 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Domain Adaptation for Semantic Segmentation
Paper and Code
Oct 20, 2021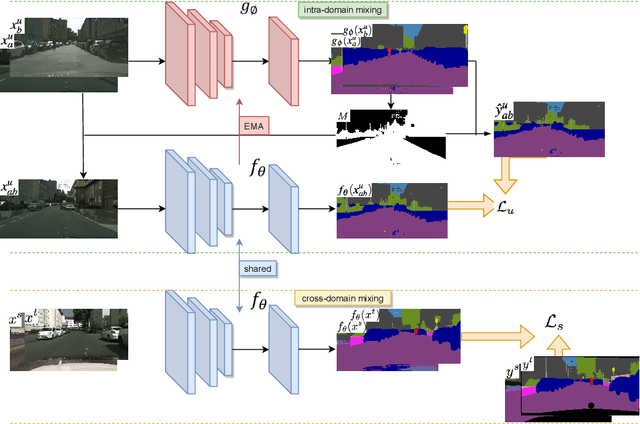
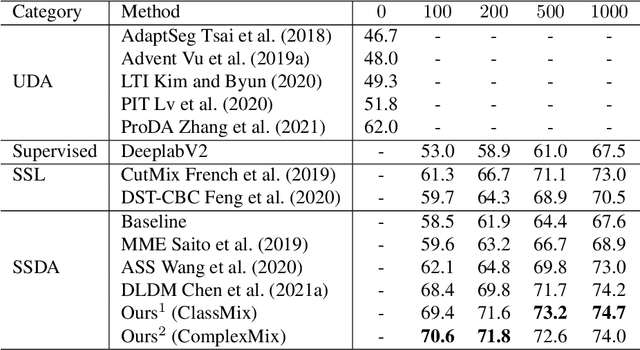
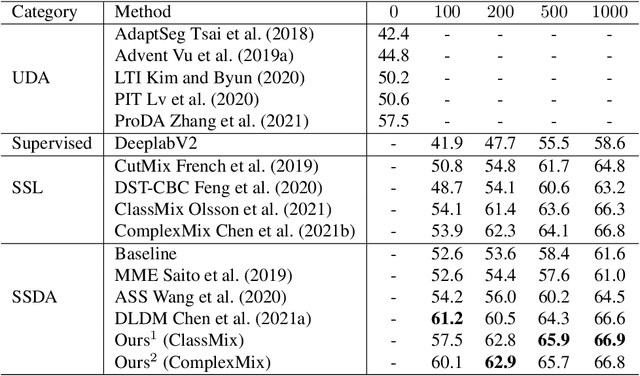

Deep learning approaches for semantic segmentation rely primarily on supervised learning approaches and require substantial efforts in producing pixel-level annotations. Further, such approaches may perform poorly when applied to unseen image domains. To cope with these limitations, both unsupervised domain adaptation (UDA) with full source supervision but without target supervision and semi-supervised learning (SSL) with partial supervision have been proposed. While such methods are effective at aligning different feature distributions, there is still a need to efficiently exploit unlabeled data to address the performance gap with respect to fully-supervised methods. In this paper we address semi-supervised domain adaptation (SSDA) for semantic segmentation, where a large amount of labeled source data as well as a small amount of labeled target data are available. We propose a novel and effective two-step semi-supervised dual-domain adaptation (SSDDA) approach to address both cross- and intra-domain gaps in semantic segmentation. The proposed framework is comprised of two mixing modules. First, we conduct a cross-domain adaptation via an image-level mixing strategy, which learns to align the distribution shift of features between the source data and target data. Second, intra-domain adaptation is achieved using a separate student-teacher network which is built to generate category-level data augmentation by mixing unlabeled target data in a way that respects predicted object boundaries. We demonstrate that the proposed approach outperforms state-of-the-art methods on two common synthetic-to-real semantic segmentation benchmarks. An extensive ablation study is provided to further validate the effectiveness of our approach.