 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Text to Image Synthesis
Dec 10, 2024Fine-grained text to image synthesis involves generating images from texts that belong to different categories. In contrast to general text to image synthesis, in fine-grained synthesis there is high similarity between images of different subclasses, and there may be linguistic discrepancy among texts describing the same image. Recent Generative Adversarial Networks (GAN), such as the Recurrent Affine Transformation (RAT) GAN model, are able to synthesize clear and realistic images from texts. However, GAN models ignore fine-grained level information. In this paper we propose an approach that incorporates an auxiliary classifier in the discriminator and a contrastive learning method to improve the accuracy of fine-grained details in images synthesized by RAT GAN. The auxiliary classifier helps the discriminator classify the class of images, and helps the generator synthesize more accurate fine-grained images. The contrastive learning method minimizes the similarity between images from different subclasses and maximizes the similarity between images from the same subclass. We evaluate on several state-of-the-art methods on the commonly used CUB-200-2011 bird dataset and Oxford-102 flower dataset, and demonstrated superior performance.
Semi-supervised Domain Adaptation for Semantic Segmentation
Oct 20, 2021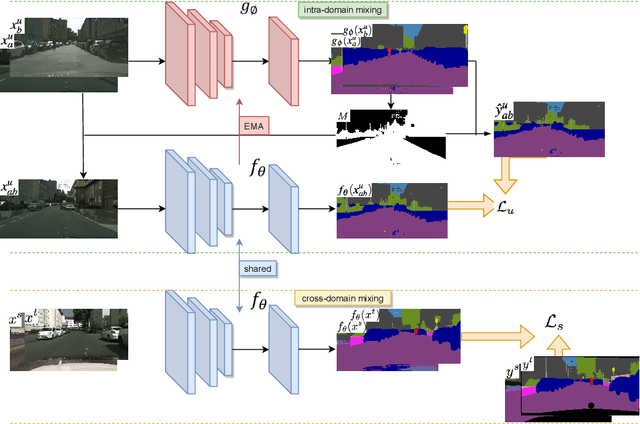
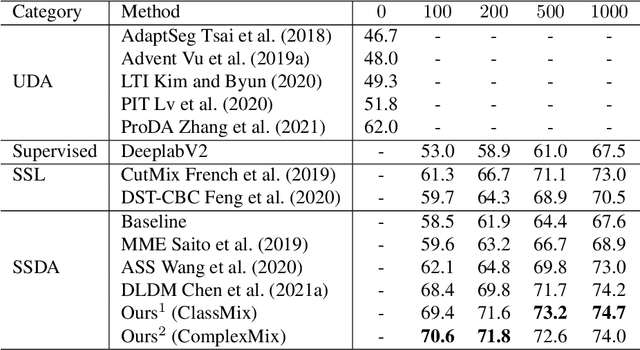
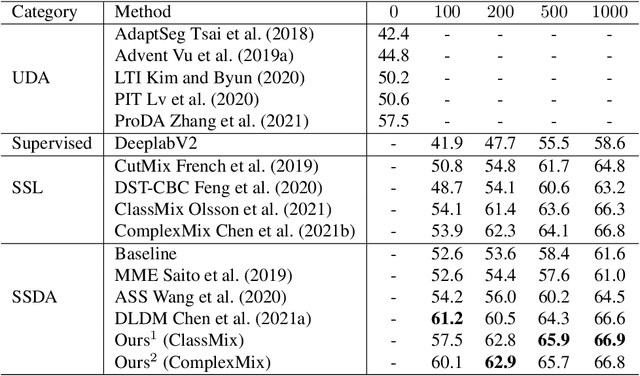

Deep learning approaches for semantic segmentation rely primarily on supervised learning approaches and require substantial efforts in producing pixel-level annotations. Further, such approaches may perform poorly when applied to unseen image domains. To cope with these limitations, both unsupervised domain adaptation (UDA) with full source supervision but without target supervision and semi-supervised learning (SSL) with partial supervision have been proposed. While such methods are effective at aligning different feature distributions, there is still a need to efficiently exploit unlabeled data to address the performance gap with respect to fully-supervised methods. In this paper we address semi-supervised domain adaptation (SSDA) for semantic segmentation, where a large amount of labeled source data as well as a small amount of labeled target data are available. We propose a novel and effective two-step semi-supervised dual-domain adaptation (SSDDA) approach to address both cross- and intra-domain gaps in semantic segmentation. The proposed framework is comprised of two mixing modules. First, we conduct a cross-domain adaptation via an image-level mixing strategy, which learns to align the distribution shift of features between the source data and target data. Second, intra-domain adaptation is achieved using a separate student-teacher network which is built to generate category-level data augmentation by mixing unlabeled target data in a way that respects predicted object boundaries. We demonstrate that the proposed approach outperforms state-of-the-art methods on two common synthetic-to-real semantic segmentation benchmarks. An extensive ablation study is provided to further validate the effectiveness of our approach.
Mask-based Data Augmentation for Semi-supervised Semantic Segmentation
Jan 25, 2021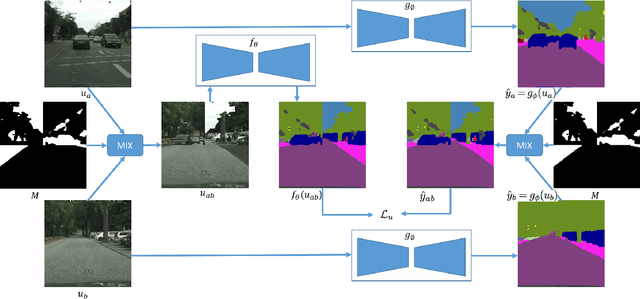
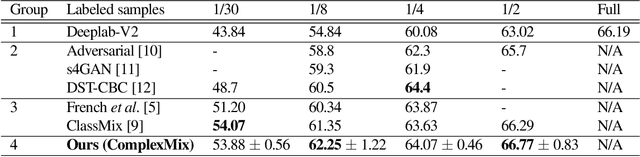
Semantic segmentation using convolutional neural networks (CNN) is a crucial component in image analysis. Training a CNN to perform semantic segmentation requires a large amount of labeled data, where the production of such labeled data is both costly and labor intensive. Semi-supervised learning algorithms address this issue by utilizing unlabeled data and so reduce the amount of labeled data needed for training. In particular, data augmentation techniques such as CutMix and ClassMix generate additional training data from existing labeled data. In this paper we propose a new approach for data augmentation, termed ComplexMix, which incorporates aspects of CutMix and ClassMix with improved performance. The proposed approach has the ability to control the complexity of the augmented data while attempting to be semantically-correct and address the tradeoff between complexity and correctness. The proposed ComplexMix approach is evaluated on a standard dataset for semantic segmentation and compared to other state-of-the-art techniques. Experimental results show that our method yields improvement over state-of-the-art methods on standard datasets for semantic image segmentation.
Domain Adaptation on Semantic Segmentation for Aerial Images
Dec 11, 2020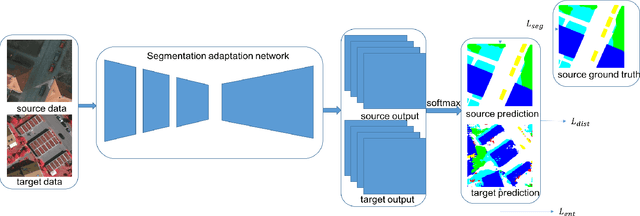
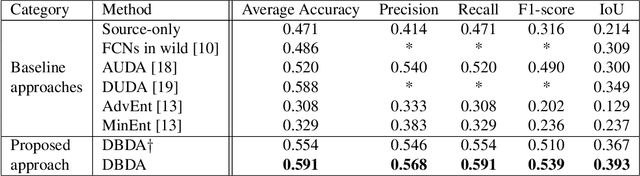

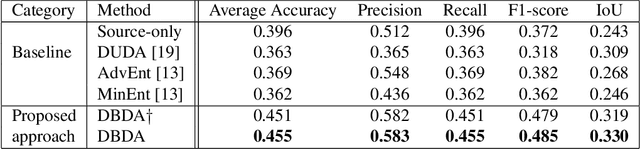
Semantic segmentation has achieved significant advances in recent years. While deep neural networks perform semantic segmentation well, their success rely on pixel level supervision which is expensive and time-consuming. Further, training using data from one domain may not generalize well to data from a new domain due to a domain gap between data distributions in the different domains. This domain gap is particularly evident in aerial images where visual appearance depends on the type of environment imaged, season, weather, and time of day when the environment is imaged. Subsequently, this distribution gap leads to severe accuracy loss when using a pretrained segmentation model to analyze new data with different characteristics. In this paper, we propose a novel unsupervised domain adaptation framework to address domain shift in the context of aerial semantic image segmentation. To this end, we solve the problem of domain shift by learn the soft label distribution difference between the source and target domains. Further, we also apply entropy minimization on the target domain to produce high-confident prediction rather than using high-confident prediction by pseudo-labeling. We demonstrate the effectiveness of our domain adaptation framework using the challenge image segmentation dataset of ISPRS, and show improvement over state-of-the-art methods in terms of various metrics.