 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Frame Extraction: A Novel Approach Through Frame Similarity and Surgical Tool Tracking for Video Segmentation
Jan 19, 2025
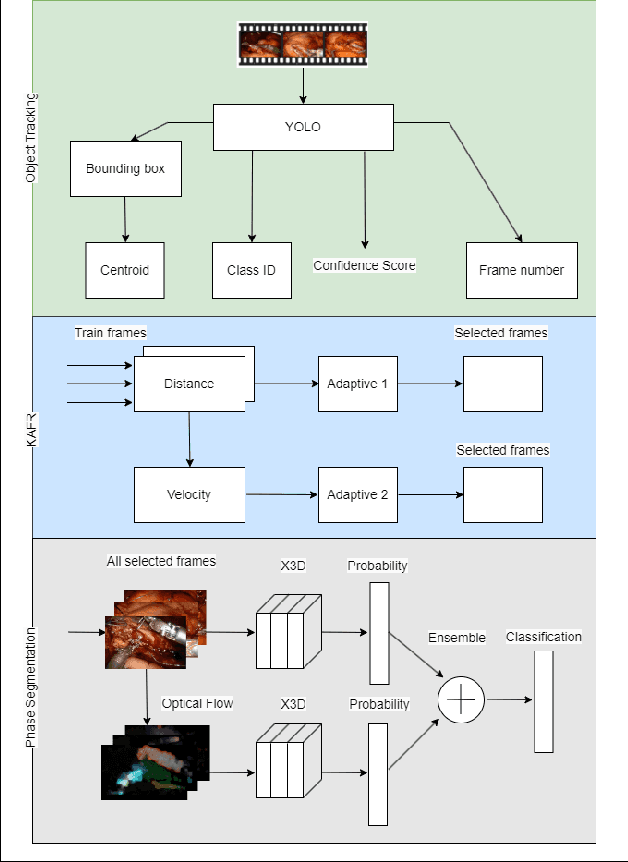

The interest in leveraging Artificial Intelligence (AI) for surgical procedures to automate analysis has witnessed a significant surge in recent years. One of the primary tools for recording surgical procedures and conducting subsequent analyses, such as performance assessment, is through videos. However, these operative videos tend to be notably lengthy compared to other fields, spanning from thirty minutes to several hours, which poses a challenge for AI models to effectively learn from them. Despite this challenge, the foreseeable increase in the volume of such videos in the near future necessitates the development and implementation of innovative techniques to tackle this issue effectively. In this article, we propose a novel technique called Kinematics Adaptive Frame Recognition (KAFR) that can efficiently eliminate redundant frames to reduce dataset size and computation time while retaining useful frames to improve accuracy. Specifically, we compute the similarity between consecutive frames by tracking the movement of surgical tools. Our approach follows these steps: i) Tracking phase: a YOLOv8 model is utilized to detect tools presented in the scene, ii) Similarity phase: Similarities between consecutive frames are computed by estimating variation in the spatial positions and velocities of the tools, iii) Classification phase: A X3D CNN is trained to classify segmentation. We evaluate the effectiveness of our approach by analyzing datasets obtained through retrospective reviews of cases at two referral centers. The Gastrojejunostomy (GJ) dataset covers procedures performed between 2017 to 2021, while the Pancreaticojejunostomy (PJ) dataset spans from 2011 to 2022 at the same centers. By adaptively selecting relevant frames, we achieve a tenfold reduction in the number of frames while improving accuracy by 4.32% (from 0.749 to 0.7814).
The Significance of Latent Data Divergence in Predicting System Degradation
Jun 13, 2024
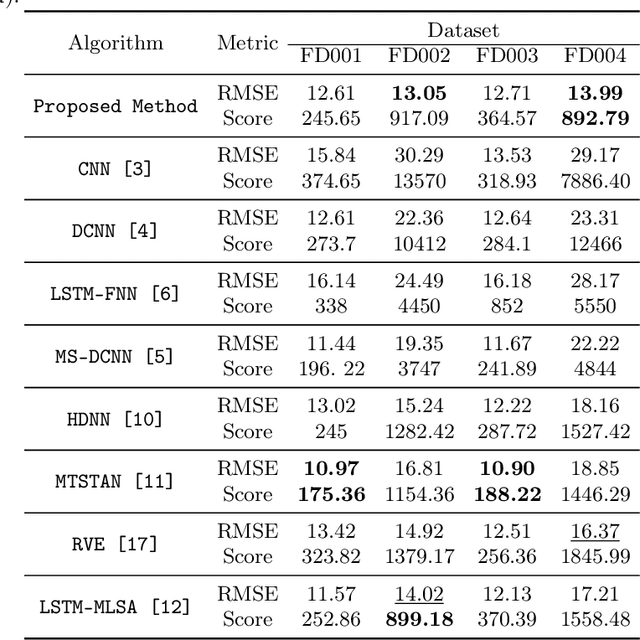
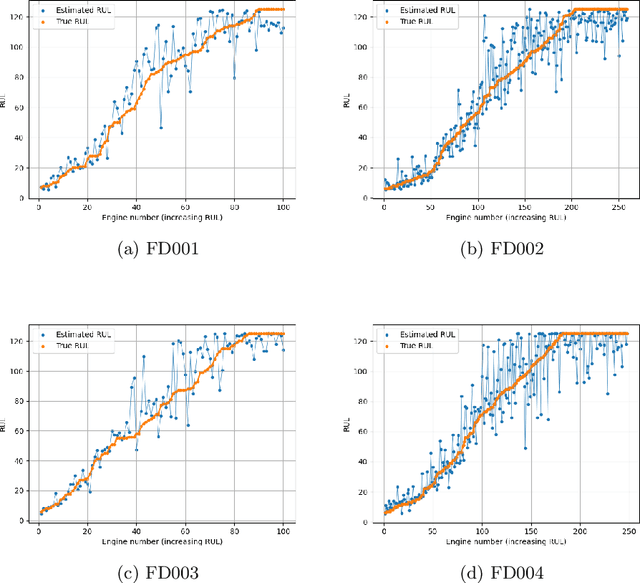
Condition-Based Maintenance is pivotal in enabling the early detection of potential failures in engineering systems, where precise prediction of the Remaining Useful Life is essential for effective maintenance and operation. However, a predominant focus in the field centers on predicting the Remaining Useful Life using unprocessed or minimally processed data, frequently neglecting the intricate dynamics inherent in the dataset. In this work we introduce a novel methodology grounded in the analysis of statistical similarity within latent data from system components. Leveraging a specifically designed architecture based on a Vector Quantized Variational Autoencoder, we create a sequence of discrete vectors which is used to estimate system-specific priors. We infer the similarity between systems by evaluating the divergence of these priors, offering a nuanced understanding of individual system behaviors. The efficacy of our approach is demonstrated through experiments on the NASA commercial modular aero-propulsion system simulation (C-MAPSS) dataset. Our validation not only underscores the potential of our method in advancing the study of latent statistical divergence but also demonstrates its superiority over existing techniques.
Video Action Recognition Collaborative Learning with Dynamics via PSO-ConvNet Transformer
Feb 17, 2023Human Action Recognition (HAR) involves the task of categorizing actions present in video sequences. Although it presents interesting problems, it remains one of the most challenging domains in pattern recognition. Convolutional Neural Networks (ConvNets) have demonstrated exceptional success in image recognition and related areas. However, these advanced techniques are not always directly applicable to HAR, as the consideration of temporal features is crucial. In this paper, we present a dynamic PSO-ConvNet model for learning actions in video, drawing on our recent research in image recognition. Our methods are based on a framework where the weight vector of each neural network serves as the position of a particle in phase space, and particles exchange their current weight vectors and gradient estimates of the Loss function. We extend the approach to video by integrating a ConvNet with state-of-the-art temporal methods such as Transformer and Recurrent Neural Networks. The results reveal substantial advancements, with improvements of up to 9% on UCF-101 dataset. The code is available at https://github.com/leonlha/Video-Action-Recognition-via-PSO-ConvNet-Transformer-Collaborative-Learning-with-Dynamics.
Action Recognition for American Sign Language
May 20, 2022
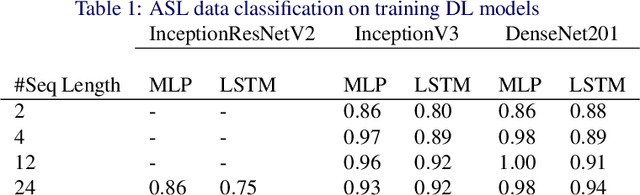
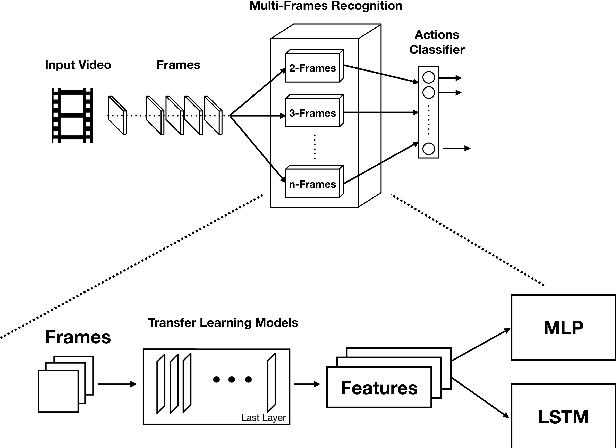
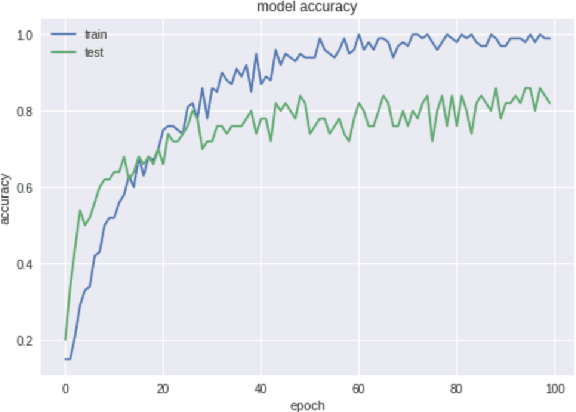
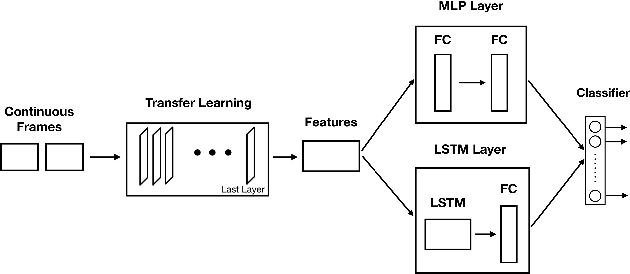
In this research, we present our findings to recognize American Sign Language from series of hand gestures. While most researches in literature focus only on static handshapes, our work target dynamic hand gestures. Since dynamic signs dataset are very few, we collect an initial dataset of 150 videos for 10 signs and an extension of 225 videos for 15 signs. We apply transfer learning models in combination with deep neural networks and background subtraction for videos in different temporal settings. Our primarily results show that we can get an accuracy of $0.86$ and $0.71$ using DenseNet201, LSTM with video sequence of 12 frames accordingly.
* 2 pages
PSO-Convolutional Neural Networks with Heterogeneous Learning Rate
May 20, 2022

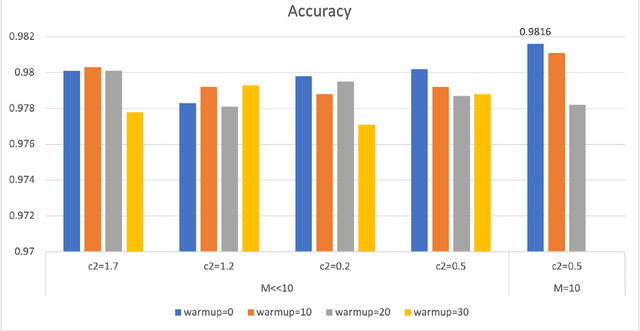

Convolutional Neural Networks (ConvNets) have been candidly deployed in the scope of computer vision and related fields. Nevertheless, the dynamics of training of these neural networks lie still elusive: it is hard and computationally expensive to train them. A myriad of architectures and training strategies have been proposed to overcome this challenge and address several problems in image processing such as speech, image and action recognition as well as object detection. In this article, we propose a novel Particle Swarm Optimization (PSO) based training for ConvNets. In such framework, the vector of weights of each ConvNet is typically cast as the position of a particle in phase space whereby PSO collaborative dynamics intertwines with Stochastic Gradient Descent (SGD) in order to boost training performance and generalization. Our approach goes as follows: i) [warm-up phase] each ConvNet is trained independently via SGD; ii) [collaborative phase] ConvNets share among themselves their current vector of weights (or particle-position) along with their gradient estimates of the Loss function. Distinct step sizes are coined by distinct ConvNets. By properly blending ConvNets with large (possibly random) step-sizes along with more conservative ones, we propose an algorithm with competitive performance with respect to other PSO-based approaches on Cifar-10 (accuracy of 98.31%). These accuracy levels are obtained by resorting to only four ConvNets -- such results are expected to scale with the number of collaborative ConvNets accordingly. We make our source codes available for download https://github.com/leonlha/PSO-ConvNet-Dynamics.
An Improvement for Capsule Networks using Depthwise Separable Convolution
Jul 30, 2020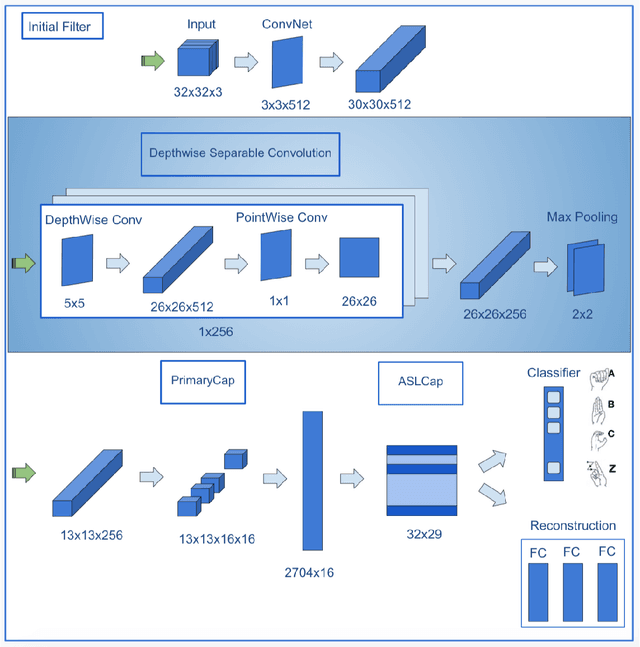
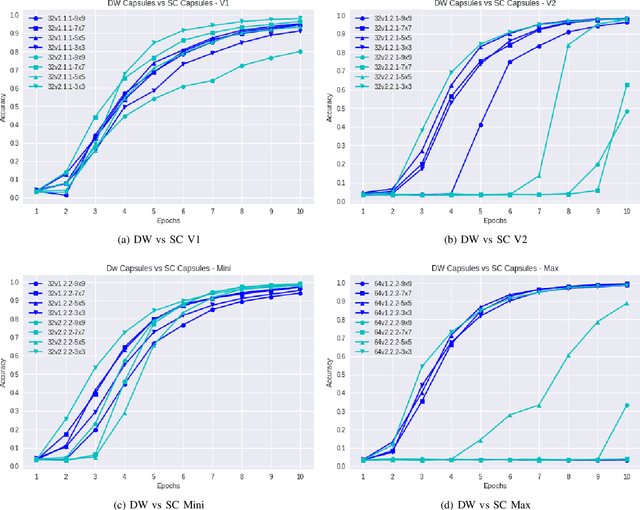
Capsule Networks face a critical problem in computer vision in the sense that the image background can challenge its performance, although they learn very well on training data. In this work, we propose to improve Capsule Networks' architecture by replacing the Standard Convolution with a Depthwise Separable Convolution. This new design significantly reduces the model's total parameters while increases stability and offers competitive accuracy. In addition, the proposed model on $64\times64$ pixel images outperforms standard models on $32\times32$ and $64\times64$ pixel images. Moreover, we empirically evaluate these models with Deep Learning architectures using state-of-the-art Transfer Learning networks such as Inception V3 and MobileNet V1. The results show that Capsule Networks perform equivalently against Deep Learning models. To the best of our knowledge, we believe that this is the first work on the integration of Depthwise Separable Convolution into Capsule Networks.
* 6 pages
Rethinking Recurrent Neural Networks and other Improvements for Image Classification
Jul 30, 2020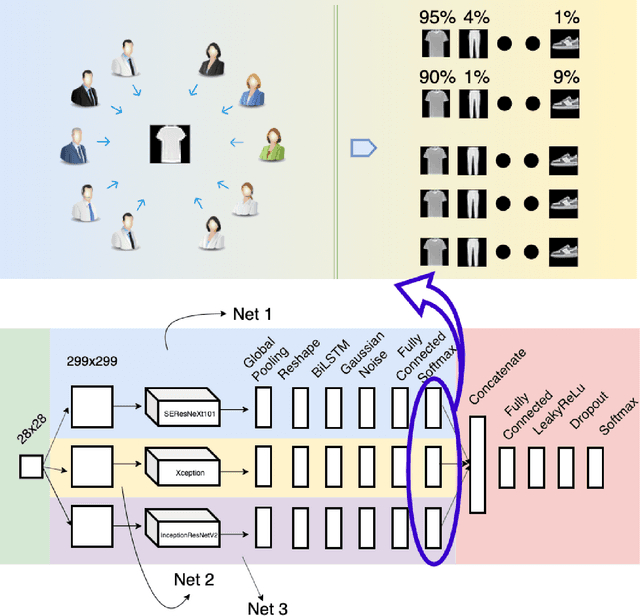
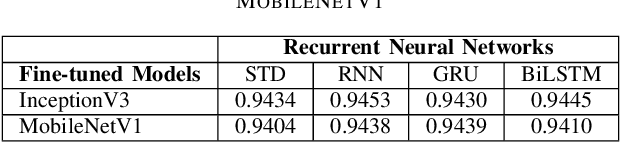
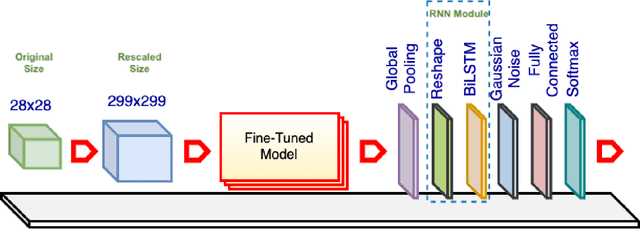
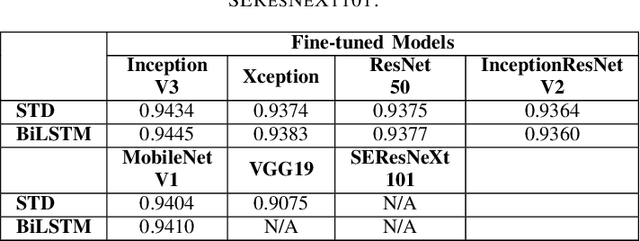
For a long history of Machine Learning which dates back to several decades, Recurrent Neural Networks (RNNs) have been mainly used for sequential data and time series or generally 1D information. Even in some rare researches on 2D images, the networks merely learn and generate data sequentially rather than for recognition of images. In this research, we propose to integrate RNN as an additional layer in designing image recognition's models. Moreover, we develop End-to-End Ensemble Multi-models that are able to learn experts' predictions from several models. Besides, we extend training strategy and softmax pruning which overall leads our designs to perform comparably to top models on several datasets. The source code of the methods provided in this article is available in https://github.com/leonlha/e2e-3m and http://nguyenhuuphong.me.
Evolution of Scikit-Learn Pipelines with Dynamic Structured Grammatical Evolution
Apr 01, 2020
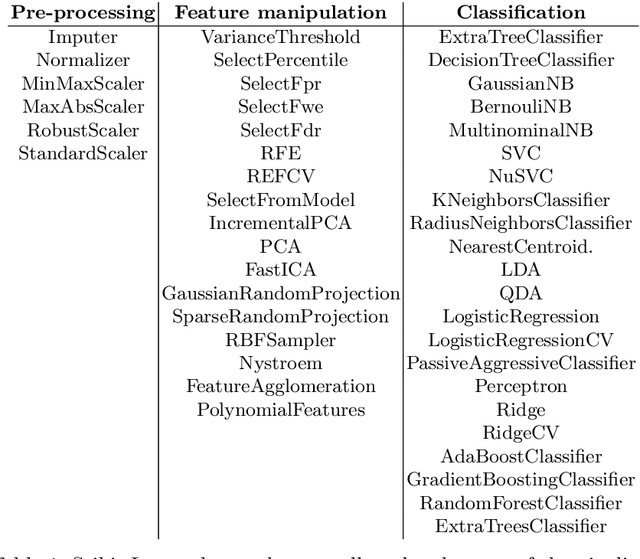

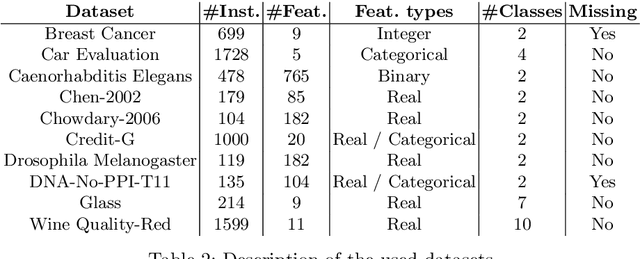
The deployment of Machine Learning (ML) models is a difficult and time-consuming job that comprises a series of sequential and correlated tasks that go from the data pre-processing, and the design and extraction of features, to the choice of the ML algorithm and its parameterisation. The task is even more challenging considering that the design of features is in many cases problem specific, and thus requires domain-expertise. To overcome these limitations Automated Machine Learning (AutoML) methods seek to automate, with few or no human-intervention, the design of pipelines, i.e., automate the selection of the sequence of methods that have to be applied to the raw data. These methods have the potential to enable non-expert users to use ML, and provide expert users with solutions that they would unlikely consider. In particular, this paper describes AutoML-DSGE - a novel grammar-based framework that adapts Dynamic Structured Grammatical Evolution (DSGE) to the evolution of Scikit-Learn classification pipelines. The experimental results include comparing AutoML-DSGE to another grammar-based AutoML framework, Resilient ClassificationPipeline Evolution (RECIPE), and show that the average performance of the classification pipelines generated by AutoML-DSGE is always superior to the average performance of RECIPE; the differences are statistically significant in 3 out of the 10 used datasets.
Incremental Evolution and Development of Deep Artificial Neural Networks
Apr 01, 2020
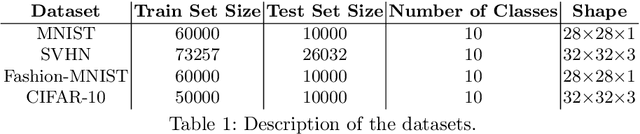
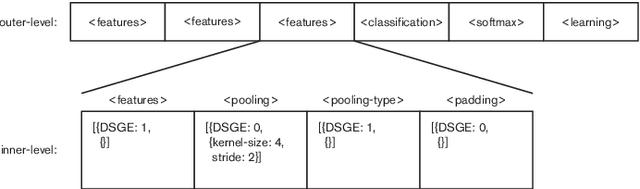
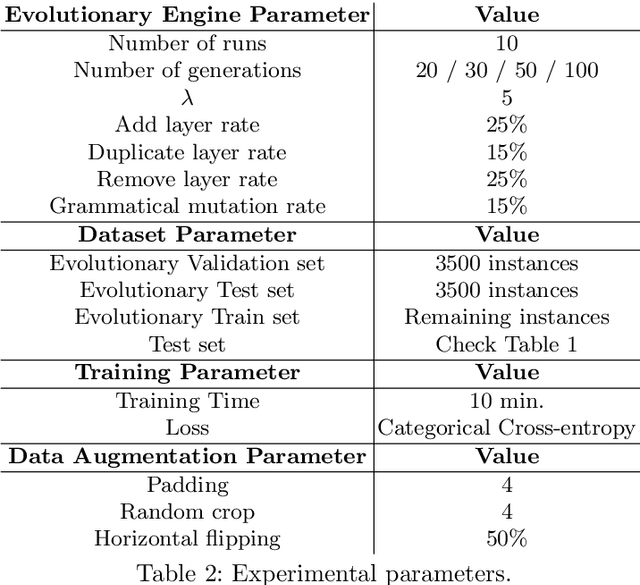
NeuroEvolution (NE) methods are known for applying Evolutionary Computation to the optimisation of Artificial Neural Networks(ANNs). Despite aiding non-expert users to design and train ANNs, the vast majority of NE approaches disregard the knowledge that is gathered when solving other tasks, i.e., evolution starts from scratch for each problem, ultimately delaying the evolutionary process. To overcome this drawback, we extend Fast Deep Evolutionary Network Structured Representation (Fast-DENSER) to incremental development. We hypothesise that by transferring the knowledge gained from previous tasks we can attain superior results and speedup evolution. The results show that the average performance of the models generated by incremental development is statistically superior to the non-incremental average performance. In case the number of evaluations performed by incremental development is smaller than the performed by non-incremental development the attained results are similar in performance, which indicates that incremental development speeds up evolution. Lastly, the models generated using incremental development generalise better, and thus, without further evolution, report a superior performance on unseen problems.
Fast-DENSER++: Evolving Fully-Trained Deep Artificial Neural Networks
May 08, 2019
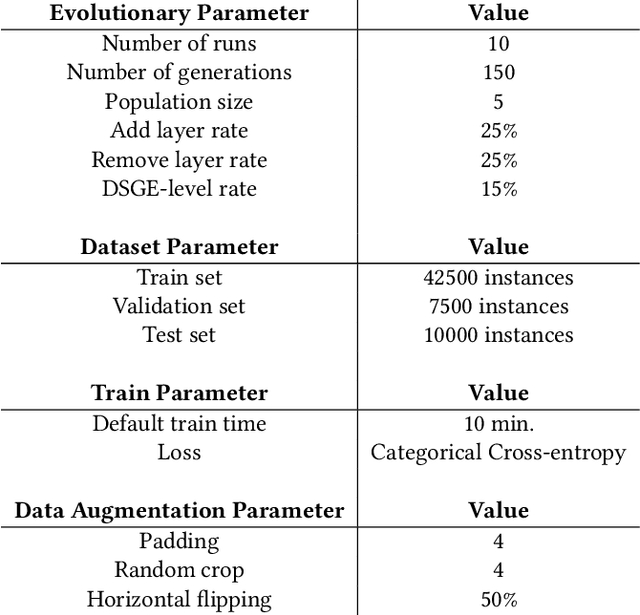
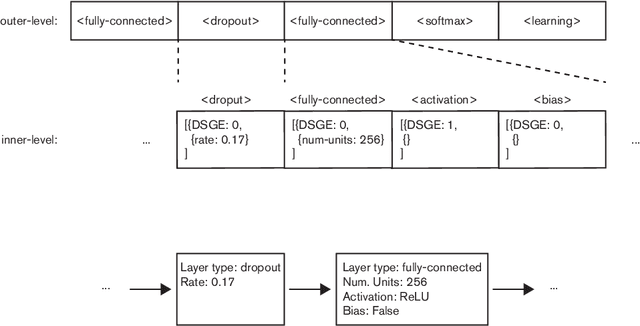

This paper proposes a new extension to Deep Evolutionary Network Structured Evolution (DENSER), called Fast-DENSER++ (F-DENSER++). The vast majority of NeuroEvolution methods that optimise Deep Artificial Neural Networks (DANNs) only evaluate the candidate solutions for a fixed amount of epochs; this makes it difficult to effectively assess the learning strategy, and requires the best generated network to be further trained after evolution. F-DENSER++ enables the training time of the candidate solutions to grow continuously as necessary, i.e., in the initial generations the candidate solutions are trained for shorter times, and as generations proceed it is expected that longer training cycles enable better performances. Consequently, the models discovered by F-DENSER++ are fully-trained DANNs, and are ready for deployment after evolution, without the need for further training. The results demonstrate the ability of F-DENSER++ to effectively generate fully-trained DANNs; by the end of evolution, whilst the average performance of the models generated by F-DENSER++ is of 88.73%, the performance of the models generated by the previous version of DENSER (Fast-DENSER) is 86.91% (statistically significant), which increases to 87.76% when allowed to train for longer.