 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural language to SQL in low-code platforms
Aug 29, 2023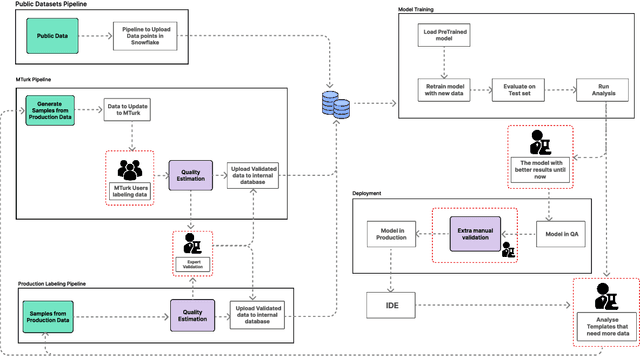
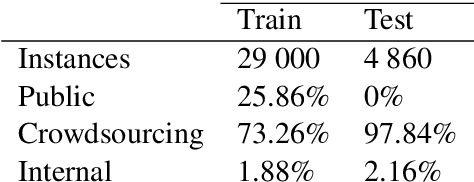
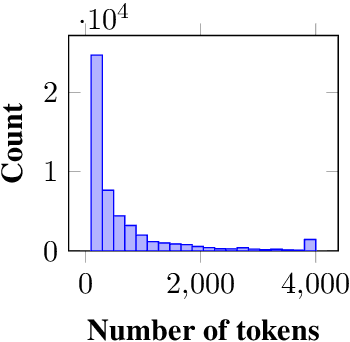
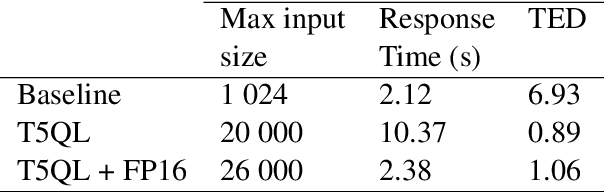
One of the developers' biggest challenges in low-code platforms is retrieving data from a database using SQL queries. Here, we propose a pipeline allowing developers to write natural language (NL) to retrieve data. In this study, we collect, label, and validate data covering the SQL queries most often performed by OutSystems users. We use that data to train a NL model that generates SQL. Alongside this, we describe the entire pipeline, which comprises a feedback loop that allows us to quickly collect production data and use it to retrain our SQL generation model. Using crowd-sourcing, we collect 26k NL and SQL pairs and obtain an additional 1k pairs from production data. Finally, we develop a UI that allows developers to input a NL query in a prompt and receive a user-friendly representation of the resulting SQL query. We use A/B testing to compare four different models in production and observe a 240% improvement in terms of adoption of the feature, 220% in terms of engagement rate, and a 90% decrease in failure rate when compared against the first model that we put into production, showcasing the effectiveness of our pipeline in continuously improving our feature.
Learning Supervised Topic Models for Classification and Regression from Crowds
Aug 17, 2018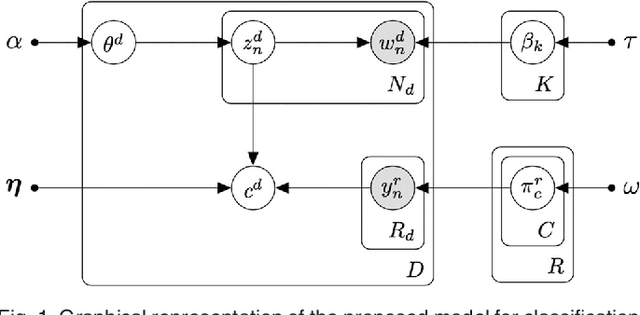

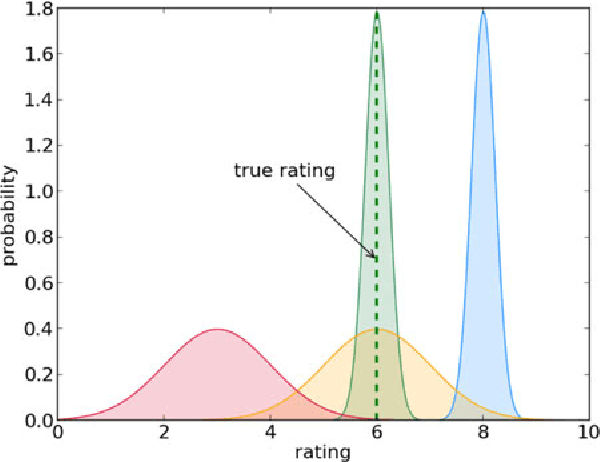

The growing need to analyze large collections of documents has led to great developments in topic modeling. Since documents are frequently associated with other related variables, such as labels or ratings, much interest has been placed on supervised topic models. However, the nature of most annotation tasks, prone to ambiguity and noise, often with high volumes of documents, deem learning under a single-annotator assumption unrealistic or unpractical for most real-world applications. In this article, we propose two supervised topic models, one for classification and another for regression problems, which account for the heterogeneity and biases among different annotators that are encountered in practice when learning from crowds. We develop an efficient stochastic variational inference algorithm that is able to scale to very large datasets, and we empirically demonstrate the advantages of the proposed model over state-of-the-art approaches.
* 14 pages