 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive WGAN with loss change rate balancing
Paper and Code
Aug 28, 2020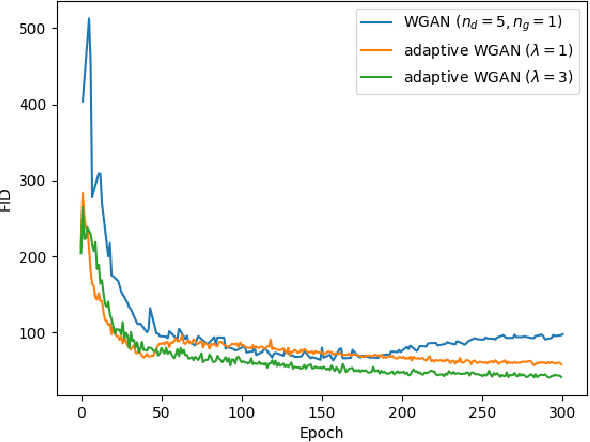
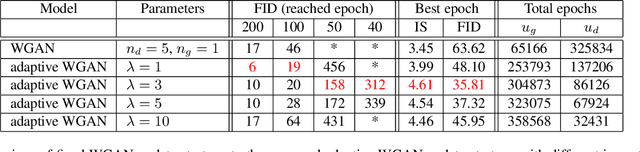
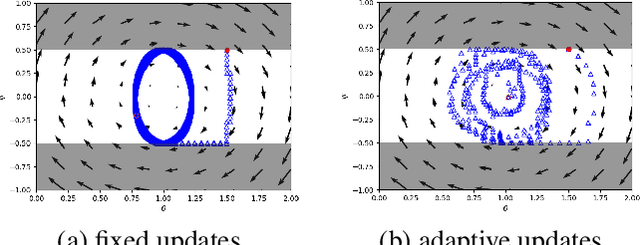
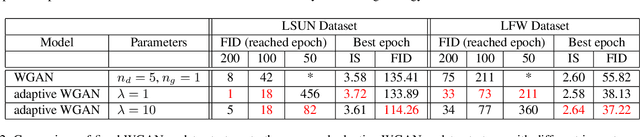
Optimizing the discriminator in Generative Adversarial Networks (GANs) to completion in the inner training loop is computationally prohibitive, and on finite datasets would result in overfitting. To address this, a common update strategy is to alternate between k optimization steps for the discriminator D and one optimization step for the generator G. This strategy is repeated in various GAN algorithms where k is selected empirically. In this paper, we show that this update strategy is not optimal in terms of accuracy and convergence speed, and propose a new update strategy for Wasserstein GANs (WGAN) and other GANs using the WGAN loss(e.g. WGAN-GP, Deblur GAN, and Super-resolution GAN). The proposed update strategy is based on a loss change ratio comparison of G and D. We demonstrate that the proposed strategy improves both convergence speed and accuracy.