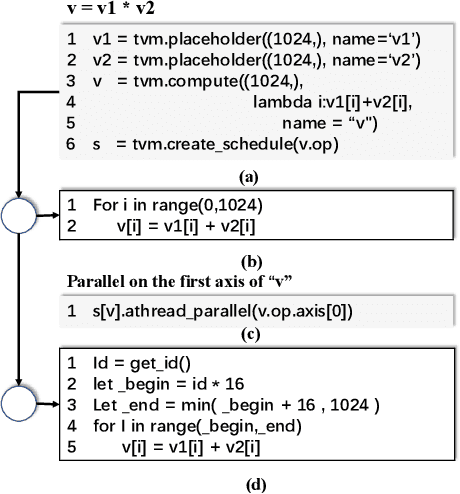
The flourish of deep learning frameworks and hardware platforms has been demanding an efficient compiler that can shield the diversity in both software and hardware in order to provide application portability. Among the exiting deep learning compilers, TVM is well known for its efficiency in code generation and optimization across diverse hardware devices. In the meanwhile, the Sunway many-core processor renders itself as a competitive candidate for its attractive computational power in both scientific and deep learning applications. This paper combines the trends in these two directions. Specifically, we propose swTVM that extends the original TVM to support ahead-of-time compilation for architecture requiring cross-compilation such as Sunway. In addition, we leverage the architecture features during the compilation such as core group for massive parallelism, DMA for high bandwidth memory transfer and local device memory for data locality, in order to generate efficient code for deep learning application on Sunway. The experimental results show the ability of swTVM to automatically generate code for various deep neural network models on Sunway. The performance of automatically generated code for AlexNet and VGG-19 by swTVM achieves 6.71x and 2.45x speedup on average than hand-optimized OpenACC implementations on convolution and fully connected layers respectively. This work is the first attempt from the compiler perspective to bridge the gap of deep learning and high performance architecture particularly with productivity and efficiency in mind. We would like to open source the implementation so that more people can embrace the power of deep learning compiler and Sunway many-core processor.