 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multimodal Regex Synthesis with Complex Structures
Paper and Code
May 02, 2020
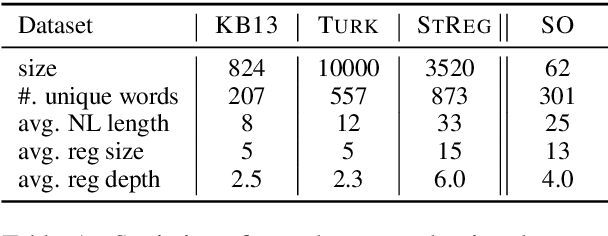


Existing datasets for regular expression (regex) generation from natural language are limited in complexity; compared to regex tasks that users post on StackOverflow, the regexes in these datasets are simple, and the language used to describe them is not diverse. We introduce StructuredRegex, a new regex synthesis dataset differing from prior ones in three aspects. First, to obtain structurally complex and realistic regexes, we generate the regexes using a probabilistic grammar with pre-defined macros observed from real-world StackOverflow posts. Second, to obtain linguistically diverse natural language descriptions, we show crowdworkers abstract depictions of the underlying regex and ask them to describe the pattern they see, rather than having them paraphrase synthetic language. Third, we augment each regex example with a collection of strings that are and are not matched by the ground truth regex, similar to how real users give examples. Our quantitative and qualitative analysis demonstrates the advantages of StructuredRegex over prior datasets. Further experimental results using various multimodal synthesis techniques highlight the challenge presented by our dataset, including non-local constraints and multi-modal inputs.