 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Action Recognition Collaborative Learning with Dynamics via PSO-ConvNet Transformer
Feb 17, 2023Human Action Recognition (HAR) involves the task of categorizing actions present in video sequences. Although it presents interesting problems, it remains one of the most challenging domains in pattern recognition. Convolutional Neural Networks (ConvNets) have demonstrated exceptional success in image recognition and related areas. However, these advanced techniques are not always directly applicable to HAR, as the consideration of temporal features is crucial. In this paper, we present a dynamic PSO-ConvNet model for learning actions in video, drawing on our recent research in image recognition. Our methods are based on a framework where the weight vector of each neural network serves as the position of a particle in phase space, and particles exchange their current weight vectors and gradient estimates of the Loss function. We extend the approach to video by integrating a ConvNet with state-of-the-art temporal methods such as Transformer and Recurrent Neural Networks. The results reveal substantial advancements, with improvements of up to 9% on UCF-101 dataset. The code is available at https://github.com/leonlha/Video-Action-Recognition-via-PSO-ConvNet-Transformer-Collaborative-Learning-with-Dynamics.
Action Recognition for American Sign Language
May 20, 2022
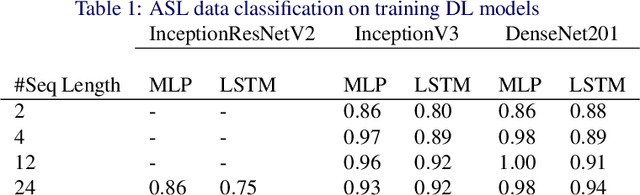
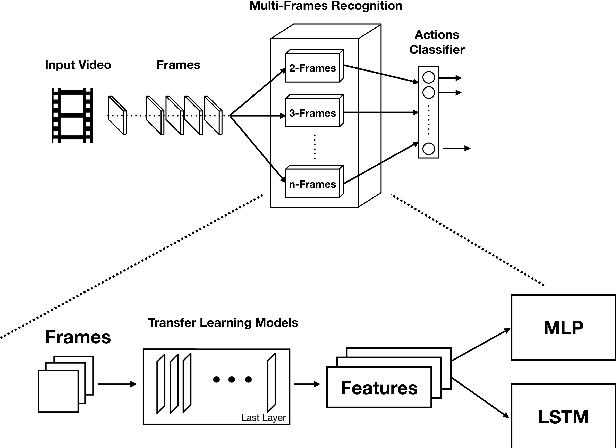
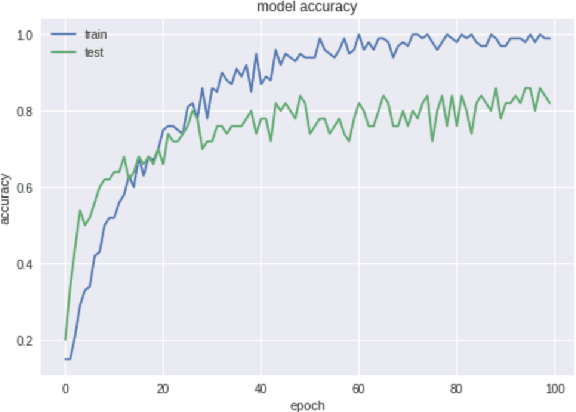
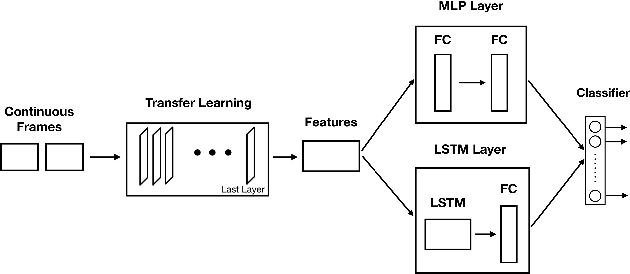
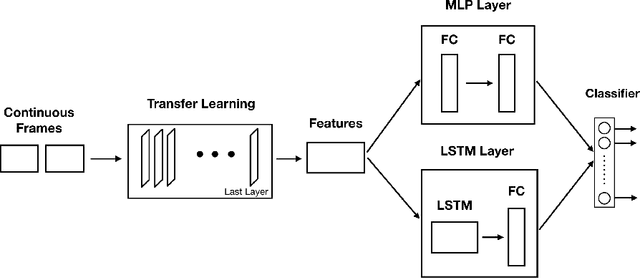
In this research, we present our findings to recognize American Sign Language from series of hand gestures. While most researches in literature focus only on static handshapes, our work target dynamic hand gestures. Since dynamic signs dataset are very few, we collect an initial dataset of 150 videos for 10 signs and an extension of 225 videos for 15 signs. We apply transfer learning models in combination with deep neural networks and background subtraction for videos in different temporal settings. Our primarily results show that we can get an accuracy of $0.86$ and $0.71$ using DenseNet201, LSTM with video sequence of 12 frames accordingly.
* 2 pages
PSO-Convolutional Neural Networks with Heterogeneous Learning Rate
May 20, 2022

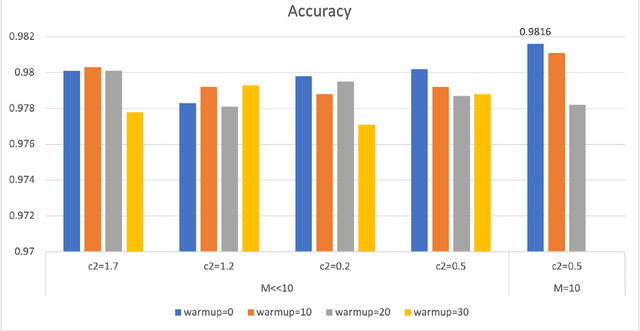

Convolutional Neural Networks (ConvNets) have been candidly deployed in the scope of computer vision and related fields. Nevertheless, the dynamics of training of these neural networks lie still elusive: it is hard and computationally expensive to train them. A myriad of architectures and training strategies have been proposed to overcome this challenge and address several problems in image processing such as speech, image and action recognition as well as object detection. In this article, we propose a novel Particle Swarm Optimization (PSO) based training for ConvNets. In such framework, the vector of weights of each ConvNet is typically cast as the position of a particle in phase space whereby PSO collaborative dynamics intertwines with Stochastic Gradient Descent (SGD) in order to boost training performance and generalization. Our approach goes as follows: i) [warm-up phase] each ConvNet is trained independently via SGD; ii) [collaborative phase] ConvNets share among themselves their current vector of weights (or particle-position) along with their gradient estimates of the Loss function. Distinct step sizes are coined by distinct ConvNets. By properly blending ConvNets with large (possibly random) step-sizes along with more conservative ones, we propose an algorithm with competitive performance with respect to other PSO-based approaches on Cifar-10 (accuracy of 98.31%). These accuracy levels are obtained by resorting to only four ConvNets -- such results are expected to scale with the number of collaborative ConvNets accordingly. We make our source codes available for download https://github.com/leonlha/PSO-ConvNet-Dynamics.
An Improvement for Capsule Networks using Depthwise Separable Convolution
Jul 30, 2020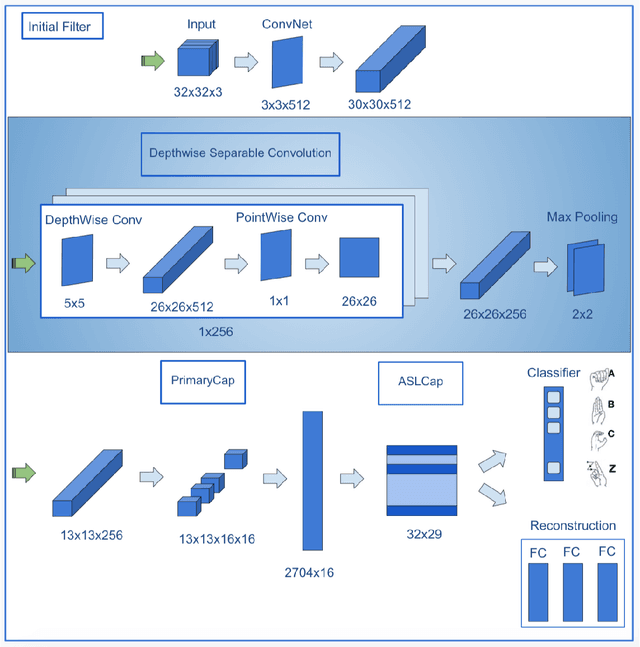
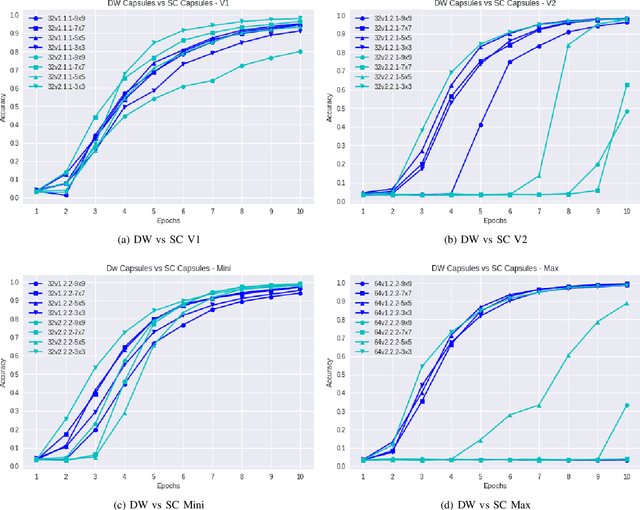
Capsule Networks face a critical problem in computer vision in the sense that the image background can challenge its performance, although they learn very well on training data. In this work, we propose to improve Capsule Networks' architecture by replacing the Standard Convolution with a Depthwise Separable Convolution. This new design significantly reduces the model's total parameters while increases stability and offers competitive accuracy. In addition, the proposed model on $64\times64$ pixel images outperforms standard models on $32\times32$ and $64\times64$ pixel images. Moreover, we empirically evaluate these models with Deep Learning architectures using state-of-the-art Transfer Learning networks such as Inception V3 and MobileNet V1. The results show that Capsule Networks perform equivalently against Deep Learning models. To the best of our knowledge, we believe that this is the first work on the integration of Depthwise Separable Convolution into Capsule Networks.
* 6 pages
Rethinking Recurrent Neural Networks and other Improvements for Image Classification
Jul 30, 2020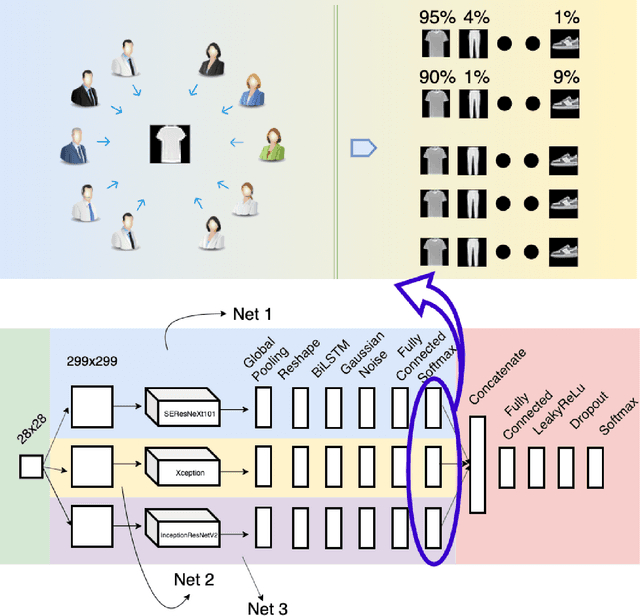
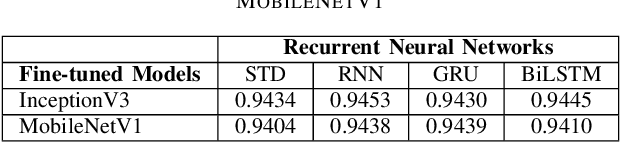
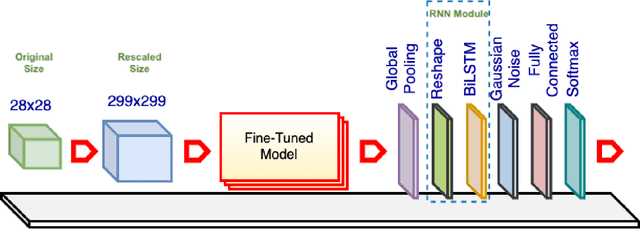
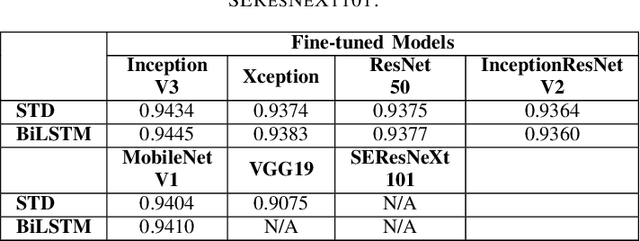
For a long history of Machine Learning which dates back to several decades, Recurrent Neural Networks (RNNs) have been mainly used for sequential data and time series or generally 1D information. Even in some rare researches on 2D images, the networks merely learn and generate data sequentially rather than for recognition of images. In this research, we propose to integrate RNN as an additional layer in designing image recognition's models. Moreover, we develop End-to-End Ensemble Multi-models that are able to learn experts' predictions from several models. Besides, we extend training strategy and softmax pruning which overall leads our designs to perform comparably to top models on several datasets. The source code of the methods provided in this article is available in https://github.com/leonlha/e2e-3m and http://nguyenhuuphong.me.
Advanced Capsule Networks via Context Awareness
Apr 02, 2019
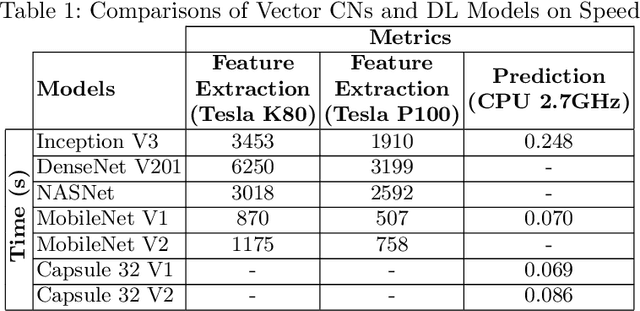
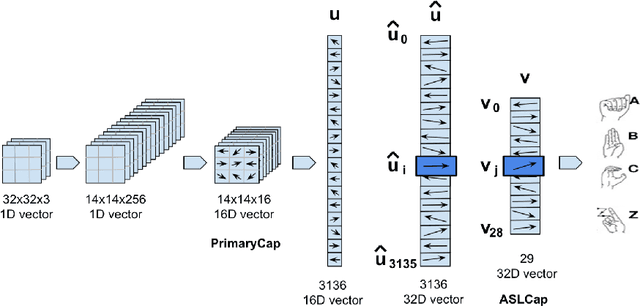
Capsule Networks (CN) offer new architectures for Deep Learning (DL) community. Though its effectiveness has been demonstrated in MNIST and smallNORB datasets, the networks still face challenges in other datasets for images with distinct contexts. In this research, we improve the design of CN (Vector version) namely we expand more Pooling layers to filter image backgrounds and increase Reconstruction layers to make better image restoration. Additionally, we perform experiments to compare accuracy and speed of CN versus DL models. In DL models, we utilize Inception V3 and DenseNet V201 for powerful computers besides NASNet, MobileNet V1 and MobileNet V2 for small and embedded devices. We evaluate our models on a fingerspelling alphabet dataset from American Sign Language (ASL). The results show that CNs perform comparably to DL models while dramatically reducing training time. We also make a demonstration and give a link for the purpose of illustration.
Offline and Online Deep Learning for Image Recognition
Mar 18, 2019
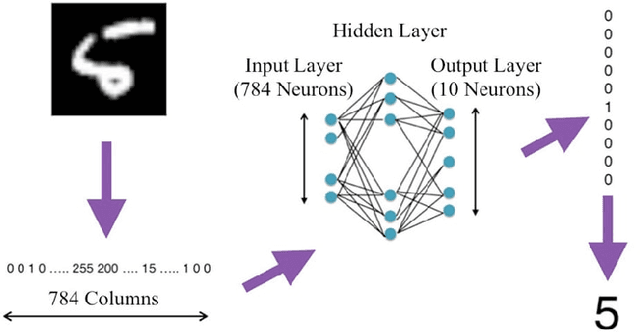
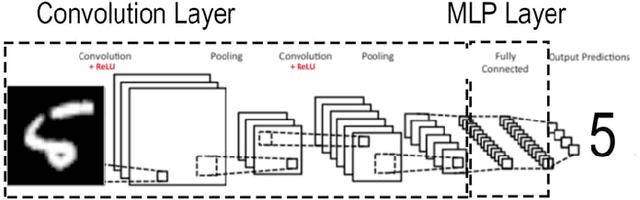
Image recognition using Deep Learning has been evolved for decades though advances in the field through different settings is still a challenge. In this paper, we present our findings in searching for better image classifiers in offline and online environments. We resort to Convolutional Neural Network and its variations of fully connected Multi-layer Perceptron. Though still preliminary, these results are encouraging and may provide a better understanding about the field and directions toward future works.
* 5 pages