 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Capsule Networks via Context Awareness
Paper and Code
Apr 02, 2019
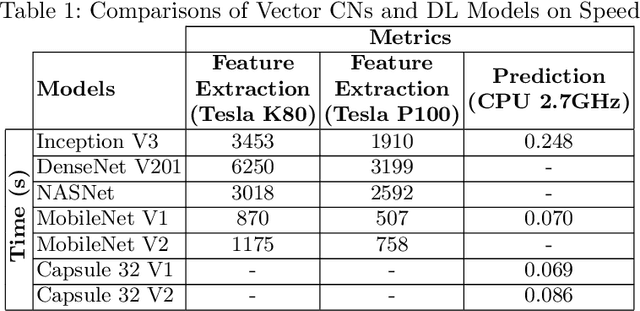
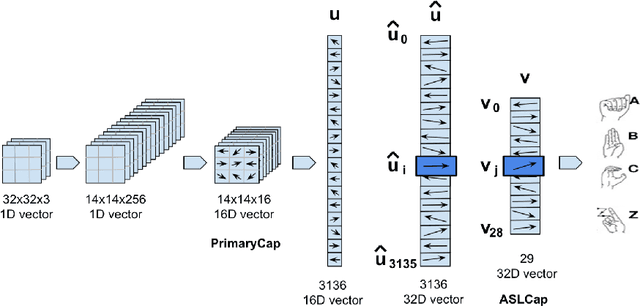
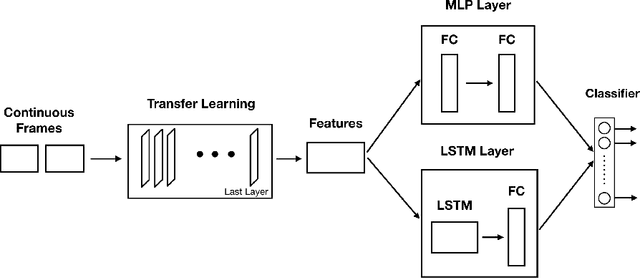
Capsule Networks (CN) offer new architectures for Deep Learning (DL) community. Though its effectiveness has been demonstrated in MNIST and smallNORB datasets, the networks still face challenges in other datasets for images with distinct contexts. In this research, we improve the design of CN (Vector version) namely we expand more Pooling layers to filter image backgrounds and increase Reconstruction layers to make better image restoration. Additionally, we perform experiments to compare accuracy and speed of CN versus DL models. In DL models, we utilize Inception V3 and DenseNet V201 for powerful computers besides NASNet, MobileNet V1 and MobileNet V2 for small and embedded devices. We evaluate our models on a fingerspelling alphabet dataset from American Sign Language (ASL). The results show that CNs perform comparably to DL models while dramatically reducing training time. We also make a demonstration and give a link for the purpose of illustration.